
本文参考LLaDA:Large Language Diffusion Models
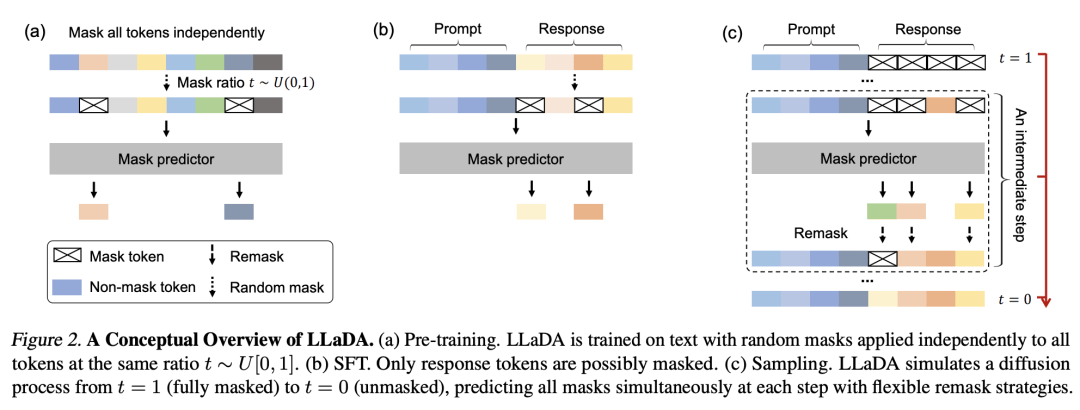
这个图可以很轻松的让没有任何基础的人看懂DLM的工作原理,它会根据问题直接生成一个回答草稿,然后一次次的修改和润色草稿,最终输出回答。
Prompt:Explain what artificial intelligence is.

来源:https://ml-gsai.github.io/LLaDA-demo/
而传统的大模型是一个字一个字的吐,比如我问DeepSeek,跟上面同样的问题,它的回答模式就是线性的,下一个字的输出取决于前面的内容,跟后面的内容没有关系。
这个就是现在最为主流的大模型生成原理,autoregressive modeling (ARM),它的核心公式就是下面,就是根据前面的所有内容预测下个字。
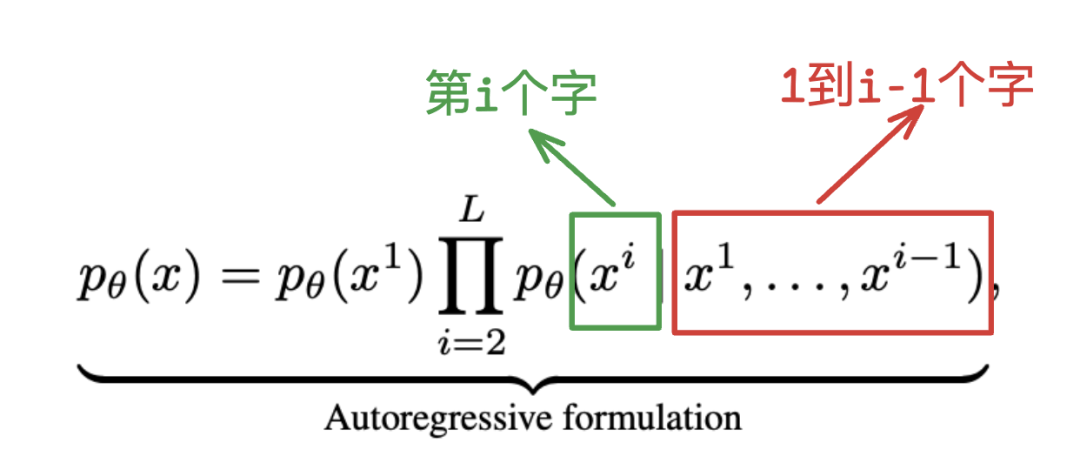
我在介绍ChatGPT原理的时候提到过(从deepseek书里面找)。
而DLM(Diffusion Large language model)走的是非常不一样,但是又比较符合人类直觉的路子。
就比如说高考作文题要求写一篇不少于800字的议论文,“AI的出现给人类带来了什么改变?”
传统的LLM会一个字一个字的往外蹦,也就是线性生成过程。
就比如这个生成了一句话。

下一时刻它生成的就只有一个字,不多不少,就只多一个字。

你可以观察任何一个传统的大模型,DeepSeek,ChatGPT,Qwen,Gemini等等,都是这样的,跳不出这个逻辑,因为它的底层设计就是一个字一个字的往外吐。
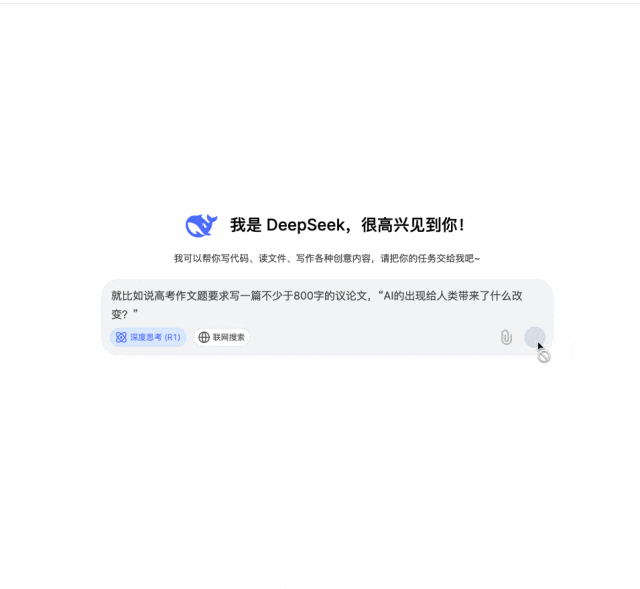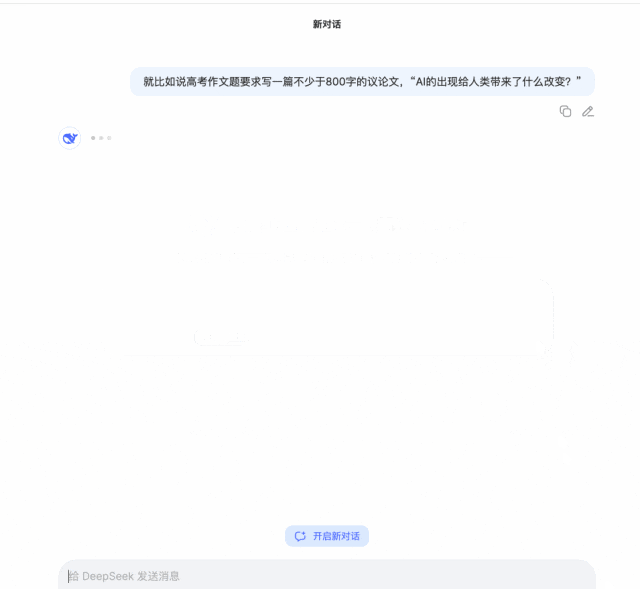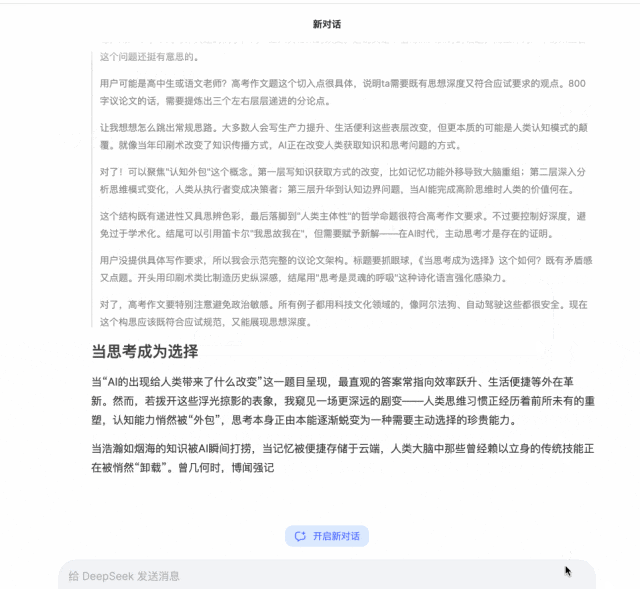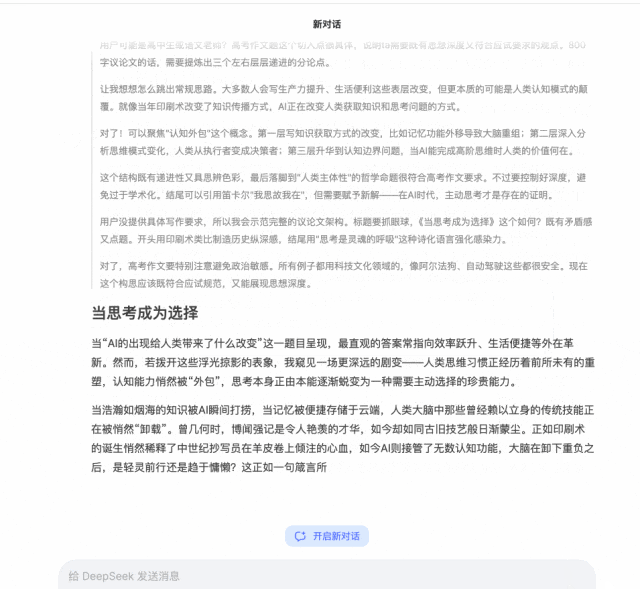
而DLM则是完全不同的逻辑,它是直接生成一篇800字的“文章”,为什么要加引号,是因为这个最初生成的“文章”很有可能狗屁不通,压根不能算做文章。
但是它快呀,你别管它能不能读,反正快是肯定的。
并且它有独特的更新机制,就像下面的这张图,它会一轮轮的迭代更新自己的内容,你看当前时刻可能只确定了一部分的词汇(红色),但是在下一时刻,可能就有更多的内容被确定了出来(绿色)。

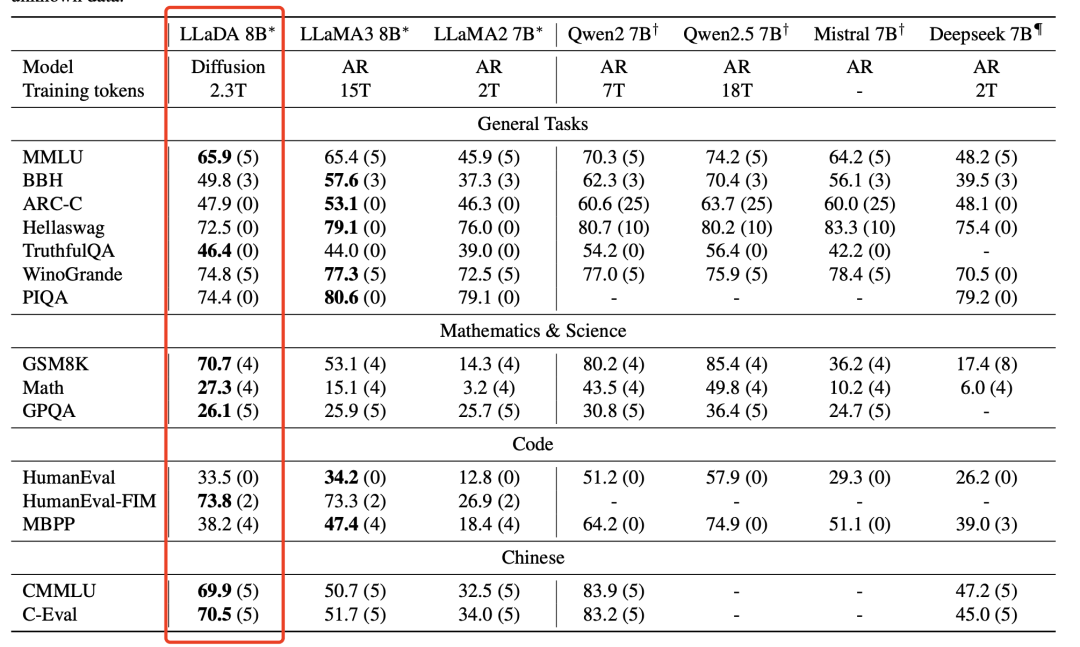
多轮迭代之后,就可以实验整体性的优化,最后实现跟传统大模型类似的结果,你像这个领域的经典工作,LLaDA,在同等模型大小的前提下,在大多数的任务上表现并不比其他的模型差多少。
从结果为导向来看,这也是DLM为什么会吸引关注的主要原因,因为它真的快,传统大模型生成速度再快,也得一个字一个字来。
有些工作虽然在做next two tokens(预测下两个字符),甚至更多的字符,但是进展非常缓慢,并且从直觉来看,DLM明显要比传统大模型更具备可扩展性。
就跟我们写作文的时候,很少时候是一个字一个字的往出蹦想法,而是总体上有个考量,然后甚至会在几个部分想几个金句出来,只不过在最后执行的时候是一个字一个字的写。
油画的创作过程就比较类似,先来一个非常粗略的草稿,然后一层层的上颜色,一次次的涂个几层几十层都不是什么稀罕事。
其实这个正好暗合了DLM中D这个字母所代表的技术,也就是Diffusion,这个技术原本是应用在图像生成(Image generation)上面的,可以说现在绝大多数的图像以及视频生成都是基于这个技术,比如OpenAI的Sora,阿里的Wan通义万相等。
简单来说,就是生成一堆乱七八糟的噪音,然后让AI学习怎么从噪音转换到想要的图片或者视频。

DLM只不过是把脱胎于图像生成的技术应用到了文字生成,所以这也是很多技术到了最后都会兼容的主要原因,单一技术总会存在这样那样的限制,而取众家之长则是必然要走的路。
DLM的核心技术技术其实原理上很直观,不同于LLM的next token prediction,它做的是mask predictor。
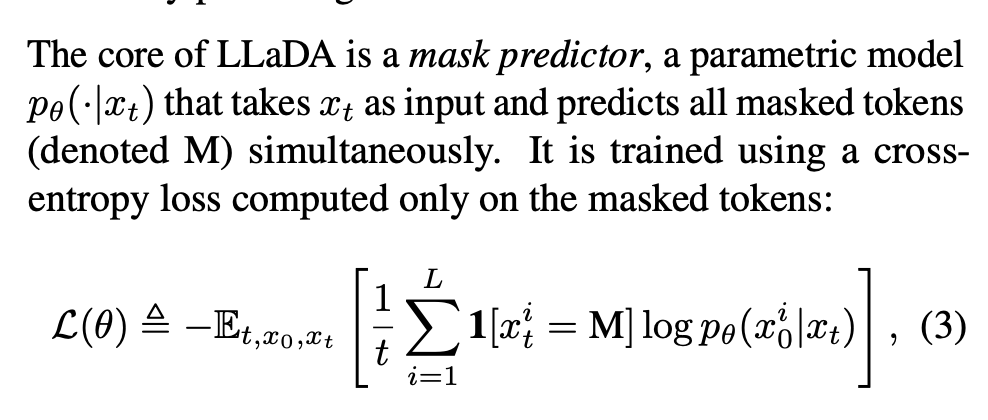
Next token prediction我们之前讲过了,那就是根据现有的句子,预测下一个词,
Mask predictor类似,就是随机的把一段话的部分内容“掩盖”住,这就是Mask的来源,被盖住的内容就叫掩码(masked token)。
比如说在最开始训练的时候,我们提供了一个数据,下面这个基本上大家都知道。
如果是LLM学习的话,它在知道“世上无”这三个字之后,基本上可以稳定输出后面的所有内容,它是线性的。
而DLM不太一样,它会随机“掩盖”几个字,就比如说这样的,然后让大模型去学习怎么去填空。
它可能会这么填,也可能有其他的填法。
但是在一轮轮的训练,迭代,它也能学会这种填空的方法。
正好契合了LLaDA的流程,总体上就是随机掩盖一部分字符,然后去预测这些内容。
最后达到极致,就是直接输出要求的所有内容,只不过是以随机的字符输出,然后在一轮轮的迭代下,生成最终需要的文章。
这篇文章的这个例子很直观,用户了提问了一个简单的数学题:
Lily can run 12 kilometers per hour for 4 hours. After that, she runs 6 kilometers per hour. How many kilometers can she run in 8 hours?
LLaDA在生成回答的时候,颜色深的部分是后面确定的,颜色浅的部分时早些时候确定的。
可以看到非关键信息比如人名Lily,量词hours,很早就确定了下来。而比较关键的数字,特别是4这个数字,以及涉及到运算和逻辑的部分,都是在后面确定的。
也可以从这个案例中看到,DLM在生成内容的时候,在遵循一定的主次关系。返回搜狐,查看更多

