
在介绍GAN之前,我们先简单回顾下之前所介绍的CNN模型:
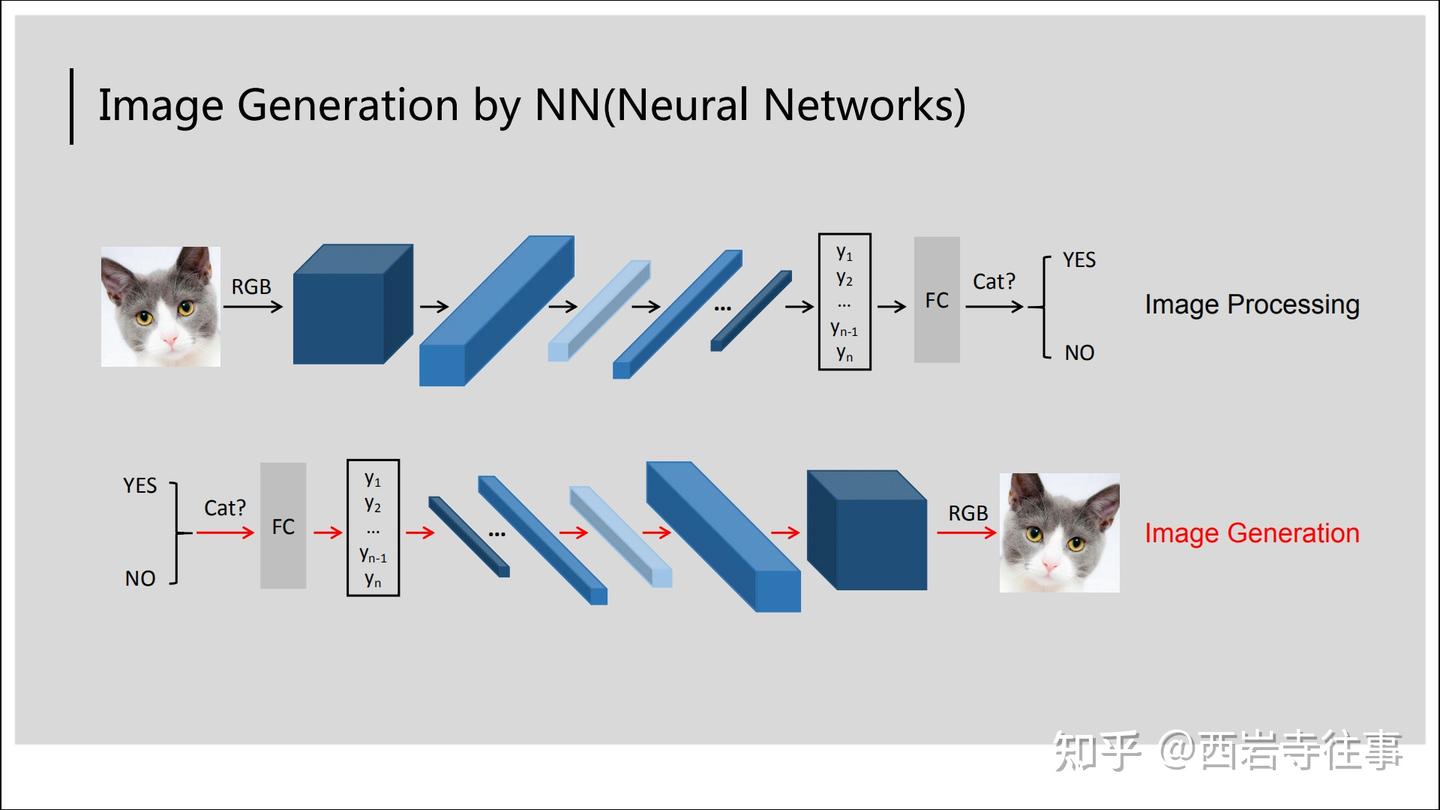
在上图示例中,CNN通过卷积、池化等操作对输入图像进行分析,从而对其进行分类(判定是否为猫),这个过程可以概括为图像处理,即模型输入的图像是确定的、待分析的对象,我们通过各种神经网络来对其进行分析。
与上述过程相反,对于图像生成任务来说,模型的输出才是确定的图像,而模型的输入则是不确定的,具体取决于场景以及特定的模型设计。例如,在图像生成任务的一种特殊应用——风格迁移中,模型的输入可能是一个随机生成的图像[1],参见下图,此时模型的训练过程可以看成是对这个随机生成的图像所对应像素值的更新过程,以期实现较好的风格迁移效果。
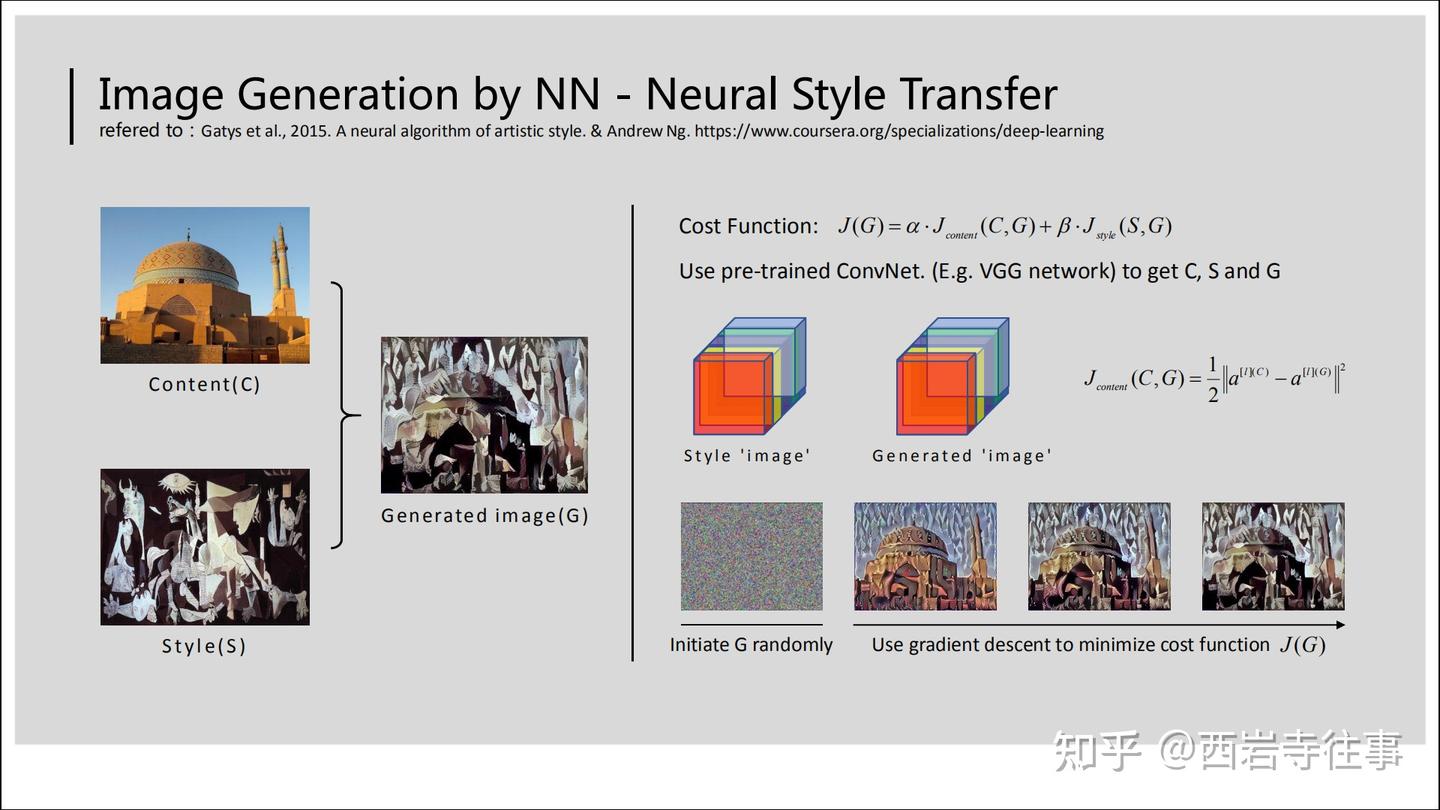
为了对图像生成任务形成更全面的认识,参考图3(基于图1):
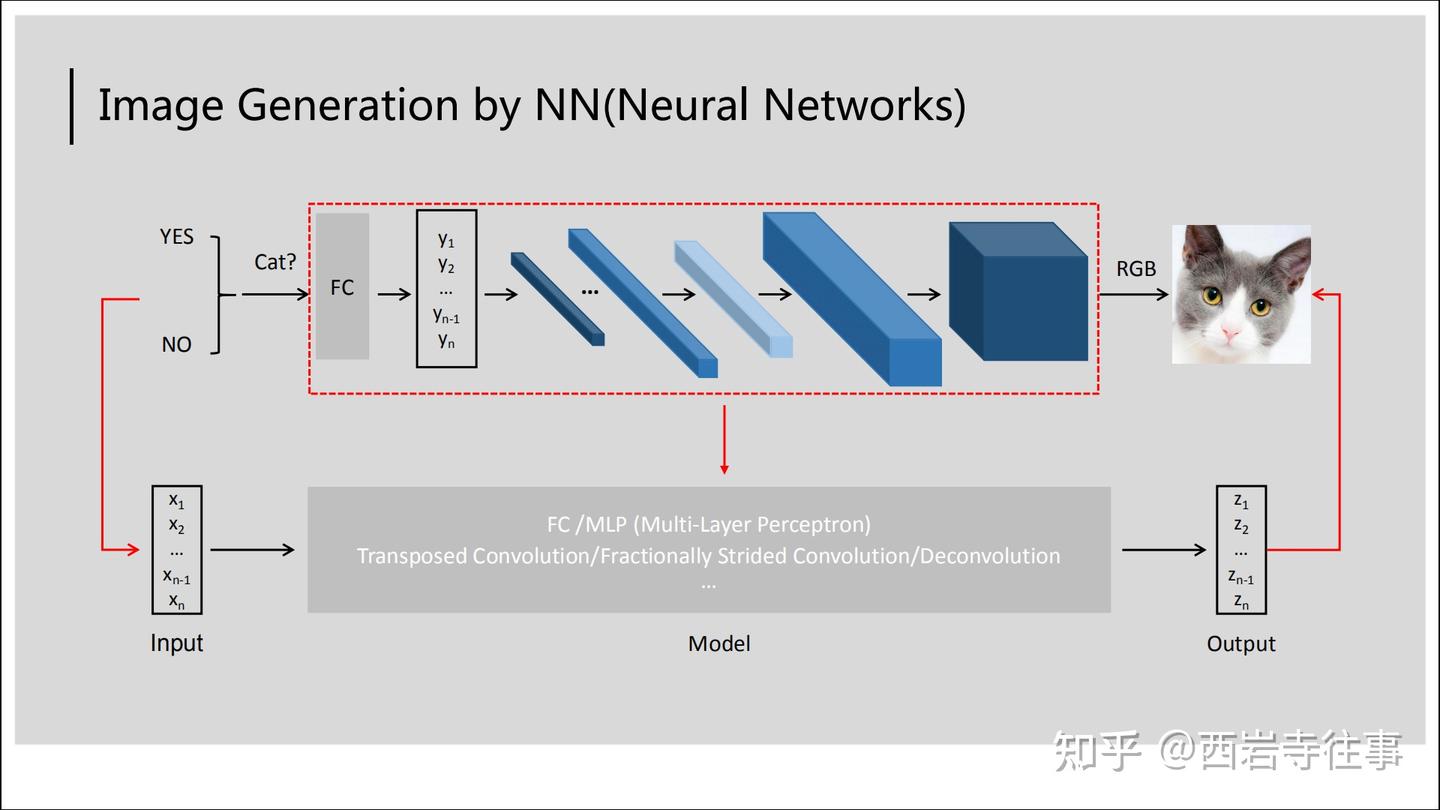
上文中提到,对于图像生成任务来说,模型的输出才是确定的图像,而模型的输入则是不确定的,具体取决于场景以及特定的模型设计。这里为了一般起见,在图3中,将模型输入用一向量表示,对应的模型输出也是一向量。在各种图像生成模型中,一般会涉及FC(全连接神经网络)、转置卷积/分数阶卷积/反卷积等。
对比图1与图3,比较粗略地,可以认为:图像处理任务是将一个较大的输入向量(即“猫”图)转变为一个较小的输出向量(即“是否为猫”的二分类结果);而图像生成任务则与之相反,是将一个较小的输入向量(即“是猫”)转变为一个较大的输出向量(即“猫图”)。

生成对抗网络(Generative Adversarial Nets,GAN)[2]自提出以来,在许多领域中出现大量有趣的应用,如上图显示的抖音漫画变脸的特效。图4中展示了正面与负面的例子,其中后者指生成的漫画风格与拍摄者“风格”差异过大(似乎性别也不一致),这可能跟对应的漫画生成模型有关系,如训练样本的构造、模型的架构等。对应视频在下面:



通过以上铺垫,我们已经建立起以下认知:
图像处理任务利用如CNN的神经网络对输入图像进行分析处理,得到跟输入图像内容相关的信息;与图像处理任务相反,在图像生成任务中,图像生成模型根据输入的跟输入图像内容相关的信息来生成图像;对于图像生成任务来说,图像生成模型的输入是不确定的,具体取决于场景以及特定的模型设计。其中风格迁移就属于其中的一种场景;生成对抗网络(GAN)可以应用于风格迁移。接下来简单介绍GAN的基本原理:
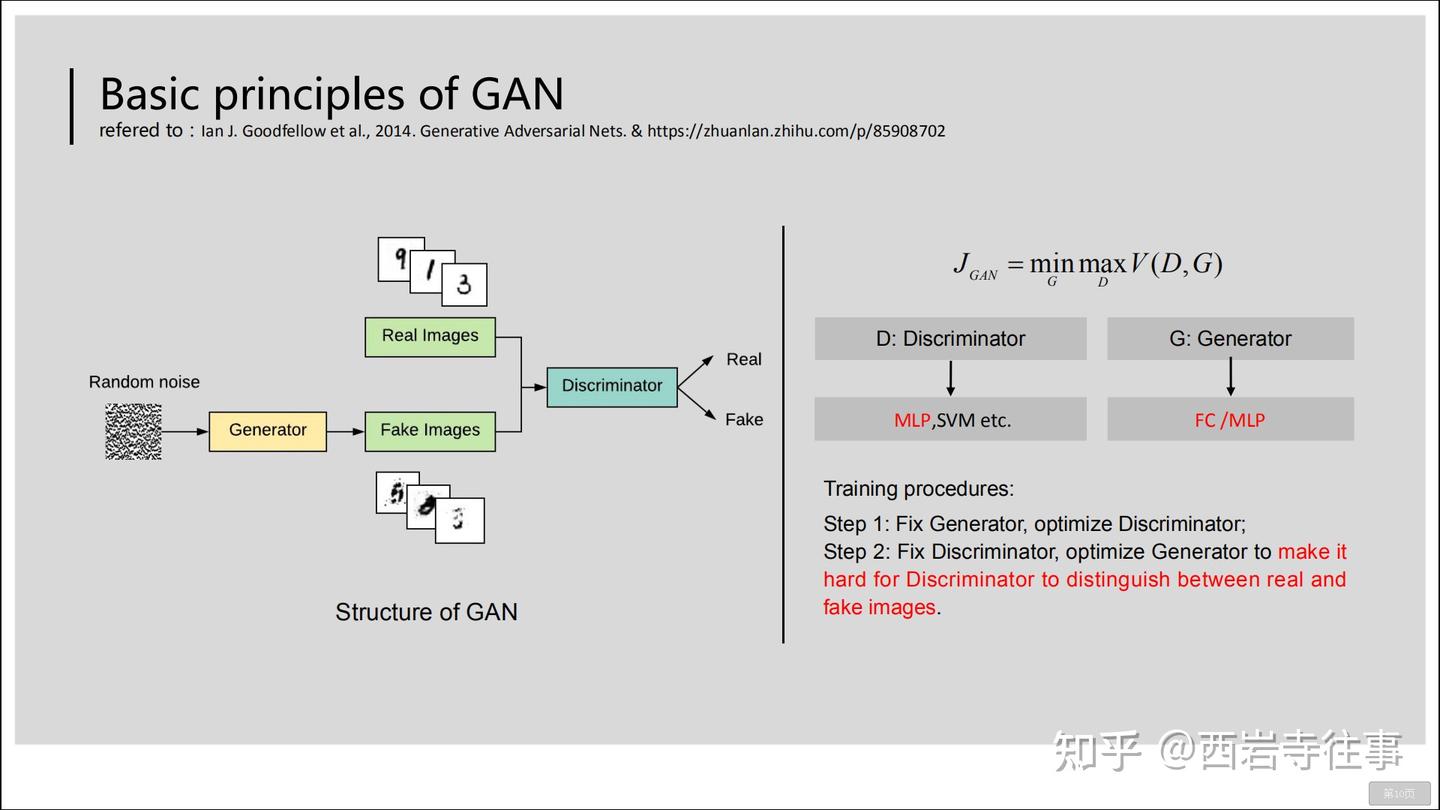
GAN模型中有两个核心的组成:生成器(Generator)与判别器(Discriminator)。参照图5,GAN的判别器与生成器都由多层感知机(可以看成全连接神经网络,即FC)构成[2]。GAN模型的训练过程中,体现“对抗”的关键步骤是:
固定生成器(的参数),训练(优化)判别器,使得判别器能够尽可能准确地区分“真图像“与”假图像“;在完成步骤1之后,固定判别器(的参数),训练(优化)生成器,尽可能使得判别器无法准确地区分“真图像“与”假图像“。在GAN模型训练完成后,我们即可使用经训练的生成器(Generator)来生成图像了。
在图5所参考的文献[2]中,GAN的判别器与生成器都由多层感知机(可以看成全连接神经网络,即FC)构成,它们都可以使用其他类型的神经网络,如卷积神经网络(CNN),如下图所示:
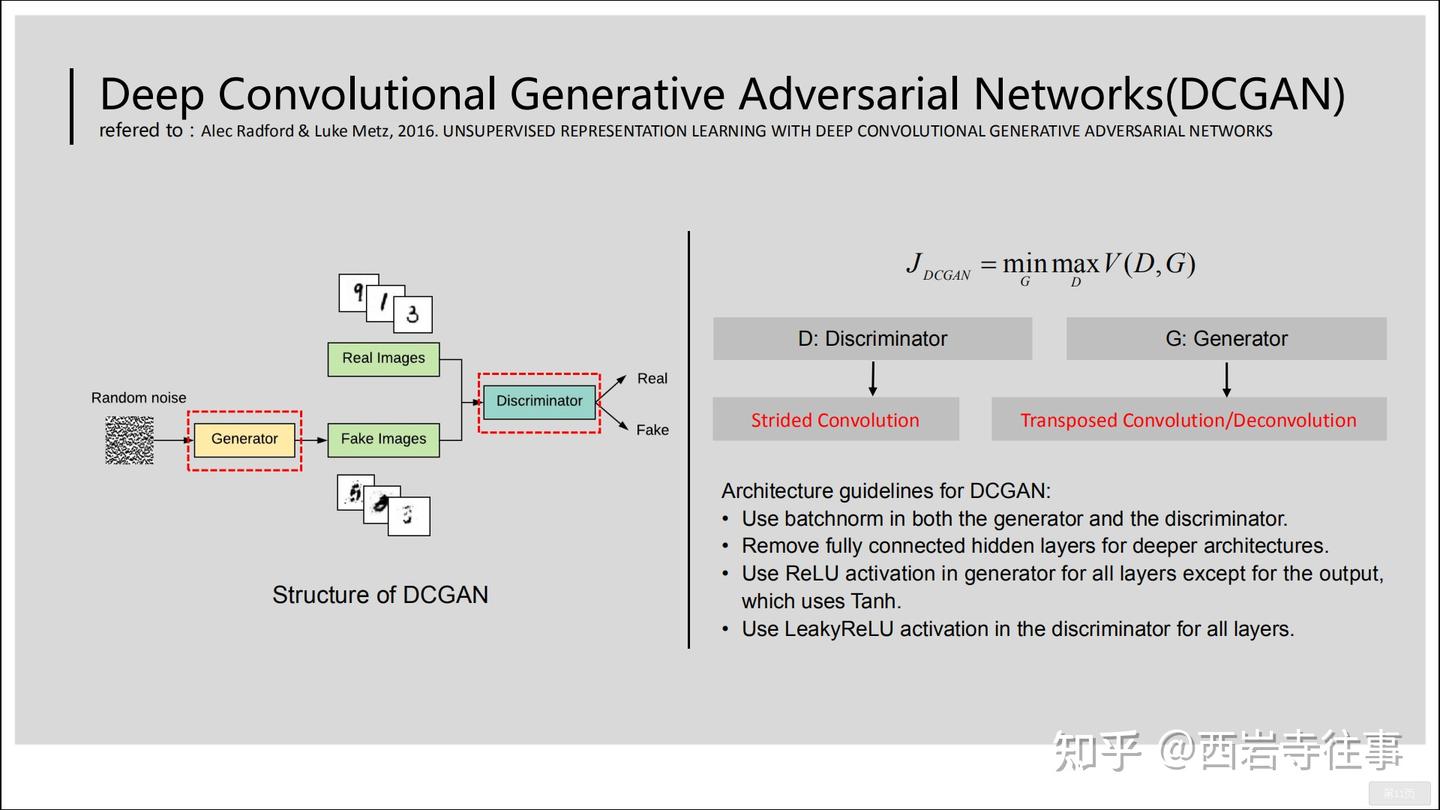
在图6所参考的文献[3]中,判别器使用卷积神经网络(Strided Convolution,普通的卷积运算,若不Padding则会使通道减小),而生成器使用了转置卷积(Transposed Convolution)(也可以看做是反卷积)。
下图具体介绍了DCGAN的生成器所采用的转置卷积的基本过程:
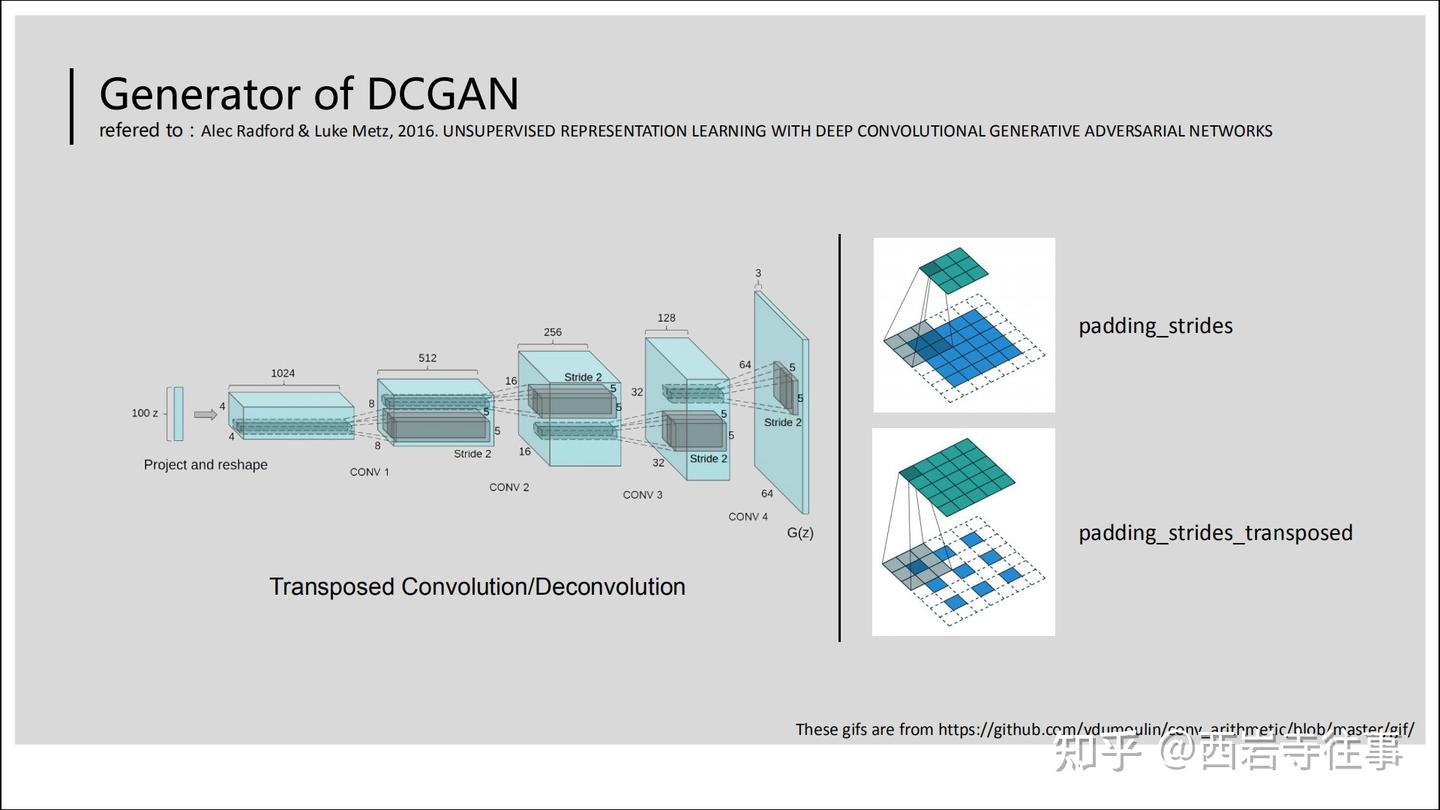
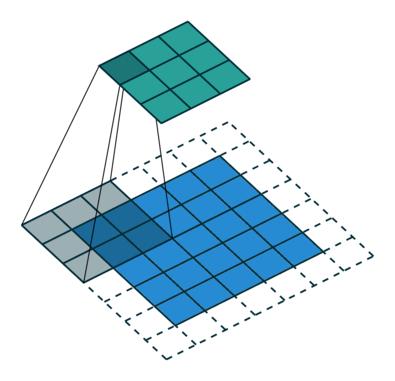
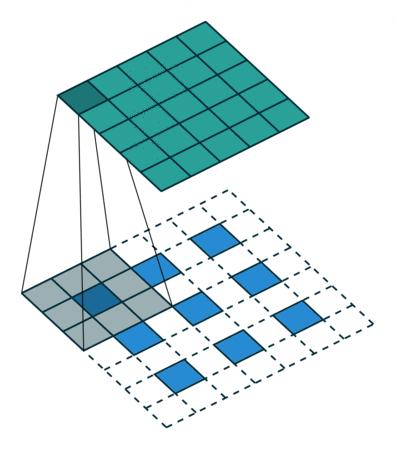
图7中右侧的两个动图具体如下所示(上方的代表普通卷积,下方的则是与之对应的转置卷积过程):
对于GAN而言,其不仅可以用来实现风格迁移,基于其的多种衍生模型应用在各类场景中,如图像增强、图像编辑[4][5]、文字-图像/视频转换[6]等。具体如以下各图所示:

(猜猜他是谁哈哈)
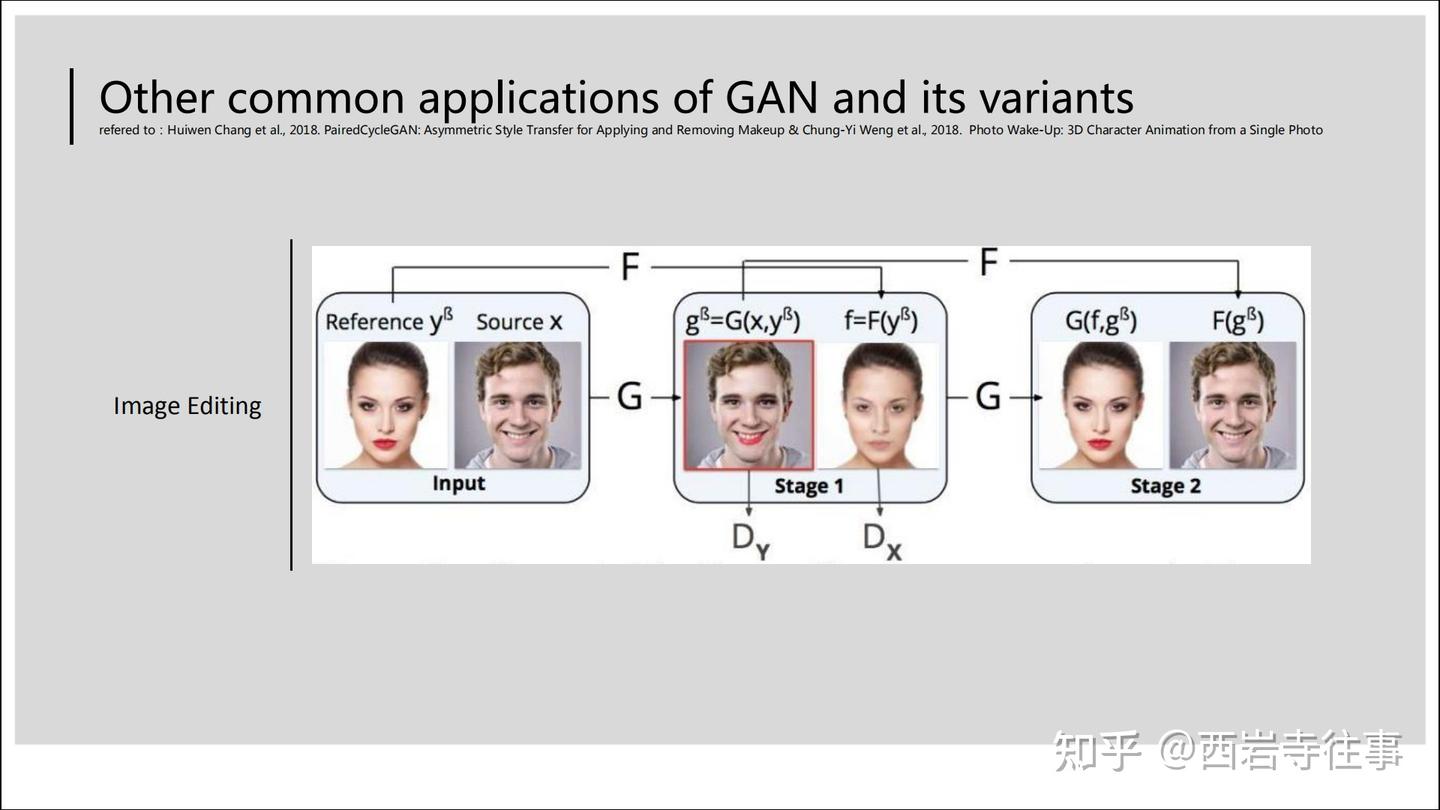
在下文中我们会看到,图9所涉及的模型训练方法[4]和前面的抖音漫画头像生成的所采用的技术[7]是非常类似的。
照明唤醒[5]也是图像编辑应用中一个很好的示例:
GAN应用于文字-图像/视频转换的示例如下图所示:

视频是多个图像(帧)组成的,因此利用文字生成视频实质上就是利用文字生成系列图像的过程。
最后,我们来进一步分析抖音漫画变脸的特效背后所涉及专利[7]的权项(授权前):
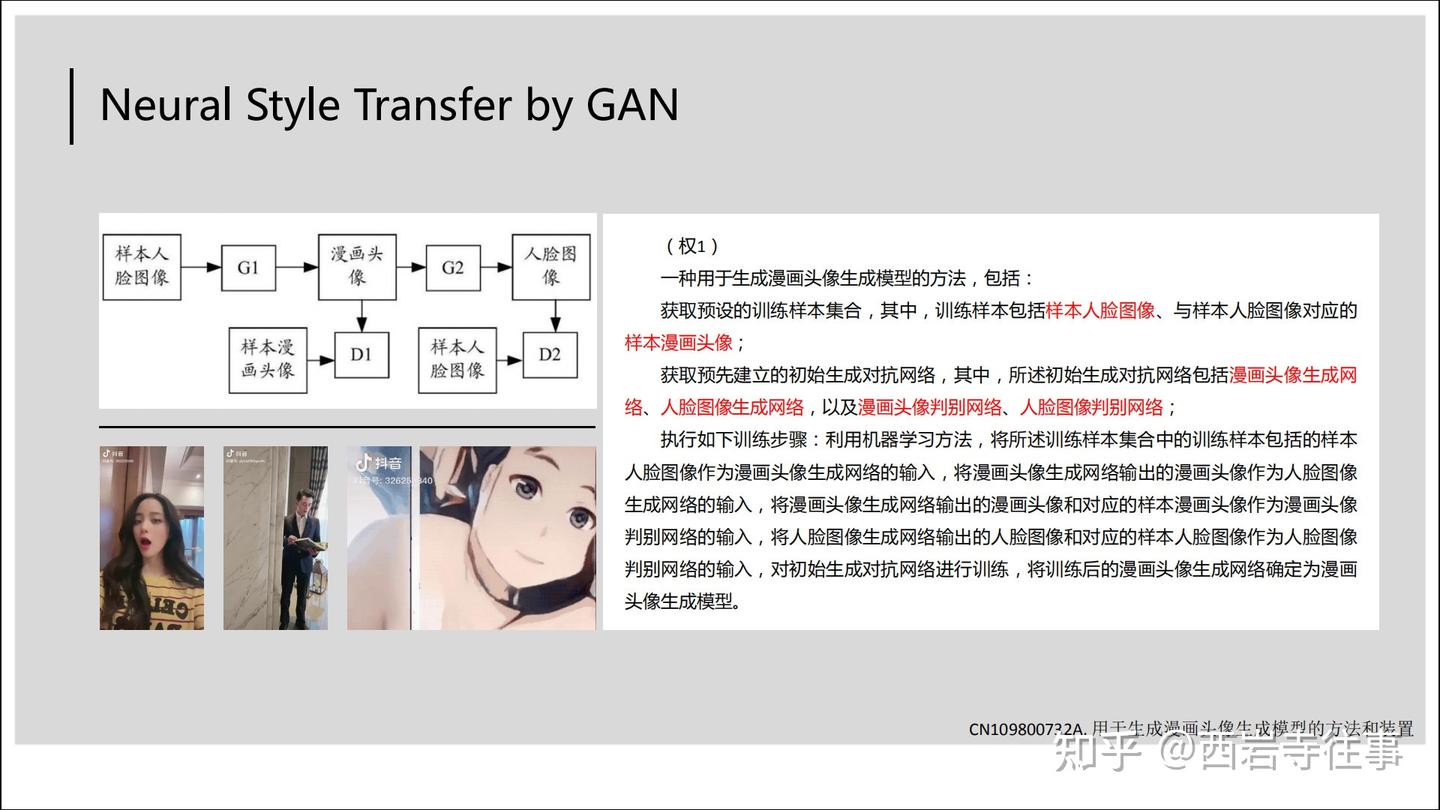
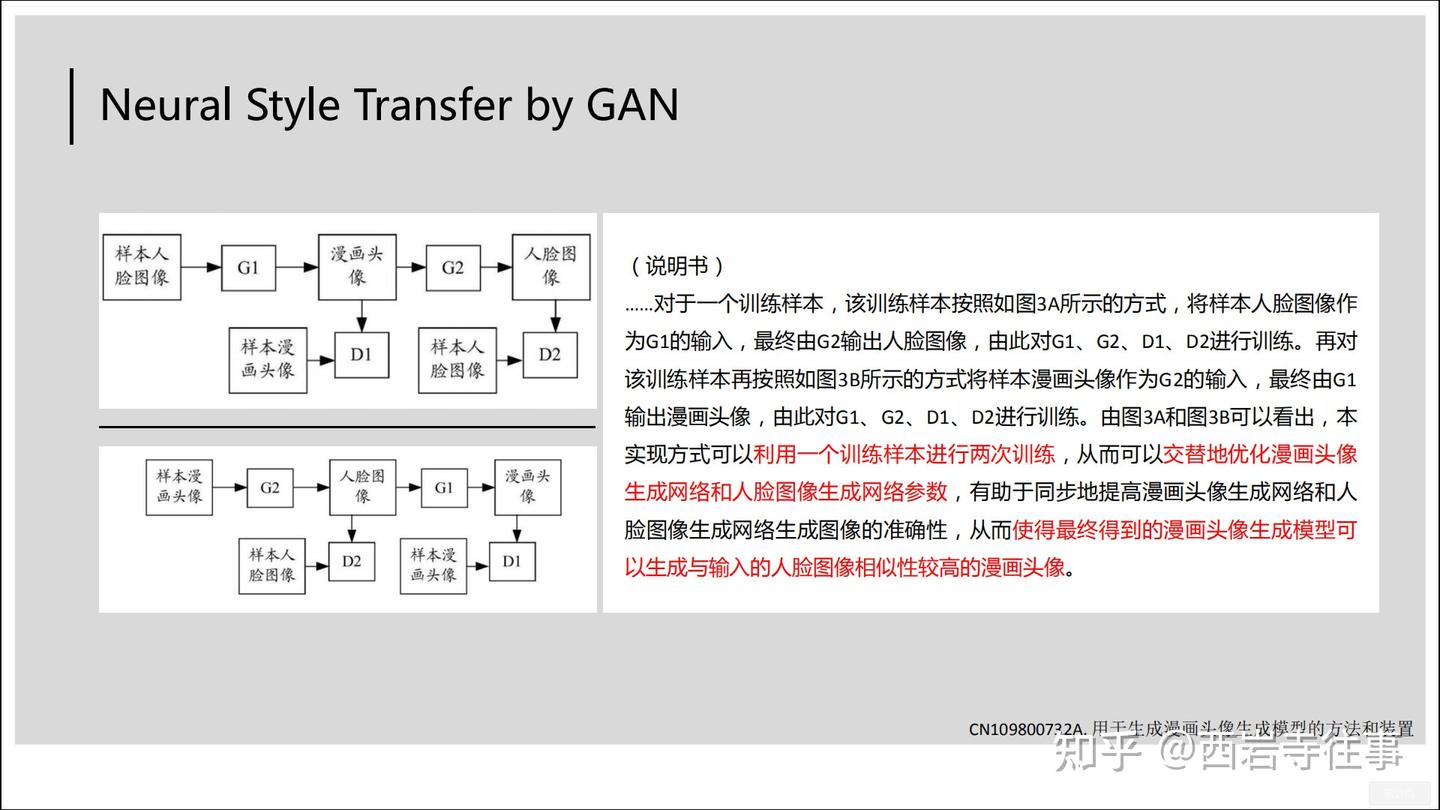
权1基本上就是描述了左侧实施例对应的模型结构、训练样本及训练过程,再次回顾前文图9所涉及的模型训练方法[4],可以看到,二者的模型结构及训练过程基本一致,区别技术特征在于训练样本的构造上,技术方案的主要差异在于具体应用领域的不同。权1对应的有益效果如下图所示:
我们来看看这件于2019年1月30日申请(同年5月24日公布)、2021年1月15日公告授权的专利[8]的修改后的权1:

参照对应说明书可知,相较于图11中的独权1,图13中修改的独权1增加了模型训练过程所需的损失函数相关内容。从保护范围来看,这种修改的影响不是很大,审查员可能是根据缺少技术特征来使申请人对权1进行修改的(个人看法,未核实相关审查程序文件)。
