
AI
原创 深夜一声巨响!俄军“钢铁巨兽”登场,万炮齐开炸红乌克兰半边天
 hqy 发表于2025-02-24 浏览20 评论0
hqy 发表于2025-02-24 浏览20 评论0

日前,俄美代表团在沙特利雅得展开的会谈,虽然只是初步接触,但其背后的象征意义不容小觑——这是两国关系从拜登执政时期的“冰河期”向可能的解冻迈出的关键一步。但值得注意的是,俄乌前线状况,可并没有因此而有所缓和。
AI
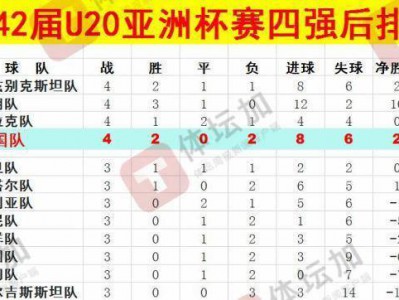
体坛:U20国青最终排名本届U20亚洲杯第八,比上一届下降一位
hqy 发表于2025-02-24 浏览22 评论0

AI
俄外长:俄方愿与乌、欧谈判,乌不加入北约是“先决条件”
hqy 发表于2025-02-24 浏览27 评论0

AI
探索深度学习与自然语言处理:常见的微调策略揭秘史前文明?撒哈拉沙漠里的神秘“巨眼”,到底是什么来头?
hqy 发表于2025-02-24 浏览33 评论0
在深度学习与自然语言处理领域,常见的微调方法主要包含以下几种:
Fine-tuning(全参数微调):作为最传统的微调方法,它需要对预训练模型中的所有参数进行更新,以此来适应特定任务。该方法通常能取得最佳性能,不过其计算成本相对较高。 Prompt-tuning(提示微调):此方法通过精心设计特定的输入提示(prompts),而非修改模型权重,来使模型适应下游任务。这样能使模型在计算成本较低的情况下适应各类任务。 Parameter-efficient fine-tuning(参数高效微调):这组方法主要是通过仅训练模型参数的一个子集或者新添加的一组参数,以此减少所需的参数数量以及计算资源。对于资源有限的环境而言,这些技术意义重大。 Adapter Training(适配器训练):适配器是一种添加到预训练模型中的小型神经网络,用于针对特定任务进行微调。这些适配器仅占原始模型大小的一小部分,从而使得训练速度更快,内存需求也更低。 Progressive Shrinking(渐进收缩):该技术在微调过程中会逐渐减小预训练模型的大小,进而产生比从头开始训练的模型性能更优的小型模型。 Prefix Tuning(前缀微调):这种方法涉及学习特定任务的连续提示,并在推理过程中将其添加在输入之前。通过对这个连续提示进行优化,模型能够在不修改底层模型参数的情况下适应特定任务。 P-Tuning:此方法涉及对可学习的“提示记号”参数进行训练,这些参数与输入序列相连。这些提示记号具有任务特异性,在微调过程中对其进行优化,从而使模型在保持原始模型参数不变的情况下,在新任务上有良好的表现。AI
固德威:智慧能源管理系统已接入多种机器学习和深度学习算法2 月 28 日前后将上演“七星连珠”罕见天象
hqy 发表于2025-02-24 浏览22 评论0
金融界2月20日消息,有投资者在互动平台向固德威提问:请问贵司智慧能源管理平台是否接入AI,后续是否考虑部署deepseek来实现实现公司AI能源赋能。

AI
探秘深度学习与自然语言处理:常见的微调策略全解析!宋朝版“权力的游戏”:宋仁宗为了给宠妃长辈升官张尧佐与文官集团的较量
hqy 发表于2025-02-24 浏览23 评论0
在深度学习和自然语言处理领域,常见的微调方法主要有以下几种:
全参数微调(Fine-tuning):这是最为传统的微调方式。它需要对预训练模型中的所有参数进行更新,以此来适应特定的任务。这种方法往往能够取得最佳性能,不过其计算成本相对较高。 提示微调(Prompt-tuning):该方法通过精心设计特定的输入提示(prompts),而不是去修改模型的权重,来使模型适应下游任务。这样能让模型在计算成本较低的情况下,适应各种各样的任务。 参数高效微调(Parameter-efficient fine-tuning):这组方法的核心在于,只对模型参数的一个子集或者新添加的一组参数进行训练,目的是减少所需的参数数量以及计算资源。对于那些资源有限的环境而言,这些技术有着至关重要的意义。 适配器训练(Adapter Training):适配器是一种添加到预训练模型中的小型神经网络,主要用于特定任务的微调。这些适配器仅仅占据原始模型大小的一小部分,所以训练速度更快,而且内存需求也更低。 渐进收缩(Progressive Shrinking):这种技术是在微调期间,逐渐减小预训练模型的规模,最终得到一个比从头开始训练性能更好的小型模型。 前缀微调(Prefix Tuning):它涉及学习特定任务的连续提示,并在推理过程中将其添加到输入之前。通过对这个连续提示进行优化,模型就能适应特定任务,且无需修改底层模型参数。 P-Tuning:主要涉及对可学习的“提示记号”参数进行训练,这些参数会与输入序列相连接。这些提示记号是特定于任务的,在微调过程中会被优化,使得模型能够在保持原始模型参数不变的情况下,在新任务上有良好的表现。AI
DeepSeek,5连发
hqy 发表于2025-02-24 浏览21 评论0
本文来自微信公众号:未尽研究 (ID:Weijin_Research)
AI
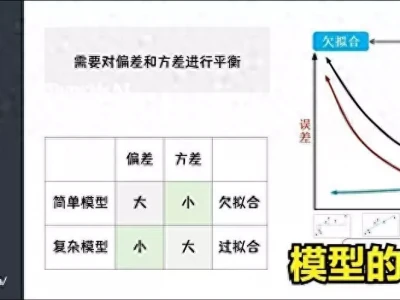
3分钟速览:机器学习模型的选择与评估之道谷神星出现意外“地质活动”震惊科学家
hqy 发表于2025-02-24 浏览21 评论0

AI
多所中小学将开启机器人授课?成都官方回复:不实这12处就算断胳膊断腿也别瞎装,个个坑的要命
hqy 发表于2025-02-24 浏览21 评论0
近日,有自媒体账号发布信息,称“成都30所中小学即将开启机器人授课”,引发网友热议。其发布的信息称,“人工智能+教学”,未来的课堂不再需要真人老师上课了?2月21日,成都市教育局有关负责人称该消息并不属实。
AI
固德威:智慧能源管理系统已接入多种机器学习和深度学习算法二战之后,斯大林指着一张苏联地图说:北方一切都好,正常
hqy 发表于2025-02-24 浏览26 评论0
金融界2月20日消息,有投资者在互动平台向固德威提问:请问贵司智慧能源管理平台是否接入AI,后续是否考虑部署deepseek来实现实现公司AI能源赋能。