
最近,普林斯顿大学、字节跳动、清华大学和北京大学联手搞了个大事情,推出了一款名为 MMaDA 的多模态大模型! 这可不是普通的 AI,它号称能让 AI 拥有“深度思考”的能力,还能在文本、图像、甚至复杂的推理任务之间“七十二变”,表现力直接超越了你熟悉的 GPT-4、Gemini、甚至 SDXL!

你可能觉得,现在的多模态模型已经很厉害了,能看图说话,也能根据文字生成图片。但 MMaDA 告诉我们:这还远远不够! 传统的模型在处理不同模态时,往往需要各自独立的组件或者复杂的混合机制,就像一个“多功能工具箱”,虽然啥都有,但每个工具都是独立的,切换起来多少有点别扭。
MMaDA 团队就是要打破这种“壁垒”,让 AI 真正实现一体化!
MMaDA 的三大“黑科技”:让 AI 不止看懂,还能“想明白”!
MMaDA 之所以能脱颖而出,秘诀就在于它的三大核心创新:
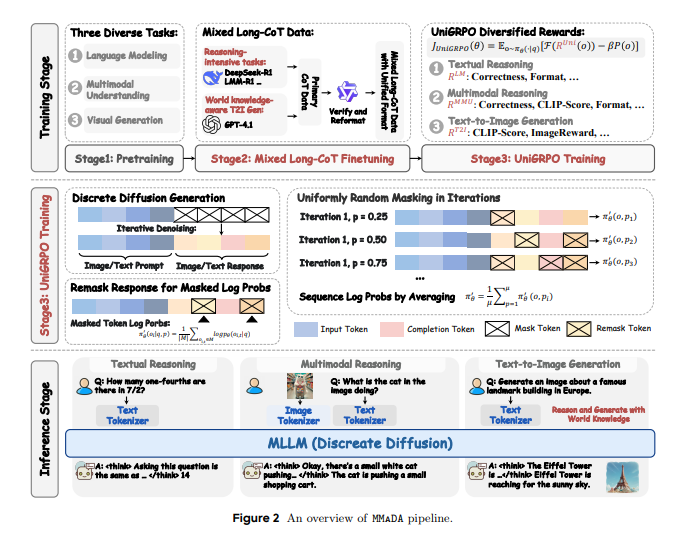
统一扩散架构:模态盲盒,一网打尽!
想象一下,你有一个超级智能的“万能胶水”,能把各种不同形状、不同材质的碎片都完美地粘合在一起。MMaDA 就采用了这样的“万能胶水”——统一扩散架构。 这种架构具备共享的概率公式和模态无关的设计,这意味着它处理文本、图像等不同类型的数据时,无需模态特有的组件! 这样一来,AI 就能在不同数据类型之间无缝切换和处理,效率和连贯性都大大提升。

混合长链式思考(Mixed Long CoT)微调:让 AI 学会“深度思考”!
我们知道,大模型能“思考”,很多时候靠的是“思维链”(Chain-of-Thought,CoT)。 但 MMaDA 更进一步,搞了个 “混合长链式思考”微调策略。 它精心设计了一种跨模态的统一 CoT 格式,强制 AI 在文本和视觉领域之间对齐推理过程。 这样做的目的,是让 AI 在进入最终的强化学习阶段前,就能有一个“冷启动”的训练,从一开始就增强处理复杂任务的能力! 就像给 AI 提前准备好一本“武林秘籍”,让它在实战前就掌握了“深度思考”的内功心法!
统一强化学习算法 UniGRPO:生成与推理,齐头并进!
光会思考还不够,AI 还需要“实践出真知”!MMaDA 提出了一个专门针对扩散模型设计的统一策略梯度强化学习算法——UniGRPO。 它通过多样化的奖励建模,巧妙地统一了推理和生成任务的后训练,确保模型性能持续提升。 以前,推理和生成可能需要不同的训练方法,但 UniGRPO 就像一个“全能教练”,能同时指导 AI 在“智力竞赛”(推理)和“创意工坊”(生成)中都表现出色!
MMaDA 的“战绩”:全面碾压,跨界称王!
有了这三大“黑科技”加持,MMaDA-8B 模型在各项测试中都表现出了惊人的泛化能力,简直是“跨界称王”:
文本推理:它竟然超越了 LLAMA-3-7B 和 Qwen2-7B! 这意味着在数学问题解决、逻辑推理等复杂文本任务上,MMaDA 展现出了更强的“智力”!
多模态理解:它优于 Show-o 和 SEED-X! 在理解图片、回答图片相关问题上,MMaDA 的表现更准确、更全面。
文本到图像生成:它超越了 SDXL 和 Janus! 这可不是小成就,SDXL 是目前公认的图像生成强者,而 MMaDA 竟然能生成更准确、更符合世界知识的图片,这得益于它强大的文本推理能力!
AIbase 认为:这些成就凸显了 MMaDA 在弥合统一扩散架构中“预训练”和“后训练”之间鸿沟方面的有效性,为未来的研究和开发提供了一个全面的框架。

深入 MMaDA 的“内功心法”:如何实现“七十二变”?
那么,MMaDA 具体是怎么做到这种“七十二变”的呢?
统一 Token 化:无论是文本还是图像,MMaDA 都用一致的离散 Token 化策略来处理。 这样,所有数据都变成了统一的“乐高积木”,模型可以在一个统一的预测被遮蔽 Token 的目标下进行操作。 比如,一张512x512像素的图片,会被转换成1024个离散的 Token! 简直是给不同模态穿上了统一的“制服”!

三阶段“修炼”:MMaDA 的训练过程就像“打怪升级”,分为三个阶段:
基础预训练(Stage1):用海量的文本和多模态数据,让模型打下坚实的基础。
混合长链式思考微调(Stage2):用精心策划的“长链式思考”数据,让模型学会推理和思考。 这一步是让模型从“知道”到“明白”的关键!
UniGRPO 强化学习(Stage3):最后用强化学习,让模型在推理和生成任务中持续优化,追求卓越。
灵活的采样策略:在推理时,MMaDA 也非常灵活。
文本生成采用半自回归去噪策略,能生成更复杂、更详细的描述。
图像生成则采用并行非自回归采样,效率更高。 这种灵活的组合,保证了在不同任务上的最佳表现。
不仅仅是生成:MMaDA 还能“脑补”和“填空”!
MMaDA 还有一个隐藏技能,那就是它天然支持图像修复(inpainting)和外推(extrapolation),而且无需额外的微调! 这得益于扩散模型的特性,这些任务本身就可以被看作是“被遮蔽 Token 预测”问题,而这恰好是 MMaDA 训练目标的一部分!
这意味着:
它能预测文本序列中缺失的部分。
能在给定图像和部分输入的情况下补全视觉问答的答案。
甚至能根据不完整的视觉提示,进行图像修复!
这简直是把 AI 变成了能“脑补”画面和“填空”的万能助手,极大地扩展了它的应用场景和泛化能力!
结语:扩散模型,AI 未来的新范式?
MMaDA 的诞生,无疑是多模态 AI 领域的一个里程碑。它首次系统地探索了基于扩散模型的通用基础模型设计空间,并提出了创新的后训练策略。 实验结果表明,MMaDA 不仅能与那些专用模型相媲美,甚至在某些方面表现更优,这充分展示了扩散模型作为下一代多模态智能基础范式的巨大潜力!
虽然 MMaDA 目前的模型尺寸(8B 参数)还有提升空间,但它的出现,无疑为 AI 领域描绘了一个更宏大、更统一的未来。想象一下,未来的 AI 不再是各自为战的“专家”,而是一个能深度思考、跨模态理解、还能无限创意的“全能天才”!
项目地址:https://github.com/Gen-Verse/MMaDA
