
关注公众号,发现CV技术之美
本篇分享论文『Masked Autoencoders are Robust Data Augmentors』,上交&华为基于MAE提出掩蔽重建数据增强,优于CutMix、Cutout 和 Mixup!代码即将开源!
详细信息如下:

论文地址:https://arxiv.org/abs/2206.04846
代码地址:https://github.com/haohang96/MRA
01
摘要
深度神经网络能够学习强大的表示来解决复杂的视觉任务,但会暴露出诸如过拟合问题之类的不良特性。为此,图像增强等正则化技术对于深度神经网络的泛化是必要的。尽管如此,大多数流行的图像增强方法都将自己局限于现成的线性变换,如缩放、翻转和颜色抖动。由于它们的手工属性,这些增强不足以生成真正的难增强示例。
在本文中,作者提出了一种新的增强视角来规范训练过程。受最近成功将掩蔽图像建模(masked image modeling )应用于自监督学习的启发,作者采用自监督掩蔽自动编码器来生成输入图像的失真视图。利用这种基于模型的非线性变换作为数据增强可以改善高级识别任务。作者将提出的方法称为掩蔽重建增强(Mask-Reconstruct Augmentation,MRA)。在各种图像分类基准上的广泛实验验证了所提出的增强的有效性。具体来说,MRA 不断提高监督、半监督和少样本分类的性能。
02
Motivation
在过去的十年中,计算机视觉见证了深度学习的强大力量。通过骨干模型、训练数据集、优化方法的革命,这种数据驱动的学习方案在图像分类、目标检测和场景分割等各种视觉任务上取得了重大突破。然而,这些方法严重依赖大量数据以避免过度拟合,其中模型通过强制记忆训练数据完美拟合训练数据,但在测试集上表现不佳。
为了缓解过度拟合问题,数据增强被用作常见的训练技巧,以增加训练数据的多样性,特别是对于小规模数据集。主流的训练方法采用基本的图像处理作为数据增强,主要可以表示为线性变换,包括核过滤器、颜色空间变换、几何变换等。这些手动设计的方法可以快速、可重复且可靠地对原始数据集上颜色和几何空间的不变性进行编码。
同时,他们享受标签保留的特性,即对图像进行的转换不会改变高级语义信息。然而,最近关于自监督学习的工作表明,这些低级变换可以很容易地被深度神经网络掌握,这表明这种基本的图像处理方法可能不足以有效地概括输入分布。
一系列工作没有使用传统的图像处理,而是引入了生成对抗网络(GAN)以提高数据增强的质量,这可以看作是一种基于模型的数据增强。GAN 非常强大,可以使用两个对抗网络来执行无监督生成,一个生成自然图像,而另一个将假图像与真实图像区分开来。
合成的图像数据在不方便收集数据集的低数据区域中运行良好,例如医学成像。但是这种样本合成方法不能很好地推广到大规模的标记数据集。根本原因可能是对生成的结果没有保证或定量评估。与原始训练数据相比,看起来不错的复合样本可能具有不同的分布。
相反,获得相邻似然性的模型可能会生成不切实际的样本。结果,生成的对象可能具有任何荒谬的形状和外观,与它们之前的分布有很大不同。因此,GAN 的不确定性和不稳定特性限制了其在图像增强中的应用。因此,需要使生成更可控。这样,就可以合理有效地构建增强图像。
本文遵循基于模型的数据增强,并声称如果以适当的方式约束,基于生成的方法实际上可以提高高级识别。受图像修复的启发,本文的方法称为掩蔽重建增强 (MRA),旨在恢复部分图像,而不是对抗性学习。
具体来说,作者通过自监督掩蔽重建策略预训练了一个极轻量级的自动编码器。Follow最近的自监督方法 MAE,作者首先将图像划分为patch,并从输入图像中掩蔽一组patch,这意味着只有部分图像输入到自动编码器。然后,需要自动编码器在像素空间中重建缺失的patch。
最后,作者将重建图像作为识别视觉任务的增强。通过这种方式,MRA 不仅可以进行强非线性增强来训练鲁棒的深度神经网络,还可以在重建任务的范围内调节具有相似高级语义的生成。为此,可控图像重建是生成相似似然分布的不错选择。换句话说,模型可以生成具有相似语义的鲁棒图像,并使模型能够在不同的识别任务中很好地泛化。在下游评估期间,作者选择性地掩蔽掉注意力值较低的patch,这些patch更有可能是背景。
实验表明,擦除与标签无关的噪声patch会导致更预期和更受约束的生成,这非常有利于稳定训练并增强模型的对象意识。值得注意的是,MRA 的整个预训练过程是无标签的,成本效益高。作者在多个图像分类基准上评估 MRA。MRA 全面获得了优异的实验结果。
具体来说,使用 ResNet-50,仅应用 MRA 即可实现 78.35% 的 ImageNet Top-1 准确度,比baseline提高 2.04%。在细粒度、长尾、半监督和少样本分类上取得了一致的改进,显示了本文方法的强大泛化能力。此外,在对遮挡样本测试模型时,与 CutMix、Cutout 和 Mixup相比,MRA 还显示出很强的鲁棒性,这表明掩蔽自动编码器是鲁棒的数据增强器。
简而言之,本文做出以下贡献:
受图像修复的启发,本文提出了一种称为 MRA 的鲁棒数据增强方法,以帮助规范深度神经网络的训练。通过引入基于注意力的掩蔽策略进一步限制生成,该策略对训练进行降噪并提取对象感知表示。MRA 在一堆分类基准中统一提升了性能,证明了 MRA 的有效性和稳健性。03
方法

在本节中,将介绍本文的 Mask-Reconstruct Augmentation (MRA)。在 3.1 节中,首先回顾基于掩蔽自编码器的预训练框架 。然后,在第 3.2 节中详细介绍了一种基于注意力的掩蔽策略来约束增强。最终,第 3.3 节说明了上图所示的整个pipeline。作者采用预训练的掩蔽自动编码器作为数据增强器,为下游分类任务重建掩蔽输入图像
3.1 Masked Autoencoders
给定未标记的训练集,掩蔽自动编码器旨在学习具有参数的编码器,其中表示patch大小为 16 × 16 像素的逐块二进制掩码。同时,训练一个带有参数的解码器,以从掩蔽图像的潜在嵌入中恢复原始图像:,其中表示重建图像。本文端到端训练编码器 和解码器 ,学习目标是像素空间中重建图像 和原始图像之间的均方误差 (MSE) 。在实践中,作者发现显着压缩自动编码器的模型大小仍然能够达到一个相当高的性能。因此,为了在速度和性能之间取得理想的平衡,作者设计了一个迷你版的掩蔽自动编码器,在将其与 ResNet-50 集成以进行下游分类时,在一个 NVIDIA V100 GPU 上实现了 963 imgs/s 的吞吐量,就整个训练而言,这是负担得起的。3.2 Attention-based Masking
为了指导增强对象感知,本文将对象位置的归纳偏差利用到mask策略中。作者采用注意力探测作为合理的判断来确定patch是否属于前景对象。并将高度注意力的patch作为输入,并删除其余的patch。给定预训练的编码器,可以计算每个输入patch的注意力图。为了适应视觉Transformer的输入格式,输入图像被划分为不重叠的patch ,其中 (H, W ) 表示图像的高度和宽度输入图像,C 表示通道维度,p 表示patch大小。最近的研究表明,在没有监督的情况下训练的视觉Transformer可以自动学习与对象相关的表示。此外,CLS token的注意力图可以提供可靠的前景建议。在此观察的驱动下,作者计算图像patch i 上的CLS token的注意力图: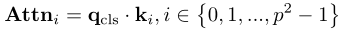 其中是CLS token的查询,制定了patch i 的键嵌入。和都是从编码器的最后一个block中获取的。然后,作者对注意力图进行排序并得到前 k 个索引集:
其中是CLS token的查询,制定了patch i 的键嵌入。和都是从编码器的最后一个block中获取的。然后,作者对注意力图进行排序并得到前 k 个索引集: 其中函数返回前 k 个最大元素的索引。将 top-k 索引设置为,并生成一个基于注意力的二进制掩码为:
其中函数返回前 k 个最大元素的索引。将 top-k 索引设置为,并生成一个基于注意力的二进制掩码为: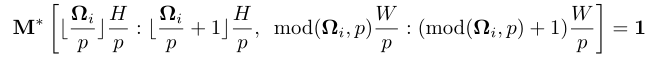 其中表示向下舍入运算,而 mod(·) 表示模运算。在输入图像 x 上应用基于注意力的二进制掩码 后,作者期望可能的背景区域被抹去,而前景区域则完好无损。注意,仅在下游任务期间利用基于注意力的掩蔽策略,而在预训练自动编码器阶段继续随机掩蔽patch。
其中表示向下舍入运算,而 mod(·) 表示模运算。在输入图像 x 上应用基于注意力的二进制掩码 后,作者期望可能的背景区域被抹去,而前景区域则完好无损。注意,仅在下游任务期间利用基于注意力的掩蔽策略,而在预训练自动编码器阶段继续随机掩蔽patch。
3.3 Mask-Reconstruct Augmentation
MRA 的最终架构如上图所示。使用基于注意力的二进制掩码,作者首先获取掩蔽图像。然后,划分掩蔽图像成不重叠的patch并丢弃mask patch。剩余的可见patch被送入预训练的编码器和解码器以生成重建图像。重建后的图像可以看作是的增强版本,可用于多种分类任务。注意,一旦经过预训练,MRA是固定的,并且在对不同的数据集和任务进行测试时不需要进一步微调,它仍然可以生成稳健且可信的增强。04
实验 如上表所示,MRA 使用 ResNet-50 作为主干实现了 78.35% 的 top-1 准确率,优于一系列自动增强搜索方法。作者还比较了 ImageNet 上预训练和预搜索的 GPU 小时数,与 AutoAugment 和 Fast AutoAugment 相比,MRA 也具有可承受的计算成本。此外,一旦经过预训练,MRA 就可以应用于多个分类任务,而无需额外的微调。CutMix及其变体可以通过引入样本间正则化来获得更好的结果。MRA 还可以与 CutMix 结合使用以进一步提高性能。通过结合 CutMix,MRA 在 ImageNet 上达到 78.93% 的 top-1 准确率,优于精心设计的混合策略。
如上表所示,MRA 使用 ResNet-50 作为主干实现了 78.35% 的 top-1 准确率,优于一系列自动增强搜索方法。作者还比较了 ImageNet 上预训练和预搜索的 GPU 小时数,与 AutoAugment 和 Fast AutoAugment 相比,MRA 也具有可承受的计算成本。此外,一旦经过预训练,MRA 就可以应用于多个分类任务,而无需额外的微调。CutMix及其变体可以通过引入样本间正则化来获得更好的结果。MRA 还可以与 CutMix 结合使用以进一步提高性能。通过结合 CutMix,MRA 在 ImageNet 上达到 78.93% 的 top-1 准确率,优于精心设计的混合策略。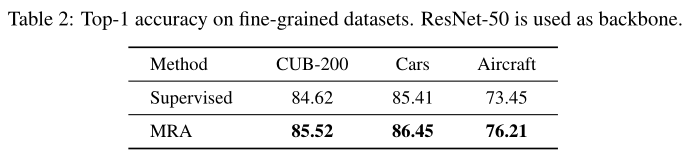 作者还评估了 MRA 在几个细粒度分类数据集上的泛化,包括 CUB-200-2011、FGVC-Aircraft和 StanfordCars。对于所有实验,从 PyTorch提供的官方预训练checkpoint对 ResNet-50 进行了 90 个 epoch 的微调。 作者在运行baseline监督实验和 MRA 实验期间保持超参数完全相同,以确保比较是公平的。如上表所示,MRA 不断提高细粒度分类的性能。
作者还评估了 MRA 在几个细粒度分类数据集上的泛化,包括 CUB-200-2011、FGVC-Aircraft和 StanfordCars。对于所有实验,从 PyTorch提供的官方预训练checkpoint对 ResNet-50 进行了 90 个 epoch 的微调。 作者在运行baseline监督实验和 MRA 实验期间保持超参数完全相同,以确保比较是公平的。如上表所示,MRA 不断提高细粒度分类的性能。 作者进一步在长尾分类上评估MRA。本文使用两种平衡采样方法用作baseline:Instance-Balanced 和 Class-Balanced。在简单的 RandomResizedCrop 增强后,MRA 直接应用于 224 × 224 图像。ResNeXt50被用作一致性的主干。如上表所示,MRA在两种不同的设置下提高了长尾分类准确率,验证了其有效性。
作者进一步在长尾分类上评估MRA。本文使用两种平衡采样方法用作baseline:Instance-Balanced 和 Class-Balanced。在简单的 RandomResizedCrop 增强后,MRA 直接应用于 224 × 224 图像。ResNeXt50被用作一致性的主干。如上表所示,MRA在两种不同的设置下提高了长尾分类准确率,验证了其有效性。 半监督分类侧重于深度学习中的label-hungry设置。在半监督学习中,只有一小部分样本被标记,其余样本未标记。FixMatch是半监督分类中的一种强大的baseline方法,它创建一个图像的两个增强版本。特别是,一个用弱增强处理(RandomResizedCrop),另一个用强增强处理(RandAugment)。该模型经过训练以最大化两个增强图像之间的一致性。MRA 的重建图像也可以看作是原始输入的强增强版本。作者提出使用 MRA 的重建图像作为 FixMatch 中的一种强增。如上表所示,在 FixMatch 中使用 MRA 增强明显优于标准强增强,即RandAugment,这验证了 MRA 在不同应用中的有效性。
半监督分类侧重于深度学习中的label-hungry设置。在半监督学习中,只有一小部分样本被标记,其余样本未标记。FixMatch是半监督分类中的一种强大的baseline方法,它创建一个图像的两个增强版本。特别是,一个用弱增强处理(RandomResizedCrop),另一个用强增强处理(RandAugment)。该模型经过训练以最大化两个增强图像之间的一致性。MRA 的重建图像也可以看作是原始输入的强增强版本。作者提出使用 MRA 的重建图像作为 FixMatch 中的一种强增。如上表所示,在 FixMatch 中使用 MRA 增强明显优于标准强增强,即RandAugment,这验证了 MRA 在不同应用中的有效性。 在few-shot learning中,首先在一些基本类别上给出大量标记的训练样本,然后目标是在只有少数K-shot样本被标记的新类别上进行预测。基本类别和新颖类别不重叠。作者在 miniImageNet 数据集上评估少样本分类。最近的工作提出了一种简单但有效的baseline方法,用于少样本分类,其中主干在基本类别上以完全监督的方式进行预训练,并且分类器在固定主干上的新类别上重新训练。基于此baseline,作者在基础类别的预训练阶段应用 MRA,而后续新类别的再训练阶段保持不变。如上表所示,与baseline方法相比,使用 MRA 预训练的模型在新类别上表现出更强的泛化能力。
在few-shot learning中,首先在一些基本类别上给出大量标记的训练样本,然后目标是在只有少数K-shot样本被标记的新类别上进行预测。基本类别和新颖类别不重叠。作者在 miniImageNet 数据集上评估少样本分类。最近的工作提出了一种简单但有效的baseline方法,用于少样本分类,其中主干在基本类别上以完全监督的方式进行预训练,并且分类器在固定主干上的新类别上重新训练。基于此baseline,作者在基础类别的预训练阶段应用 MRA,而后续新类别的再训练阶段保持不变。如上表所示,与baseline方法相比,使用 MRA 预训练的模型在新类别上表现出更强的泛化能力。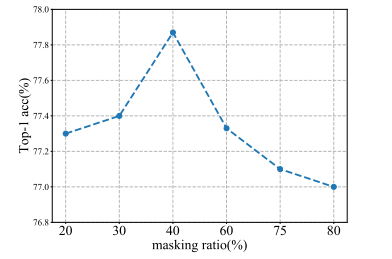 为了检查掩蔽率如何影响增强质量,作者将掩蔽率从 20% 到 80% 范围内消融。在图上 中报告了结果。它表明在 40% 的比率下预训练的 MAE-Mini 达到了最佳性能。作者推测较小的模型可能无法在较高的掩蔽率下很好地收敛。然而,极小的掩蔽率也会使预训练任务过于简单,这可能会影响预训练的 MAE-Mini 的泛化能力。为了验证强调语义相关patch可以提高模型性能,作者将本文的策略与选择mask高注意力值的patch或随机patch的其他策略进行比较。在上表中报告了相应的分类精度。证明了掩蔽区域的选择对性能有显着影响。
为了检查掩蔽率如何影响增强质量,作者将掩蔽率从 20% 到 80% 范围内消融。在图上 中报告了结果。它表明在 40% 的比率下预训练的 MAE-Mini 达到了最佳性能。作者推测较小的模型可能无法在较高的掩蔽率下很好地收敛。然而,极小的掩蔽率也会使预训练任务过于简单,这可能会影响预训练的 MAE-Mini 的泛化能力。为了验证强调语义相关patch可以提高模型性能,作者将本文的策略与选择mask高注意力值的patch或随机patch的其他策略进行比较。在上表中报告了相应的分类精度。证明了掩蔽区域的选择对性能有显着影响。 上图展示了不同mask策略的可视化结果。如果删除图像中像鸟头这样的高度注意力的patch,由于特定类别区域的模糊性,重建的图像很难识别。它验证了高度注意力的patch作为生成线索可以产生更健壮的原始图像附近。
上图展示了不同mask策略的可视化结果。如果删除图像中像鸟头这样的高度注意力的patch,由于特定类别区域的模糊性,重建的图像很难识别。它验证了高度注意力的patch作为生成线索可以产生更健壮的原始图像附近。 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E) 作者消融了 MAE 的模型大小。如上表所示,在相同的掩蔽率下,采用更大的模型作为增强器带来更高的分类准确率。这并不奇怪,因为更大的模型捕获了更准确的注意力信息并提供了更强的正则化。但是,大型 MAE 模型的显存和速度成本是无法承受的。通过调整掩蔽率,作者表明与 MAE-Large 相比,更小的 MAE-Mini 可以实现更好的性能,速度提高 6 倍,参数减少 95%。Pretraining Epochs 是自监督学习的重要超参数。例如,MoCo-v2 需要 800 个 epoch,MAE 需要 1600 个 epoch 才能与大型模型收敛。作者在上表中比较了不同预训练 epoch 下与 MRA 的分类精度。将预训练 epoch 从 200 扩展到 800 时没有明显差异,这表明 200 epoch 的预训练对于轻量级 MAE-Mini 来说已经足够了。基于注意力的掩蔽和重建是 MRA 中的两个主要步骤。为了证明重建的重要性,作者设计了一个仅mask输入图像的实验。如上表所示,MRA 中基于注意力的mask优于普通的 Cutout 增强。与本文的直觉一致的是,基于注意力的掩蔽可以看作是一种高级的 Cutout。此外,通过重建进一步提高了性能,显示了基于生成的增强的有效性。
作者消融了 MAE 的模型大小。如上表所示,在相同的掩蔽率下,采用更大的模型作为增强器带来更高的分类准确率。这并不奇怪,因为更大的模型捕获了更准确的注意力信息并提供了更强的正则化。但是,大型 MAE 模型的显存和速度成本是无法承受的。通过调整掩蔽率,作者表明与 MAE-Large 相比,更小的 MAE-Mini 可以实现更好的性能,速度提高 6 倍,参数减少 95%。Pretraining Epochs 是自监督学习的重要超参数。例如,MoCo-v2 需要 800 个 epoch,MAE 需要 1600 个 epoch 才能与大型模型收敛。作者在上表中比较了不同预训练 epoch 下与 MRA 的分类精度。将预训练 epoch 从 200 扩展到 800 时没有明显差异,这表明 200 epoch 的预训练对于轻量级 MAE-Mini 来说已经足够了。基于注意力的掩蔽和重建是 MRA 中的两个主要步骤。为了证明重建的重要性,作者设计了一个仅mask输入图像的实验。如上表所示,MRA 中基于注意力的mask优于普通的 Cutout 增强。与本文的直觉一致的是,基于注意力的掩蔽可以看作是一种高级的 Cutout。此外,通过重建进一步提高了性能,显示了基于生成的增强的有效性。
05
总结本文提出了一种鲁棒的数据增强方法,Mask-Reconstruct Augmentation (MRA) 来规范深度神经网络的训练。通过 Mask-Reconstruct Augmentation,作者实现了重建原始图像的部分区域来增强原始图像。当只生成mask区域时,增强是可控的且很强的。一堆分类基准中的实验证明了 MRA 的有效性和鲁棒性。尽管本文的工作显示出有希望的结果,但仍然存在一些局限性。这种增强不适用于实例分割等密集预测任务,因为生成增强很容易破坏实例的边界。参考资料
[1]https://arxiv.org/abs/2206.04846
[2]https://github.com/haohang96/MRA
END
欢迎加入「数据增强」交流群👇备注:DA
