文章导读
在脂质组学领域,准确且高效地预测脂质亚类一直是研究者们努力追求的目标。近期,由东京农业技术大学生物技术与生命科学系的研究团队,以及来自其他合作机构的科学家们,共同研发了一款名为MS2Lipid的机器学习模型,为这一领域带来了重大突破。MS2Lipid模型不仅展现了卓越的分类性能,还为脂质代谢物的注释提供了独立且正交的标准,显著增强了非靶向脂质组学的注释可信度。
研究过程与结果
非靶向脂质组学通过液相色谱与串联质谱 (LC-MS/MS) 技术的结合,能够全面剖析生物样本中的脂质分子概况。然而,由于脂质结构的复杂性以及质谱数据中的噪声和干扰,当前的脂质亚类注释工具仍面临诸多挑战。特别是在处理共洗脱脂质中的污染离子、源内碎片等问题时,传统方法往往难以给出准确的注释结果。因此,开发一种高效、准确的脂质亚类预测模型显得尤为重要。
MS2Lipid模型的构建与优化
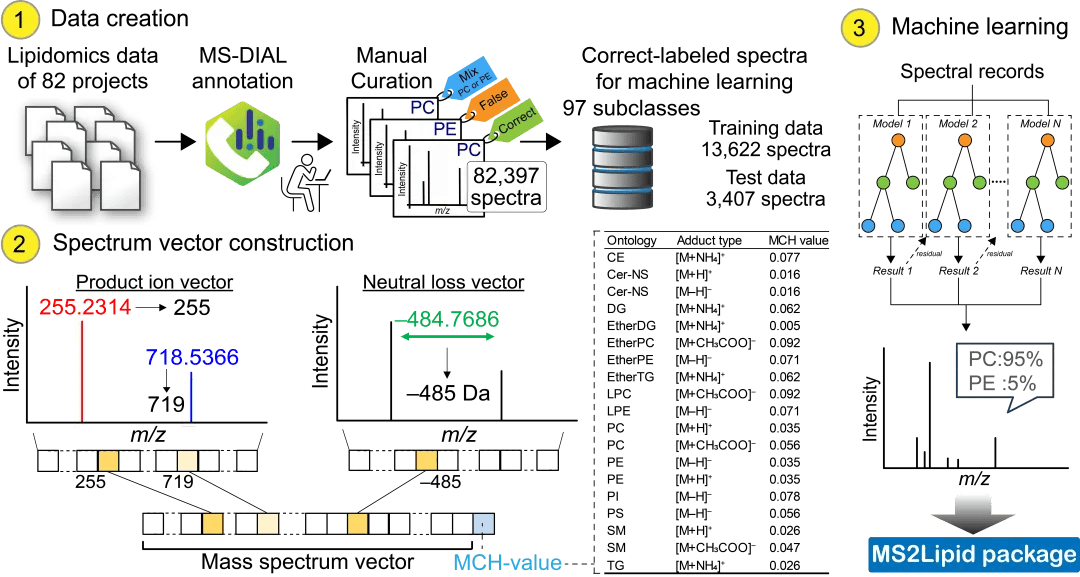
图1. 创建MS2Lipid机器学习模型的工作流程。在数据创建步骤中,光谱数据来自82个项目。脂质组学数据通过MS-DIAL分析,为包括正离子和负离子模式的82,397张光谱提供脂质注释。原始注释是手动整理的,并标记为正确、混合或错误命中。17,029张光谱的正确标记数据被分为训练集和测试集。在光谱向量构建步骤中,MS/MS光谱由产物离子和中性损失的阵列表示,其高分辨率质量值转换为标称质量。此外,从准确的母体m/z值计算出描述符“MCH值”。胆固醇酯 (CE)、含神经酰胺的鞘氨醇和正常脂肪酸 (Cer-NS)、二酰甘油 (DG)、醚连接的DG (EtherDG)、磷脂酰胆碱 (PC) 的描述符, 溶血磷脂酰乙醇胺 (LPC)、醚连接磷脂酰乙醇胺 (EtherPC)、三酰甘油 (TG)、醚连接甘油三酯 (etherTG)、磷脂酰乙醇胺 (PE)、溶血磷脂 (LPE)、磷脂酰肌醇 (PI)、磷脂酰丝氨酸 (PS) 和鞘磷脂 (SM) 是主要加合物类型。这些向量被用作机器学习模型的输入。输出显示脂质亚类分类的概率比。实验验证与性能评估
为了验证MS2Lipid模型的准确性和鲁棒性,研究团队采用了多种方法进行评估。他们首先使用来自同一台仪器的数据进行了内部验证,结果显示模型在97个脂质亚类中的分类准确率高达97.4%。随后,他们还使用了来自不同仪器和管理员的数据集进行了外部验证,平均准确率依然保持在87.2%以上。这些结果表明,MS2Lipid模型不仅具有较高的分类精度,还具有良好的泛化能力和可扩展性 (图2-5)。
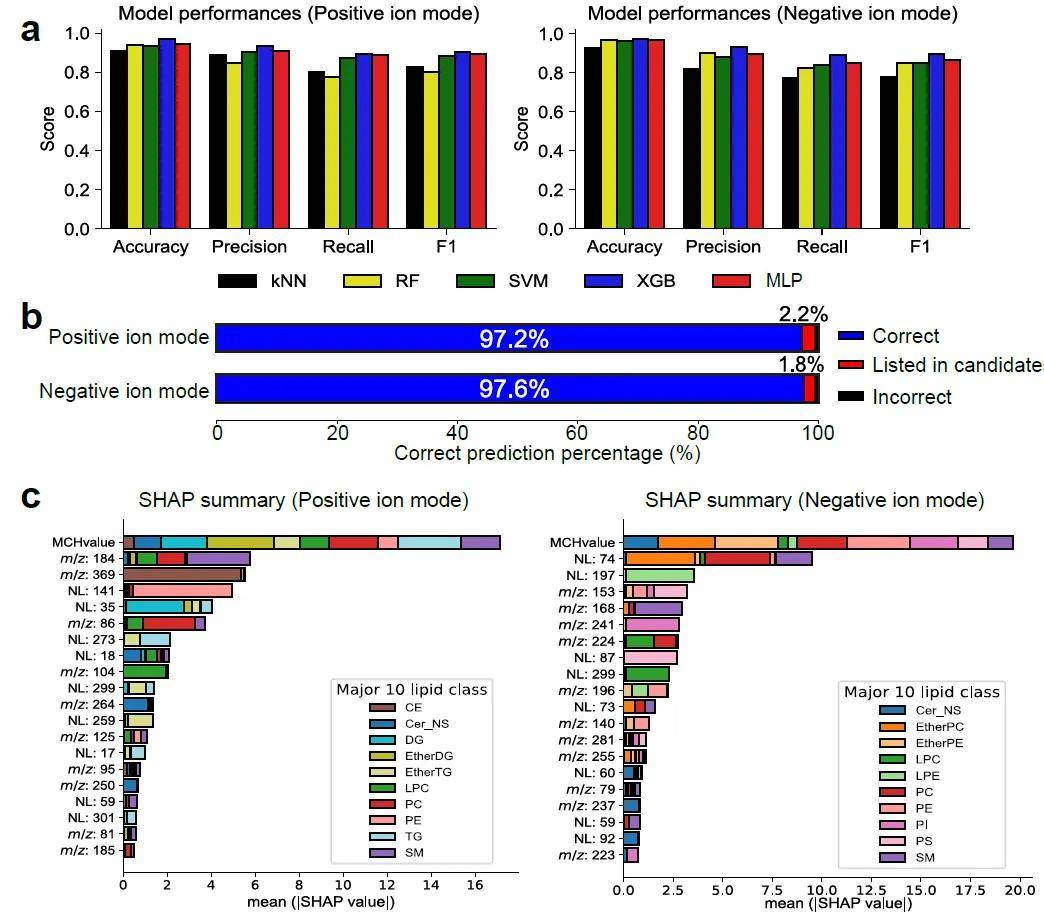
图2. 机器学习模型的评估。(a) 每个模型的准确度、精确度、召回率和F1分数,其中评估了k最近邻 (KNN)、随机森林 (RF)、支持向量机 (SVM)、XGBoost (XGB) 和多层感知器 (MLP)。(b) XGBoost模型中的预测准确度。上图和下图分别对应正离子和负离子模式下的结果。如果预测的脂质亚类等于正确的标签,则输出正确,如果候选列表中存在正确的标签,则结果将“列在候选者中”。(c) Shapley加性解释 (SHAP) 分数以研究重要的描述符。描述了用于预测10种主要脂质亚类的前20个SHAP特征。NL,中性丢失;磷脂酰乙醇胺;PI,磷脂酰肌醇;PS,磷脂酰丝氨酸;EtherPE,醚键PE;LPC,溶血酸PC;LPE,溶血酸PE。
图3. MS2Lipid与CANOPUS的比较。左图和右图分别显示正离子和负离子模式的结果。在每个脂质类别中,上图和下图分别是MS2Lipid和CANOPUS的结果。描述了ClassyFire类别级本体预测的准确率 (%)。还显示了每个本体中的分子数量。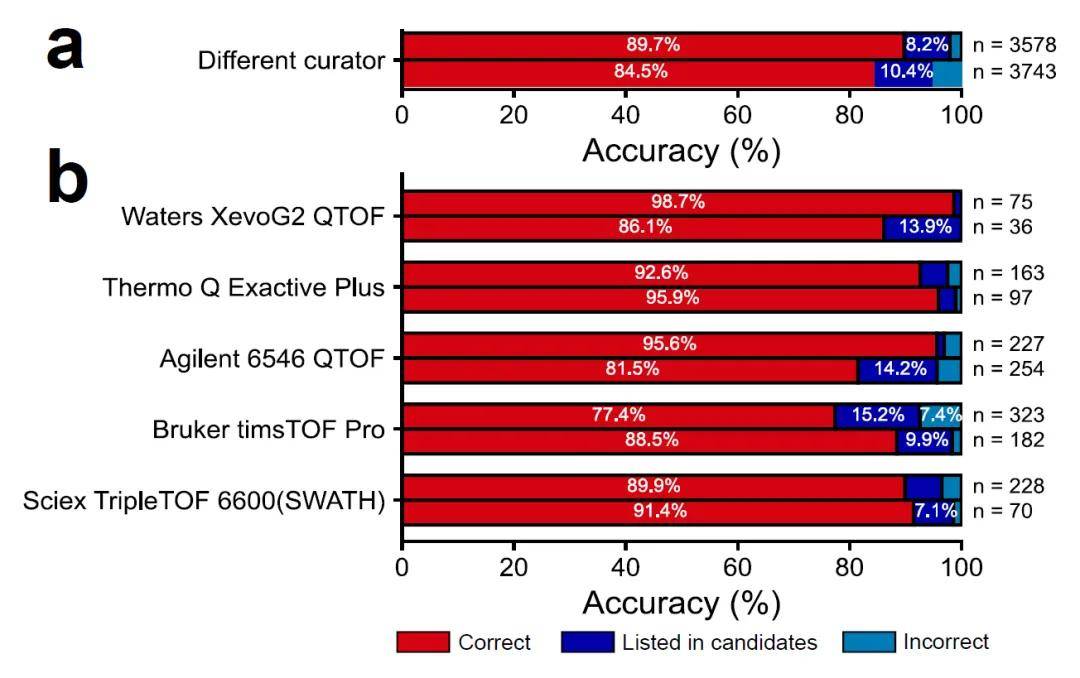
图4. MS2Lipid稳健性评估。(a) 使用不同管理员在同一台MS机器上提供的光谱数据进行验证。(b) 使用不同仪器和不同管理员获得的光谱记录进行验证。输出结果分为三种情况:如果MS2Lipid生成的标签与查询的标签相同,则结果为“正确”;如果标签不匹配,则如果正确名称以超过1%的概率出现在预测的候选中,则结果为“列在候选中”;对于其他情况,结果为“不正确”。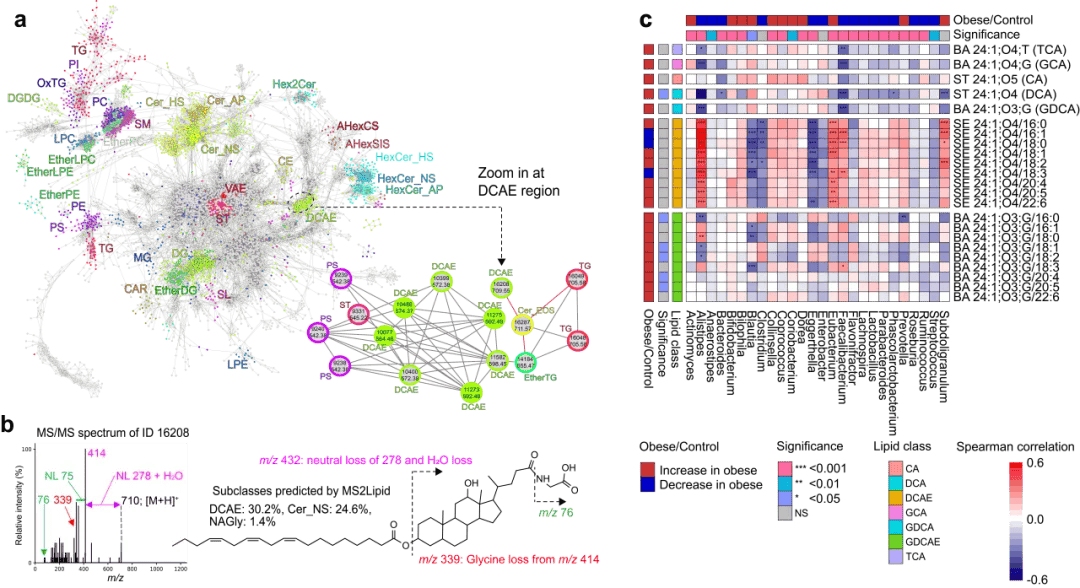
图5. 微生物衍生脂质代谢物的阐明。(a) 在分析粪便样本的人类队列研究中,从正离子模式的峰特征进行分子光谱网络化。节点填充和边框颜色分别代表 MS-DIAL 和MS2Lipid的注释。(b) 描述了新表征的胆汁酸酯及其可能结构的串联质谱。m/z 76和中性丢失 (NL) 75的特征源自甘氨酸结构。m/z 339、NL 296和m/z 414的特征分别来自脱氧胆酸的脂质亚类、含FA 18:3的脂质和乙醇酸结构。(c) 细菌与胆汁酸代谢物之间的相关性分析。计算了细菌和脂质丰度之间的斯皮尔曼相关性,其中通过t检验 (双侧) 估计统计显着性。通过Mann-Whitney U检验 (双侧) 计算肥胖和对照组的显著性。*p < 0.05,**p < 0.01,***p < 0.001。CA;胆酸,DCA;脱氧胆酸,DCAE;酯化脱氧胆酸,GCA;甘氨胆酸,GDCA;甘氨脱氧胆酸,GDCAE;酯化甘氨脱氧胆酸,TCA;牛磺胆酸。研究总结
本研究通过构建MS2Lipid机器学习模型,实现了对非靶向脂质组学中脂质亚类的高效准确预测。该模型不仅提高了脂质代谢物的注释可信度,还为脂质组学的研究提供了新的工具和方法。未来,研究团队将继续优化和完善MS2Lipid模型,进一步提高其分类精度和实用性。同时,他们还将探索将MS2Lipid应用于更广泛的生物样本类型和疾病研究领域,为精准医疗和生物标志物发现贡献力量。
原文信息
Sakamoto, N.; Oka, T.; Matsuzawa, Y.; Nishida, K.; Jayaprakash, J.; Hori, A.; Arita, M.; Tsugawa, H. MS2Lipid: A Lipid Subclass Prediction Program Using Machine Learning and Curated Tandem Mass Spectral Data. Metabolites 2024, 14, 602. https://doi.org/10.3390/metabo14110602
Metabolites 期刊介绍
期刊发表与代谢组学、代谢生物化学、计算和系统生物学、生物技术和医学领域相关的代谢物以及代谢方面的原创研究文章与评论文章。目前已被SCIE (Web of Science)、Scopus、PubMed、PMC、Embase、CAPlus/SciFinder等数据库收录。
2023 Impact Factor: 3.52023 CiteScore: 5.7返回搜狐,查看更多