
在数据科学项目中,数据预处理阶段往往决定着后续分析的质量和模型的性能。但是分布识别这一关键步骤经常被从业者忽视。在构建预测模型或执行假设检验之前,正确识别数据的潜在分布特征是确保分析结果可靠性的基础工作。
数据分析的成功很大程度上取决于对数据特征的准确理解。正如在工程项目中需要根据不同的环境条件选择合适的材料和工具,数据分析也需要根据数据的分布特征选择相应的统计方法。错误的分布假设会导致分析结果偏差,进而影响决策的准确性。
许多数据分析从业者习惯性地跳过分布识别步骤,直接将数据输入到流行的机器学习算法中。虽然这种做法在某些情况下可能偶然获得良好效果,但更多时候会产生表面上令人满意但实际上缺乏统计意义的结果。
分布概念的基础理解统计分布描述了随机变量可能取值的概率模式。每个数据集都存在特定的分布模式:数值可能围绕中心值对称分布(如正态分布),也可能呈现右偏或左偏的不对称模式(如指数分布或对数正态分布),或者在特定范围内均匀分布。
理解数据的分布特征对于统计分析具有重要意义。它不仅决定了适用的统计检验方法,还影响着模型参数的估计精度和预测结果的可靠性。选择与数据分布特征匹配的分析方法,是获得准确统计推断的前提条件。
直方图:分布识别的起点直方图是最直观的分布可视化工具。通过将数据按照一定区间进行分组,并统计各区间内的频数,直方图能够清晰地展示数据的分布形态。
制作有效的直方图需要注意以下几个关键特征:钟形对称分布通常表明数据遵循正态分布;右偏分布(长尾向右延伸)可能符合指数分布或伽马分布;相对平坦的分布形态暗示均匀分布的可能性;多峰分布则提示数据可能来源于多个不同的群体。
以下代码演示了如何创建专业的直方图进行分布识别:
import matplotlib.pyplot as plt import numpy as np # 创建示例数据data = np.random.normal(50, 15, 1000) # 1000个观测值,均值50,标准差15 # 绘制专业直方图plt.figure(figsize=(10, 6)) plt.hist(data, bins=30, color=skyblue, edgecolor=black, alpha=0.7) plt.xlabel(Values) plt.ylabel(Count) plt.title(What Does Our Data Look Like?) plt.grid(True, alpha=0.3) plt.show()
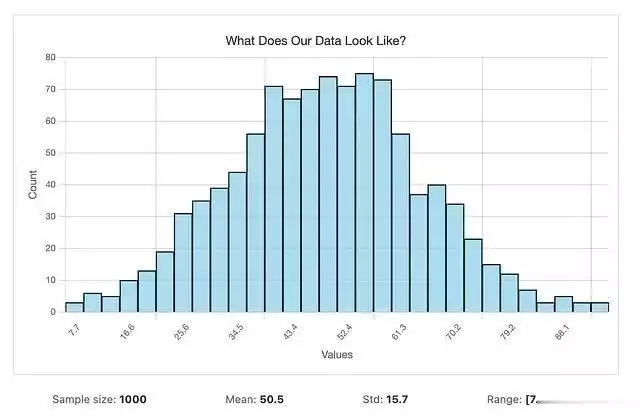
在分析直方图时,需要特别注意区间数量的选择对分布形态的影响。真实的分布模式在不同的区间划分下应该保持相对稳定,而由随机噪声产生的伪峰值则会随着区间数量的变化而消失或移动。
在不同分布类型之间切换观察形态变化,调整样本大小以观察模式的稳定性,改变直方图区间数量以识别真实峰值和噪声峰值的差异,启用理论拟合曲线以评估数学模型与实际数据的匹配程度。
当理论拟合曲线与直方图存在明显差异时,应该优先相信数据的实际表现而非统计假设。
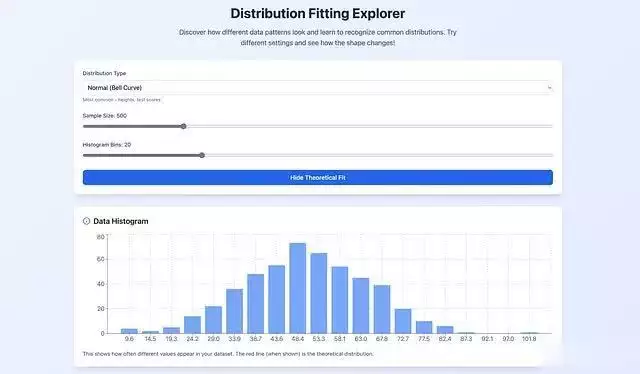
建立系统化的分布识别流程对于提高分析的准确性和效率至关重要。
首先,通过直方图获得数据分布的总体印象,识别基本的分布特征。其次,采用参数估计方法将数据与多种理论分布进行比较,包括正态分布、指数分布、伽马分布、贝塔分布等常见分布类型。然后,使用统计检验方法量化每种分布与数据的拟合程度,获得客观的评估指标。最后,综合统计检验结果和业务逻辑,选择最适合的分布模型。
在这个过程中,需要注意统计检验结果只是选择依据之一,分布的业务合理性同样重要。
Python实现:使用distfit库distfit库提供了便捷的分布拟合功能,能够自动测试多种分布类型并返回最佳拟合结果:
from distfit import distfit import numpy as np # 准备数据my_data = np.random.normal(25, 8, 2000) # 2000个数据点 # 初始化分布拟合器fitter = distfit(method=parametric) # 执行分布拟合fitter.fit_transform(my_data) # 查看最佳拟合结果print("Best fit:", fitter.model[name]) print("Parameters:", fitter.model[params])
distfit库的优势在于其能够自动测试约90种不同的分布类型,大大减少了手动比较的工作量。需要注意的是,即使数据来源于特定分布(如正态分布),最佳拟合结果也可能不是预期的分布类型。这种情况可能由于以下原因:样本的随机性导致偏离理论分布,某些分布具有较强的灵活性能够模拟其他分布,不同统计检验方法关注的拟合方面存在差异。
结果验证与可视化统计分析的可靠性需要通过可视化验证进行确认。单纯依赖数值结果可能导致错误判断,因此必须结合图形分析:
import matplotlib.pyplot as plt # 创建对比图表fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6)) # 概率密度函数对比fitter.plot(chart=PDF, ax=ax1) ax1.set_title(Does This Look Right?) # 累积分布函数对比fitter.plot(chart=CDF, ax=ax2) ax2.set_title(Cumulative View) plt.tight_layout() plt.show()
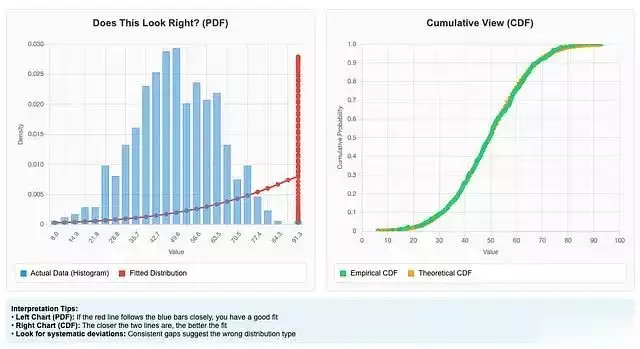
理想的拟合结果应该显示理论曲线与数据直方图具有良好的重合度。如果存在明显偏差,则需要考虑其他分布类型或采用非参数方法。
非参数方法的应用当数据无法满足标准分布假设时,非参数方法提供了更灵活的解决方案。这些方法不假设数据遵循特定的理论分布,而是让数据自身的模式决定分布形态,适用于多峰分布、高度偏斜分布或其他复杂模式:
# 使用非参数方法处理复杂分布flexible_fitter = distfit(method=quantile) flexible_fitter.fit_transform(my_data) # 基于百分位数的方法percentile_fitter = distfit(method=percentile) percentile_fitter.fit_transform(my_data)
非参数方法的优势在于灵活性,但其提供的分布特征信息相对有限,这是在灵活性和解释性之间的权衡。
离散数据的分布拟合对于计数型数据(如网站访问次数、产品缺陷数量、客户投诉次数等),需要采用专门的离散分布拟合方法。离散分布与连续分布在数学性质上存在根本差异,需要使用相应的统计工具:
from scipy.stats import binom # 生成离散计数数据n_trials = 20 success_rate = 0.3 count_data = binom(n_trials, success_rate).rvs(1000) # 拟合离散分布discrete_fitter = distfit(method=discrete) discrete_fitter.fit_transform(count_data) # 可视化结果discrete_fitter.plot()
模型验证与稳健性检验分布拟合结果的可靠性需要通过统计验证来确认。Bootstrap重采样是一种有效的验证方法,通过从拟合分布中重复抽样来评估模型的稳定性:
# 执行Bootstrap验证fitter.bootstrap(my_data, n_boots=100) # 检查验证结果print(fitter.summary[[name, score, bootstrap_score, bootstrap_pass]])
如果选择的分布在多次Bootstrap抽样中都表现出良好的拟合效果,则可以增强对该分布选择的信心。
分布识别的实际应用正确的分布识别为后续分析提供了坚实基础,其应用价值体现在多个方面。
在异常值检测中,了解数据的正常分布模式使得异常点的识别更加准确和可靠。通过计算数据点在已知分布下的概率或标准分数,可以定量地评估其异常程度。
在数据生成和模拟中,准确的分布模型能够生成与真实数据具有相同统计特征的合成数据,这对于模型测试、敏感性分析和场景模拟具有重要价值。
在统计建模中,不同的机器学习算法对数据分布有不同的假设要求。例如,线性回归假设残差服从正态分布,而广义线性模型则适用于指数族分布。选择与数据分布特征匹配的算法能够显著提升模型性能。
在预测分析中,理解历史数据的分布模式有助于更准确地预测未来趋势,并提供预测不确定性的量化估计。
实践经验与建议在实际应用中,需要注意几个重要原则。
首先,不应该盲目选择统计检验得分最高的分布。分布的选择必须结合业务背景和领域知识。例如,人体身高数据通常符合正态分布,而设备故障间隔时间更可能遵循指数分布或威布尔分布。统计方法应该服务于业务理解,而不是相反。
其次,可视化分析与统计检验同样重要。数值结果可能受到样本特征或算法参数的影响,而图形展示通常能够更直观地反映数据的真实特征。当统计检验结果与可视化结果存在矛盾时,应该仔细分析产生差异的原因。
再次,需要认识到所有统计模型都是对现实的简化和近似。分布拟合的目标不是找到"完美"的理论分布,而是找到能够充分捕捉数据主要特征的有用近似。在模型复杂度和实用性之间需要找到适当的平衡点。
最后,简单性原则在统计分析中具有重要价值。如果简单的分布(如正态分布或指数分布)能够合理地拟合数据并满足分析需求,就没有必要追求更复杂的分布模型。过度复杂的模型可能导致过拟合,降低模型的泛化能力。
总结分布识别与拟合是数据分析流程中的基础环节,其质量直接影响后续分析的可靠性和有效性。通过系统化的方法,结合可视化分析、统计检验和领域知识,能够为数据选择合适的分布模型,从而为统计推断、预测建模和决策支持提供坚实基础。
本文介绍的方法和工具涵盖了大多数实际应用场景的需求。从基础的直方图分析开始,逐步深入到参数化和非参数化的分布拟合,再到结果验证和实际应用,形成了完整的技术体系。在实践中,应该根据数据特征和分析目标灵活运用这些方法,始终保持统计严谨性和业务合理性的平衡。
数据分析的成功不在于使用最先进的算法或最复杂的模型,而在于对数据本质特征的深入理解和恰当的方法选择。分布识别正是这一理解过程的关键起点,值得每一位数据分析从业者给予充分重视。
