
来源:AI科技大本营
文 | 郑丽媛
过去这一年,AI 世界风云再起。
从 DeepSeek R1、OpenAI o3 的激烈竞逐,到 AI 智能体频频登上技术热榜;从“推理能力”成为衡量大模型的新标准,到人形机器人、具身智能(Embodied Intelligence)被寄予厚望……我们正站在 AI 技术快速演进的关键时刻。然而,在这些热闹表象的背后,一场更深层的技术讨论也正在悄然发生:我们真的了解智能吗?我们构建的 AI 真的在“学习”吗?
在这样一个值得深思的节点,加拿大阿尔伯塔大学计算科学系教授、图灵奖得主 Richard Sutton 在 6 月 6 日举行的北京智源大会上,带来了一场名为《欢迎来到经验时代(Welcome to the Era of Experience)》的主题演讲。
在整场演讲中,Richard Sutton 没有谈模型架构、参数量,没有讲热门的大语言模型,也没有讨论多模态系统的未来路线图——他选择回到 AI 的第一性原理,提出了一个颠覆直觉、却极具穿透力的主张:真正的智能,应该来源于经验,而不是人类预设的数据与知识。
Richard Sutton 演讲的精彩观点预览:
1、真正的 AI,必须拥有一个能随着它自身变强而不断成长和丰富的数据源,任何静态的数据集都将后继无力。
2、一个智能体的智能程度,取决于它能否有效预测与控制感官输入,也就是能否准确地预判环境反馈,并采取相应策略——这一能力,才是 AI 和智能的本质。
3、创造出超级智能体或被超级智能增强的人类,对世界而言将是一件纯粹的好事。我并不担心所谓的“AI 安全问题”或“技术失业”问题——在我看来,这些都只是世界发展转型过程中的阶段性阵痛。
4、那些呼吁控制 AI 的论调,与呼吁控制人的论调,是何其相似。
5、人类的繁荣,以及未来 AI 的繁荣,都应当建立在“去中心化合作”的基础之上。
以下为 Richard Sutton 演讲全文翻译:
当下,正值人工智能(AI)发展史上的一个关键节点,也是最令人激动的时代之一。我今天想传达几个观点,这些内容与 Yoshua Bengio 刚才所讨论的议题息息相关,但我将提供一个截然不同的视角——这一点将在我演讲的第二部分中突出。
首先,我今天的演讲主题是:“欢迎来到经验时代”。
为了引出本次演讲的两个核心观点,我想先引用两句富有启发性的名言:
“智能,是宇宙中最强大的现象” ——出自美国作家、发明家和未来学家 Ray Kurzweil。这句话让我们感受到,在 AI 这场变革中,我们所面对的赌注有多大。而智能,确实是宇宙间最为强大的力量。
“我们想要的,是一台能从‘经验’中学习的机器”——出自计算机科学之父、人工智能之父 Alan Turing 在 1947 年的一次演讲,那可能是人类历史上首次关于人工智能的公开演讲。在那个年代,“人工智能”这个领域尚未真正诞生,Alan Turing 就已精准预言了未来方向:我们真正想要的机器,必须能从它自己的第一人称体验中学习。这正是我们今天要讨论的核心,而我们,正迈入这个全新的“经验时代”。

我们正在进入“经验时代”
此时此刻,我们所处的时代,可以称之为“人类数据时代”。当前几乎所有的 AI,都依赖于从互联网上抓取的海量文本和图像进行训练,再由人类专家通过偏好和示例进行微调。整个系统的目标,并非真正地去预测或理解这个世界本身,而是模拟人类的语言生成模式,学习如何预测下一个词或模仿人类的判断。
但我认为,我们正在触及“人类数据”这一发展路径的极限。目前几乎所有高质量的人类数据源,都已被我们“榨干”了。更重要的是,若我们希望 AI 能生成真正原创、前所未有的知识,仅仅模仿人类是远远不够的,AI 必须主动与世界发生交互。
如今,我们正踏入“经验时代”。真正的 AI,必须拥有一个能随着它自身变强而不断成长和丰富的数据源,任何静态的数据集都将后继无力。而这种源源不断的新数据,只能从“经验”中来——即从 AI 与世界之间的互动中来。
所谓“经验”,本质上就是来自传感器的输入信号,以及通过执行器对外界做出的反馈动作。这也是人类和其他动物学习最本真的方式。
以下面这个人类婴儿为例。他会主动与世界进行互动,轮流摆弄眼前的各种玩具,试图搞明白这些东西能用来干嘛。请注意,是婴儿自己选择了注意力焦点,从而决定了他接下来会得到什么信息。他会专注于一个玩具或一根绳子,直到感觉学得差不多了,再转向下一个。随着他心智的成长,它能从每个物体上学到的东西会变多,互动的行为也会变得更复杂。换句话说,他自身的行为决定了他的输入、经验和数据。而这,正是我们希望 AI 能够做到的。
再看看人类和动物在自然情境中的学习过程,例如踢足球、射门得分。想象一下,在射门的那一瞬间,数据流如洪水般涌入足球运动员的眼睛、耳朵以及身体里的各种传感器。周围的一切都在快速变化,信息量巨大。他不可能察觉到每一个细节,但必须快速决策,才能射门得分。
这就是一个足球运动员的世界,也同样适用于一只飞越森林的鸟、一头逃避天敌的野兽、一个挥棒击球的选手,甚至是一场实时对话……在这些情境中,我们面临的是一种以高带宽信号为基础的感知与行动机制,它构成了技能和智慧的核心——而这,就是“经验”。当我说“经验”时,我并不是在谈论什么“感质”(qualia)之类玄乎的哲学概念,我指的就是那些实实在在流经心智的输入信号与输出行为。
请记住,只有这样,数据源才能随着心智能力的提升而变化。就像一个下棋的 AI,随着它棋力精进,它所面对和生成的棋局数据也会越来越高级、越来越复杂。AlphaGo 正是在这种与自己反复对弈的“经验”中,才诞生了那被称为“神之一手”的第 37 手。因此我说,从经验中学习至关重要,因为“经验”就是通过模拟各种可能的走法及其后果而产生的。
在游戏中实现这一过程相对容易,因为游戏规则是清晰已知的。同样的逻辑也适用于赢得国际数学奥林匹克奖牌的 AlphaProof 系统——在数学世界中,每一步推理的后果都可以被精确预见,就如同在围棋中预测每一步落子的后果一样。
说到这里,我们来总结一下这种“经验主义”在 AI 中的思维模式。在这种模式下,智能体(Agent)通过与世界的持续交互获取经验,而学习,就是从这些经验中提炼出模式与策略。我有一个更深层的观点:智能体所拥有的一切知识,归根结底都必须建立在经验基础上。即使某些知识是事先灌输的,最终也必须在智能体与环境的交互中才具有实际意义。知识的本质,不是关于“文本”的简单陈述,而是“如果我采取某个行动,世界将如何响应”的因果认知。既然本质上来说知识源于经验,那么它就可以通过经验被习得。
一个智能体的智能程度,取决于它能否有效预测与控制感官输入,也就是能否准确地预判环境反馈,并采取相应策略——这一能力,才是 AI 和智能的本质。而“经验”正是这一机制的基础。事实上,越来越多算法正基于这种思维模式构建:它们拥有第一人称视角,具备感知、决策、目标导向与环境互动能力,也正是我们所说的 AI 智能体(Agentic AI)系统。
我们可以用一条时间线来描述 AI 技术的演进路径,并定位我们当前所处的位置:
模拟时代:以 AlphaGo 和 Atari 游戏为代表。强化学习的智能体在模拟环境中训练,通过大量试错获得策略突破,最终诞生了 AlphaZero 等革命性成果。
人类数据时代:以 GPT-3 和 ChatGPT 等大语言模型为标志。这一阶段,模型主要从人类生成的海量文本与图像中学习,而我们或许正接近这个时代的尾声。
经验时代:我们正在步入这个新时代。在这个时代,AI 将通过与真实世界的交互来生成数据并提升能力,AlphaProof 就是这个趋势的早期体现。当大语言模型一旦被赋予操作计算机和 API 的能力,实际上它就已经开始在世界中“采取行动”了。
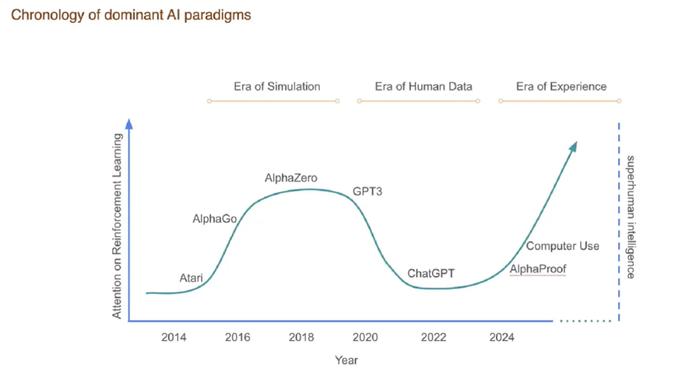
以上,就是我关于 AI 未来的第一个核心观点:我们正在进入“经验时代”。
而我的第二个观点是:创造出超级智能体或被超级智能增强的人类,对世界而言将是一件纯粹的好事。
坦白说,我并不担心所谓的“AI 安全问题”或“技术失业”问题——在我看来,这些都只是世界发展转型过程中的阶段性阵痛。这需要时间,可能几十年、甚至更久,这是一场需要耐心的马拉松,而非一蹴而就的冲刺。但正因其深远影响,我们必须现在就开始做准备。
真正意义上的智能体,必须能够在自身经验的基础上实现“持续学习(Continual Learning)”。这要求它具备在记忆体系之上不断更新知识和技能的能力。虽然目前的大语言模型作为一种强大的“世界知识接口”已经非常出色,但只有具备持续学习的能力,才能真正释放“经验时代”的全部潜力。

“去中心化合作”
接下来,我们来探讨一个更宏观的话题:政治。这个话题也呼应了 Yoshua Bengio 教授在其演讲中提出的一些重要思考。
我们必须先提出一个最基本的问题——社会的目标到底是什么?这是一个哲学性极强的问题:社会是否存在一个所有人都共享的终极目标?还是说,社会中的个体拥有各自不同的目标?
作为一名强化学习研究者,我常用的一种思考方式是:观察我所训练的那些 AI 智能体是如何运作的。在强化学习框架下,每一个智能体都有其独立的目标函数。这个目标函数定义了它想要最大化的奖励信号(Reward Signal)。智能体通过感知环境输入信号,并据此采取行动,从而尝试最大化获得的奖励。但没有任何理论要求不同智能体的奖励信号必须一致。
那我们再看看大自然,每一种动物的大脑中也都有类似机制。例如下丘脑中计算的神经信号、还有痛觉和快感等——这种机制,与 AI 系统中奖励函数的概念非常接近。因此在 AI 系统和自然界中,有一个共同的事实是:每个个体都有自己的目标。
当然,我们也可以说这些目标在某种层面上存在相似性。例如,所有动物都需要食物。但我们也必须认识到:一只动物所需的“食物”并不一定适合另一只动物。它们的目标在结构上或许是“对称的”(symmetrical),但在具体内容上却是“不同的”(non-identical)。
对于人类来说,这种差异性更为明显。我们关心的是自己的家庭、自己的食物和自己的安全,因此人类并不存在一个统一、共享的终极目标。
这也引出了一个值得深思的问题:我们的经济体系是如何以最佳方式运作的?我认为,当人们拥有不同目标和不同能力时,经济才能实现最优运行。这些目标并不一定要彼此冲突,但它们可以是多样的,这种差异性反而构成了整个社会协作的基础。我们的经济并不是建立在统一目标之上,而是依赖于每个人追求的自身目标,通过交易、协作与互动形成分工,从而构建出一个复杂而高效的系统。
这是一个简单却深刻的真理:即使我们想要的东西各不相同,我们依然可以和平共存。
为了更深入地讨论这个问题,无论你是否认同上述观点,我都想先给出几个定义。
“去中心化”(Decentralization):一个系统中包含许多个智能体,每个智能体都在追求自己的目标。这与“中心化”(Centralization)形成了鲜明对比,后者是指系统中也有多个智能体,但它们都被约束着去追求同一个目标。举例来说,蜂群是一种中心化的社会形态,一个蜂巢里有很多工蜂,但它们都在为“蜂巢的繁荣”这一个目标而服务。所以,去中心化,就是允许多个智能体拥有并追求各自不同的目标。
“合作”(Cooperation):拥有不同目标的智能体,为了互惠互利而进行互动。通过这种互动,每个智能体都能更好地实现自身的目标。这是一种交换,也是一种双赢。
因此,请大家记住这两个关键概念:“去中心化”与“合作”。
我认为,合作是人类在演化中发展出的超能力,人类的合作程度远超其他任何动物。语言和货币这两项人类独有的发明,极大地促进了合作。人类最伟大的成功,都是合作的产物,例如经济体系、市场机制与政府组织;而最苦涩的失败,多是合作机制失效的结果,例如战争、盗窃和腐败。
这种“去中心化合作”的观念,是一种理解社会组织方式的全新视角。在我看来,它比传统的中心化视角更为优雅。去中心化合作更加具有韧性、更可持续、更灵活,也更能够抵御欺诈者与害群之马。
人类虽然是合作大师,但我也必须承认,我们在这方面依然做得很糟糕:战争、盗窃、腐败与欺诈仍频繁发生。所以,合作从来都不是唾手可得的,它至少需要两个值得信任的参与方,而世界上总会有一些不可信赖的人,比如骗子、小偷和独裁者等。
合作固然伟大,但它仍需要制度来保驾护航,以惩治那些破坏合作机制的行为。中心化的权力机构可以通过制定制度、规范行为来促进合作,但从长远来看,当这些权力机构变得专制或僵化时,它们反而可能会毒害合作。因此,我认为“中心化控制”与“去中心化合作”之间的张力,正是我们这个时代最核心的政治议题。
如果你细致观察,就会发现:那些呼吁控制 AI 的论调,与呼吁控制人的论调,是何其相似。
现在,有很多人呼吁要控制 AI,包括刚才演讲的 Yoshua Bengio 教授,他明确呼吁要控制 AI 的目标,甚至控制它们拥有目标的能力;有人呼吁暂停或停止 AI 研究,减慢它的发展速度;有人呼吁限制用于制造 AI 的算力;还有人呼吁必须确保 AI“安全”并要求信息披露。
这些主张,本质上与许多政治争议类似,例如:我们是否应保障言论自由?是否允许公众听到不同意见?应支持自由贸易,还是必须干预就业市场?金融资本应如何监管?这些争论,与那些关于控制 AI 的呼吁,相似得令人不安。这本质上是一个社会性问题:我们打算如何面对“多个个体拥有多个目标”这一现实?是应当鼓励去中心化,还是趋向中心化控制?
所有主张中心化控制的声音,听起来都差不多,本质都建立在“恐惧”之上,并采用“我们 vs 他们”的对立逻辑。不论在何种社会,这类论调总会出现:在美国,“我们”是美国人,“他们”是俄罗斯人;在中国,则“我们”是中国人,“他们”是美国人。中心化的控制论总是将“他者”妖魔化,声称对方不可信。但我认为,在任何社会中,总会有少数人不可信,但绝大多数人都是可信的。
总体来说,我坚信:人类的繁荣,以及未来 AI 的繁荣,都应当建立在“去中心化合作”的基础之上。虽然人类擅长合作,却也常常搞砸合作。合作并非唾手可得,但它却是世间一切美好的源泉。我们必须去寻找合作、支持合作,并致力于将其制度化。
在此,我诚挚地邀请各位,运用自身与世界互动的真实经验,用清醒的双眼观察世界。我相信,只要你愿意去看,就能识别出那些正在鼓吹不信任、不合作与中心化控制的论调。我认为,我们应当坚定地抵制这些声音。
最后,我想说一句:尝试用“去中心化合作 vs 中心化控制”的视角,去重新审视人类与 AI 之间的所有互动,将会是一个极具启发性的视角。

对话与问答
在 Richard Sutton 的精彩演讲之后,清华人工智能研究院副院长,生数科技创始人兼首席科学家,智源首席科学家朱军与他进行了一番精彩问答。
以下为问答实录:
朱军:Yoshua Bengio教授在刚才的演讲中提到,应构建一种无心智的“非智能体 AI”(non-agentic AI);而与他相反,你则强调要发展“智能体 AI”(agentic AI)。
因此,我的第一个问题正是围绕这个分歧展开的:在中国,包括北京智源人工智能研究院在内的众多机构,都非常重视为社会福祉而开发安全、可靠、负责任的 AI。从强化学习的视角来看,既然智能体会自主优化其目标,如果我们不对其施加合理的控制,你是否认为存在潜在风险?
Richard Sutton:当大家消化我和 Yoshua Bengio教授的演讲时,首先要明白一点:我们俩的初衷都是好的,都希望创造一个美好的世界,让 AI 造福人类,让人们社会更加成功而友善。
但我们之间存在一个根本性分歧:包括Yoshua Bengio 在内的许多人,他们呼吁的是改变 AI 本身——限制它们、控制它们——以此来确保安全。而我呼吁的,是改变 AI 所处的社会环境,改变这个世界,从而让那些智能体出于理性,自然而然地选择去做有益的、合作的事情。
这就是关键的区别。我们究竟应该依靠筛选和控制 AI 来防止它们伤害人类,还是应该努力建设一个能够容纳所有参与者、激励他们合作与贡献的世界?
如果以此为基本分歧,我们就可以看到一些问题。比如,试图去改变 AI 本身,是一个有些危险的策略,因为它防不住“作弊者”。即便我们把自己研发的 AI 都设计得“足够安全”,但只要有一个人造出了“不安全”的 AI,我们就会有大麻烦。
相反,如果我们把重点放在改善 AI 所处的环境上,让每一个参与者都能在其中贡献和共存,那么我们就能更好地防范作弊者——这种方式更像是一种“逐渐演化的稳定策略”。而寄希望于控制 AI 本身的做法,其实反而是一种高风险策略。
朱军:你曾强调,强化学习是一个非常强大的范式,目前我们广泛使用它来构建大语言模型和 AlphaGo 这样的系统。但如果展望未来,我们希望构建一种“超人级别智能”的 AI,对于强化学习这一范式本身,你认为我们需要引入哪些最核心的新元素或假设,来开发出更好的算法?
Richard Sutton:如果我们从大语言模型出发,显而易见,我们需要目标、行动,以及一种对“真实”的感知能力。我有一个核心观点:“不要要求一个智能体知道它无法亲自验证的事情。”换句话说,这就需要“经验”来为我们提供一个“真理”的来源。
针对你的问题——强化学习还需要增加什么才能更加强大?我认为,虽然强化学习本身已经非常强调“经验”,但仍存在一些问题:
(1)当前的强化学习不具备持续学习的能力,而这正是现代深度学习算法的一大软肋。
(2)我们尚未掌握如何有效利用学习到的“世界模型”(World Model)来进行规划(Planning)。在围棋或数学这种不需要学习世界模型的任务中,我们可以做出很棒的规划;可一旦进入充满不确定性的现实世界环境,我们仍然束手无策。
也正因为如此,我认为 AGI(通用人工智能)不会在两年内实现。如果我们运气好,可能需要五年,但也很可能还需要十五年。
朱军:基于此,我还有一个后续问题。你曾写过一篇广为流传的文章——《苦涩的教训》(The Bitter Lesson),你在文中强调,相比人类知识或人为设计的规则而言,可扩展的计算能力更为重要。那么,这一观点同样适用于强化学习吗?从长远来看,我们是否也应该避免在强化学习中引入过多的人为设计?
Richard Sutton:关于《苦涩的教训》和现代 AI,我首先要说的是,“经验时代”与“人类数据时代”之间的这种冲突,恰恰就是这篇文章的一个完美例证。
“人类数据时代”,指的是我们试图通过利用人类已有的数据,让一个系统运行得更好。但这条路最终会走到尽头,就像我们在构建大语言模型时已经触及了人类数据的极限一样。我们必须用某种可扩展、可增长的东西来取代人类数据,以真正发挥可扩展计算的优势——而这个东西,就是“经验”。
从依赖“人类数据”逐步转向依赖“经验”的过程,本身就是《苦涩的教训》的一次真实写照。
