
2022年11月30日,OpenAI推出一款对话式AI模型「ChatGPT」,可通过模拟对话的形式完成文本问答、代码生成等任务,在一定程度上可替代搜索引擎,是AIGC领域的现象级应用。
上线仅5天用户数量就突破100万,2个月超过1亿,NVIDIA创始人黄仁勋表示:ChatGPT相当于AI界的iPhone时刻。

上一次AI获得这种级别的关注,还是2016年DeepMind的「AlphaGo」。
不同的是,这一次很可能引发「第四次工业革命」和「第二次信息革命」。

一、AI模型
AI模型分为决策式/分析式AI(Discriminant/Analytical AI)和生成式AI(Generative AI)两类。
决策式AI:学习数据中的「条件概率分布」,学习已有数据后,进行分析、判断和预测。
生成式AI:学习数据中的「联合概率分布」,学习归纳已有数据后,进行演绎创作。
【通用人工智能(Artificial General Intelligence,AGI),高于这两类AI模型,具备与人类同等智慧、或超越人类的人工智慧】

AI模型最初是针对特定的应用场景进行训练,「小模型」的通用性差,换到另一个应用场景可能并不适用,需要重新训练。同时,模型训练需要大规模的标注数据,某些应用场景的数据量少,导致训练模型的精度不理想。
随着数据、算法、算力的提升,基础模型(Foundation Model)开始兴起,「大模型」是在大规模的无标注数据上进行训练。大模型泛化能力强,进行微调(在特定任务上使用小规模的有标注数据进行二次训练),或者不微调,就可完成多个应用场景的任务。

二、GPT模型
生成型预训练变换模型(Generative Pre-trained Transformer,GPT),2018年由OpenAI在论文《Improving Language Understanding by Generative Pre-Training》中提出,是一种基于互联网可用数据训练的文本生成深度学习模型。

机器学习(Machine Learning,ML)是AI算法的重要组成部分。
神经网络(Neural Network,NN)是机器学习的一个子领域。
深度学习(Deep Learning,DL)是神经网络的子领域,使用了更复杂和更深层次的网络结构,来处理更高维度和更抽象的数据。
强化学习(Reinforcement Learning,RL)也是机器学习的一个子领域。
DL与RL相互结合,就是深度强化学习(Deep Reinforcement Learning,DRL)。

GPT经历了人工智能发展的三大阶段:
1、机器学习(ML):2012年,随着基础算力的提升,全球开启人工智能热潮即大数据时代。
2、神经网络(NN): 2015年,开始繁荣爆发,它是通过对人脑基本单元神经元的建模和链接,模拟人脑神经系统设计的一种计算模型,可用来对数据间的复杂关系进行建模。
典型的应用场景为自然语言处理(Natural Language Processing,NLP)和机器视觉(Computer Version,CV)。
最具代表性的两个模型分别是循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)。

3、Transformer算法:2017年6月,Google发表论文《Attention is all you need》,首次提出基于自我注意力机制(self-attention)来提高训练速度的Transformer模型,用于自然语言处理。
Transformer是一种基于注意力机制的编码器-解码器(Encoder-Decoder)模型,通过自我监督或无监督进行训练,按输入数据重要性不同,分配不同权重,仅用attention来做特征抽取。
Transformer具备跨时代意义的原因是在算法上添加了「self-attention」,具备突破性的原因在于:
(1)突破了循环神经网络(RNN)不能并行计算的限制。
(2)相比卷积神经网络(CNN),关联所需的操作次数不随距离增长。
(3)模型解释力度明显加强,根据CDSN数据,Transformer的综合特征提取能力、远距离特征捕获能力、语义特征提取能力,全部明显增强。

GPT是单向表征的自回归语言模型,是典型的「无监督预训练+有监督微调」的两阶段模型,该预训练模型基于Transformer架构(具有自注意力机制,可捕捉句子中的上下文关系),先在没有标注的数据集上进行预训练,再在下游特定任务有标注的数据集上微调。
预训练阶段
对于一个含有大量单词的语料库𝒰={𝑢1,...,𝑢𝑛},使用极大化似然函数来进行优化:
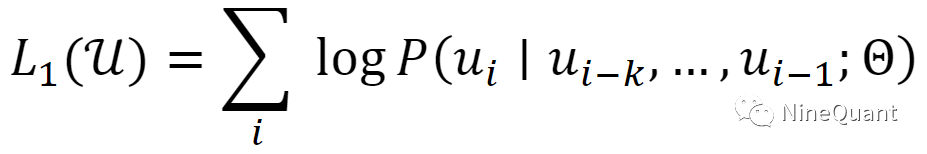
𝑘是预测时所用到的单词的个数,𝑃是用于预测的模型,定义𝑈=(𝑢−𝑘,...,𝑢−1)为输入的𝑘个单词的编码序列,𝑊𝑒为词嵌入映射矩阵,𝑊𝑝为位置嵌入矩阵,L表示堆叠的Block层数,预训练流程可以按如下方法公式化:

预训练完成后
使用少量带标注的下游任务数据对模型进行微调,赋予大模型在小数据集、零数据集下的理解和生成能力,可以根据给定文本预测下一个单词的概率分布,从而生成人类可理解的自然语言,引起了生成式AI认知能力的质变。

三、ChatGPT的前生今世
ChatGPT从诞生到现在,经历了五大版本的演化。

1、GPT-1
2018年6月,OpenAI发表论文《Improving Language Understanding by Generative Pre-Training》,GPT-1诞生,模型参数量为1.17亿。
首次提出生成式预训练概念,基于Transformer架构搭建训练模型,训练过程包括预训练和微调两个阶段,采用半监督式学习。
2、GPT-2
2019年2月,OpenAI发表论文《Language Models are Unsupervised Multitask Learners》,提出GPT-2,模型参数量为15亿。
取消了GPT-1的有监督微调阶段,引入了「zero-shot」概念,即不再需要有标注的数据集来进行子任务的微调,而是全程采用无监督式学习来训练模型。
3、GPT-3
2020年5月,OpenAI发表论文《Language Models are Few-Shot Learners》,提出GPT-3,模型参数量为1750亿。
提出「few-shot」少量样本学习,并在微软投资的加持下,将模型扩大到一个新的维度,是当时所有基于NLP的预训练模型中最大的,同时也带来大量的算力消耗,GPT-3 在微软提供的Azure AI超算基础设施(由V100GPU 组成的高带宽集群)上进行训练。

4、ChatGPT
2021年6月,基于GPT-3,OpenAI推出通用代码生成模型Codex。
2022年2月,OpenAI发表论文《Training language models to follow instructions with human feedback》,公布Instruct GPT,训练参数量仅13亿。

2022年11月,OpenAI正式推出对话交互式的ChatGPT。
ChatGPT是在GPT-3.5的基础上,加入基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来不断微调,使得大语言模型(Large Language Model,LLM)学会理解不同类型的命令指令,并通过多重标准判断基于给定的prompt输入指令,输出是否为优质信息,使得人机对话更加人性化,更有逻辑性,实现「智慧涌现」的效果。

Step1:有监督微调(Supervised Fine Tune,SFT)
(1)OpenAI委托40人标注团队设计包含三类内容(简单任务、few-shot任务、基于用户需求的任务)的提示样本prompt dataset。
(2)委托标注团队对prompt dataset 进行标注(本质上是人工回答问题),由此构成<问题,回答> 对数据集。
(3)通过SFT数据集对GPT-3.5模型进行有监督训练微调。

Step2:奖励模型(Reward Model)训练
(1)任务采样:抽样出一个prompt问题及SFT模型的k个输出结果。
(2)结果排序:标注员将这k个结果按质量好坏排序,形成𝐶𝑘2组训练数据对({sample,reward} pairs)。
(3)RM训练:使用𝐶𝑘2组训练数据对({sample,reward} pairs)训练奖励模型,使其更加理解人类偏好。
 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
Step3:近端优化算法(Proximal Policy Optimization,PPO)进行强化学习
针对每个问题,采用RM对模型输出的结果进行打分,打分结果再通过PPO算法对模型参数进行更新,持续迭代优化,使生成结果更加无偏见和符合人类预期。
ChatGPT是LLM领域技术的集大成者,从技术路径的演进过程来看,其底层技术可视为「Transformer+RLHF+PPO+Prompt-Learning+Instruction-tuning+思维链」的融合。
(1)Tansformer:2017年6月,Google发表论文《Attention Is All You Need》,提出Transformer模型。
(2)RLHF:2017年7月,DeepMind(Google)与OpenAI联合发表论文《Deep Reinforcement Learning from Human Preferences》,提出RLHF方法。
(3)PPO:2017年8月,OpenAI发表论文《Proximal Policy Optimization Algorithms》,提出对TRPO算法改进的PPO算法。
(4)Prompt-Learning :2020年7月,OpenAI发表论文《Language Models are Few-Shot Learner》,开启基于Prompt的NLP新学习范式的研究热潮。
(5)Instruction-tuning:2021年9月,Google发表论文《Finetuned Language Models are Zero-shot Learners》,提出指示微调(Instruction-tuning)方法。
(6)思维链:2022年4月,Google发表论文《Pathways: Asynchronous Distributed Data flow for ML》,提出PaLM(Pathways Language Model)模型,并提出思维链(Chain-of-Thought Prompting)技术。
从各项技术的提出时间和提出者来看,ChatGPT融合的各项技术不仅由OpenAI独立提出,还包括Google、DeepMind等公司的研究成果。
5、GPT-4
2023年3月15日,OpenAI目前最强大的多模态预训练大模型GPT-4正式发布,可以实现更为丰富的具体场景应用和问题解决,例如:
(1)输入一张图片并提出和图片相关的问题,可基于图片给出准确的回答。
(2)有更强的高级推理能力,能够回答出ChatGPT不能回答的更为复杂的逻辑问题。
(3)给出一道物理题和相应示意图,可给出具体的解题步骤和相应答案。
(4)给出论文截图,可总结出论文的主要内容,并根据用户进一步的提问补充其中的细节。
(5)给出一张具有相关数据信息的图表,并提出一个和图表数据相关的问题,可识别出图表中对应的数据,给出问题的处理步骤和处理结果。
GPT-4在评估语言模型的传统基准上同样效果卓越,测试基准涵盖问题多选、常识推理、代码、阅读理解、数学问题等,测试结果大大优于GPT-3.5,以及之前最先进的(SOTA)模型,甚至超过了某些在特定测试标准上训练过的模型。
OpenAI分别对GPT-4和GPT-3.5在多个人类考试上进行测试,结果显示在大多数考试中,尤其是与数学和推理相关的考试中,GPT-4相比于GPT-3.5有显著提升,在学术和专业测试中甚至能够达到与人类相当的水平。
在将GPT集成至New Bing后,2023年3月16日,微软发布基于GPT-4的Microsoft 365 Copilot,将AI技术集成到Word、Excel、Powerpoint、Outlook、Teams等日常生产力工具中,使用户能从繁琐事务中解放。
2023年3月23日,OpenAI宣布推出插件功能Plugins,并允许第三方在GPT模型内创建插件,帮助GPT访问最新信息、进行计算或使用第三方服务,并开放了网络浏览器、代码解释器两个OpenAI自己的插件。
开放内部插件,可理解为用插件拓展GPT模型自身能力的边界,一旦形成第三方插件生态系统,GPT模型将成为AI时代的操作系统本身,可以将其视作围绕AI展开的操作系统或底层平台,类比移动互联网时代诞生的操作系统iOS或Andriod。
四、OpenAI
2015年,Elon Musk和硅谷孵化器Y Combinator投资人Sam Altman等人共同创立OpenAI nonprofit,使命为确保通用人工智能(AGI),即一种高度自主且在大多数具有经济价值的工作上超越人类的系统,为全人类带来福祉。
2018年,由于和Tesla的关联越来越深,外界越发担忧特斯拉运用OpenAI的技术实现系统和产品升级,马斯克于2018年离开OpenAI董事会,转为赞助者和顾问。
目前,OpenAI董事会由董事长兼总裁Greg Brockman(前Stripe首席技术官)、首席执行官Sam Altman、首席科学家Ilya Sutskever(前Google Brain研究科学家)等人组成。
OpenAI网罗了整个硅谷最好的AI人才,2020年开始,就有大量Google的人才加入OpenAI,Jan Leike(Alighment负责人),Co-Founder Alec Radford ,以及CoT负责人等多个重要角色均来自Google Brain和Deepmind。
2019年,在训练模型的高成本压力下,OpenAI划分出有利润上限的盈利性组织OpenAI LP,随后微软宣布为OpenAI注资10亿美元,并获得了将OpenAI部分AI技术商业化、赋能产品的许可。
2023年1月,微软宣布将以290亿美元估值,向OpenAI追加投资100亿美元,如谈判达成,微软将持有OpenAI49%的股权,OpenAI的非营利性母公司持有2%,其余投资者持有剩余49%。
目前微软已宣布将旗下所有产品线整合GPT,除Bing和Office外,微软将在Azure云平台整合GPT。
五、抓住智能革命的机会
关注我基金账号早的都知道,在ChatGPT横空出世的12月,我就开始研究GPT产业链,最看好算力,看好NVIDIA,也看好集数据+算法+模型+应用一体的大厂。
科技史一直以来都是「人类+机器」,淘汰「人类」的一个过程。
工业革命如此,智能革命也会如此。
每一次新科技出现,总有人害怕,或者诋毁。
其实可以试着先去了解、去试用,然后再作评价。
别总是摸着自己脑后的辫子,感叹八角笼遛鸟才是真正的人生。
有些人,20岁就已经「死亡」。
智力巅峰和人生熵值最低的时刻,可能是在高考的那一天。
习惯于路径依赖,不愿跳出舒适区,往后的一生,其实只是在重复地过某一天。
而ChatGPT的出现,带来了太多的不确定性。
害怕是理所当然的,因为旧时代的残党,新世界没有载他们的船。
见证利益重构的时代,于年轻人,当然是利大于弊,这一次智能革命,一定程度上是自我升迁的一次重大机会。
「Old Money」最怕什么?最怕创新。
只有创新,年轻人才有机会把老钱干翻。

