(转自:机器之心)
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。现有方法常被两大问题困扰: 决策过程不透明 (“黑箱” 预测)和 拒识能力不足 (对不存在物体输出错误结果)。
 图 1:指代检测的应用场景实例
图 1:指代检测的应用场景实例最近, IDEA 提出全新解决方案 Rex-Thinker ,首次将人类思维中的 “逻辑推理链” 引入视觉指代任务,让 AI 像人一样分步思考、验证证据,在权威测评中不仅准确率显著提升,更展现出强大的 “知之为知之” 能力!

项目主页:
https://rexthinker.github.io/
在线 Demo:
https://huggingface.co/spaces/Mountchicken/Rex-Thinker
Demo 论文地址:
https://arxiv.org/abs/2506.04034
开源代码:https://github.com/IDEA-Research/Rex-Thinker
投稿人:Qing Jiang
投稿团队:IDEA-CVR
突破在哪?让 AI 学会 “思考三步走”
传统模型直接输出目标检测框,而 Rex-Thinker 创新性地构建了可解释的推理框架:
1. 规划 (Planning)拆解语言指令:“找到坐在乌龟上的人” → 分解为 “第一步找到乌龟 → 第二步判断每个人是否坐在乌龟上”
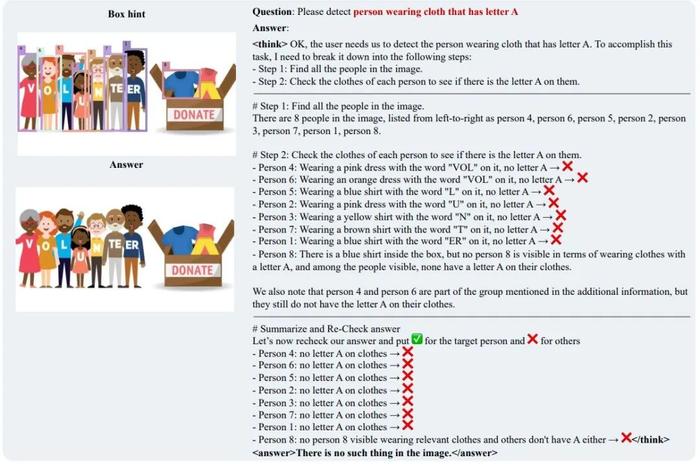
2. 验证 (Action)对每个候选目标(如 “Person 1”“Person 2”)逐步核对子条件, 每一步的分析都绑定图中具体区域 (比如 Person 1 就对应图中标号为 Person 的人) (见图 2)
3. 决策 (Summarization)汇总验证结果,输出匹配目标的坐标或声明 “未找到”
 图 2: Rex-Thinker 推理示例
图 2: Rex-Thinker 推理示例模型结构:基于检索的检测多模态模型设计 + CoT 推理
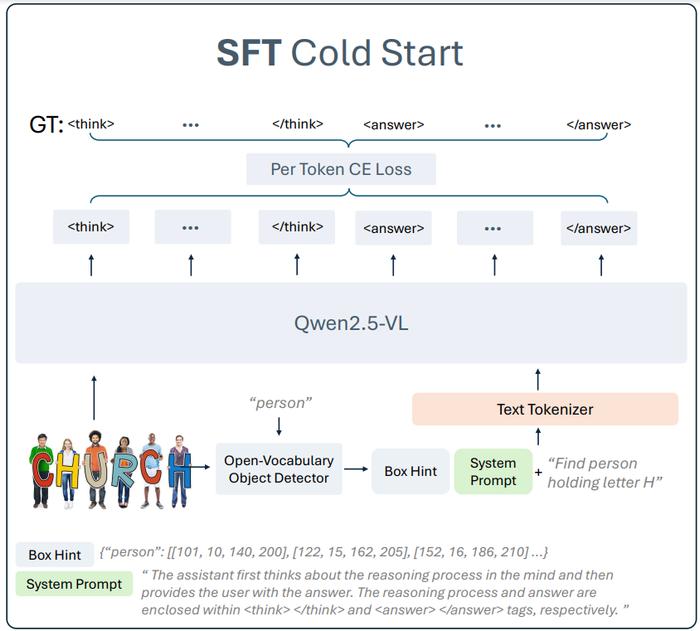 图 3: Rex-Thinker 模型结构
图 3: Rex-Thinker 模型结构如图 3 所示,Rex-Thinker 在模型设计上,采用了基于检索策略,即先通过一个开集检测模型提取出所有的候选框,然后将候选框输入到模型中,然后模型对每个候选框进行推理,最后再输出答案,具体而言每个步骤为:
1. 候选框生成: 使用开放词汇检测器(如 Grounding DINO)提前检测出所有可能的目标区域,作为 Box Hint 输入;
2. 链式推理(CoT Reasoning): 给定候选框,模型逐个对比、推理,生成结构化思考过程
...
和最终答案 …。整个过程的输入 prompt 如下所示: 图 4 . Rex-Thinker 的输入 prompt 构成。
图 4 . Rex-Thinker 的输入 prompt 构成。3. 输出格式:最终输出标准化 JSON 格式的目标坐标,这种设计既规避了直接回归坐标的困难,也让每步推理有图像依据,提升可解释性和推理可信度。
训练流程:SFT 冷启动 + GRPO 后训练,打造强大推理能力
要让 AI 具备像人一样的推理能力,关键在于教会它怎么一步步思考。为此,Rex-Thinker 采用了两阶段训练策略,从构建高质量推理数据集开始。
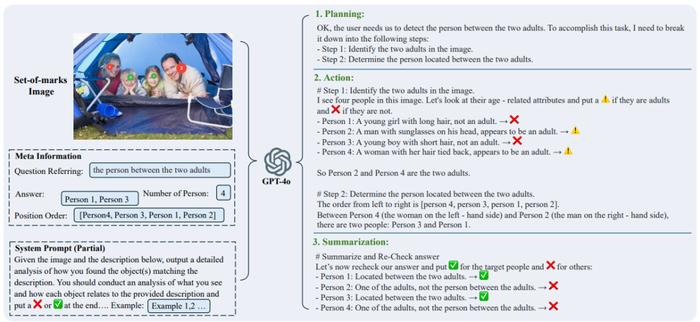 图 5: HumanRef-CoT 数据集构造流程
图 5: HumanRef-CoT 数据集构造流程1. 构建推理数据集 HumanRef-CoT
首先,团队在已有的 HumanRef 数据集(专注多人物指代)基础上,利用 GPT-4o 自动生成了 9 万条链式推理示例,构建了 HumanRef-CoT,主要特点包括:
完整推理链:每条样本严格按照「规划(Planning)- 验证(Action)- 总结(Summarization)」的推理流程生成。
多样化推理场景:覆盖单目标、多目标、属性组合、空间关系、交互行为等复杂描述;
拒答样本:特意加入了无匹配目标的描述,引导模型学会在必要时拒绝作答,提升抗幻觉能力。
这一数据集首次系统性地引入了推理链标注,为训练具有推理能力的视觉指代模型奠定了基础。
2. 两阶段训练策略
 图 6. Rex-Thinker 采用的两阶段训练方法
图 6. Rex-Thinker 采用的两阶段训练方法(1)冷启动训练
首先在 HumanRef-CoT 数据集上进行监督微调(SFT),这个阶段主要帮助模型掌握基本的推理框架和输出规范。
(2)GRPO-based 强化学习后训练
有了基础推理能力后,进入关键的 GRPO 强化学习阶段,进一步提升推理质量与可靠性。通过引入 F1 准确率奖励 + 格式规范奖励 ,让模型自我优化推理路径。这一机制避免了单一推理路径训练可能带来的过拟合问题,促进了模型在推理策略上的多样性和泛化能力。 最终,GRPO 不仅提升了模型的推理精度,还显著增强了面对陌生类别、复杂描述时的鲁棒性和抗幻觉能力。如下图所示,模型在未见过的类别(热狗)也具备推理能力
 图 7. Rex-Thinker 在 GRPO 后训练后泛化到任意物体
图 7. Rex-Thinker 在 GRPO 后训练后泛化到任意物体实验结果: SFT 赋予模型 CoT 能力, GRPO 提升模型泛化能力
在 HumanRef Benchmark 上,Rex-Thinker 展示了显著的性能提升。团队测试了三种模型版本:
Rex-Thinker-Plain:只训练最终检测结果,没有推理监督;
Rex-Thinker-CoT:加入思维链(CoT)监督,学会 “如何思考”;
Rex-Thinker-GRPO:在 CoT 基础上,用 GRPO 强化学习进一步优化推理质量。
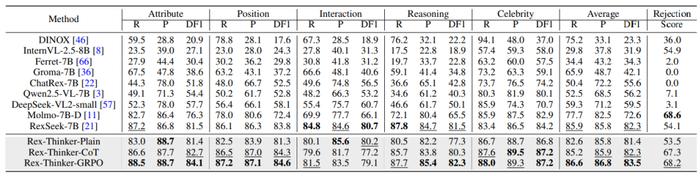 表 1 Rex-Thinker 在 HumanRef Benchmark 上的评测结果
表 1 Rex-Thinker 在 HumanRef Benchmark 上的评测结果如表 1 结果显示,加入 CoT 监督后,模型在各项指标上全面优于基础版本,平均提升 0.9 点 DF1 指标,尤其在 “拒识” 子集上的表现提升尤为明显,Rejection Score 提高了 13.8 个百分点,说明推理链的引入显著增强了模型对 “不存在目标” 的识别能力。进一步地,GRPO 训练在 CoT 基础上带来了额外性能提升,平均 DF1 提升至 83.5。相比单一推理路径的监督学习,GRPO 引导模型通过奖励机制探索更优推理路径,显著改善了复杂场景下的鲁棒性和判断准确性。
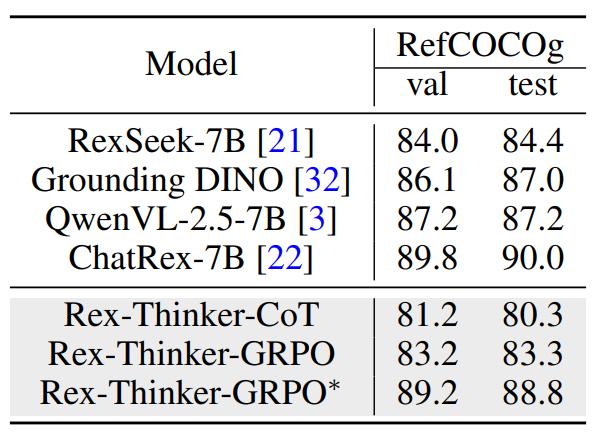 表 2 Rex-Thinker 在 RefCOCOg 数据集上的泛化结果
表 2 Rex-Thinker 在 RefCOCOg 数据集上的泛化结果此外,在 RefCOCOg 数据集上的跨类别评估中,Rex-Thinker 同样表现出良好的迁移能力。在不进行任何针对性微调的情况下,模型仍能准确推理出目标位置,体现出良好的泛化能力。通过对 RefCOCOg 的少量 GRPO 微调,模型性能进一步接近甚至超过现有主流方法,验证了该方法在新类别和新任务中的可拓展性。
可视化结果
我们接下来展示一下 Rex-Thinker 的推理过程可视化,包括、每一步条件验证及最终决策输出。图中显著标注了模型在图像中如何逐步定位目标、如何识别条件是否满足,并最终输出结果或拒绝预测。这些可视化不仅体现了模型良好的目标理解能力,也突出了其推理路径的清晰性与可解释性。特别是在存在多个干扰项或不存在目标的场景中,Rex-Thinker 能够给出详尽的否定推理,展示出 “知之为知之,不知为不知” 的能力。这一能力在传统视觉模型中极为罕见,凸显了思维链机制在实际应用中的价值。