在模型训练过程中,由于每一层的输入数据分布不断变化,使得当前层的下一层必须不断适应新的数据分布,这会增加训练的复杂度,同时降低训练速率。批量归一化(Batch Normalization,BN)能够使用小批量数据的方差和均值来调整各层的输出,以使其大致服从高斯分布。 由于批量归一化对数据的均值和方差进行了固定的调整,因此网络模型中的参数会变得稳定,从而解决了训练速度慢、学习率不高等问题。批量归一化通常在网络模型中的卷积运算之后、激活层之前进行,首先需要计算输入数据的均值和方差,然后将输入数据的均值和方差归一化到0和1,参见公式如下:
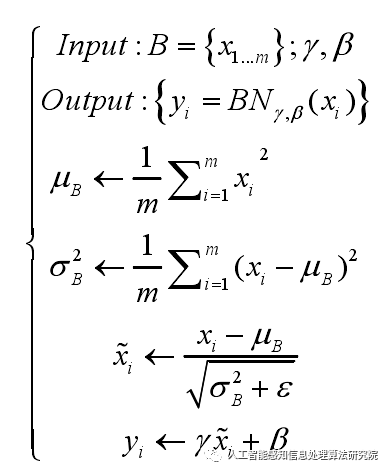
其中gama、 beta为可训练参数,参与网络模型的反向传播, B 为输入集合,xi 和yi 分别表示输入和输出的样本。 由于硬件的限制,当样本数量非常大时不能一次性加载所有数据,因此通常会通过分批抽样的方式分多次加载训练。batch指的是一次送入模型的样本数量,样本是一个四维向量,其维度分别为[N, H,W,C],其中 N 代表特征图的数量, H 代表特征图的高度,W 代表特征图的宽度,C 代表特征图的通道数。如下图所示。

对于特征图张量中的数据,计算其均值的方法是将同一输入样本批次内的每个通道的数字相加,然后将结果除以 NxWxH得到。同样,计算方差也是以当前批次量NxWxH 为单位进行计算。 在实际使用中,数据的统计特征随着样本的不同而变化,导致同样的样本在不同的批次预测中获得不同的概率值,这是不合理的。因此,在测试中,通常会记录滑动平均值来保证结果的稳定性。 当batch较小时,BN层维度统计结果不够准确,会降低模型的准确率。如果无法增加批次的大小,可以收集最近的迭代参数,以更新当前的均值和方差。通过泰勒级数模拟,可以模拟出它们权重的变化情况,以进行补偿

微信公众号二维码

微信公众号:人工智能感知信息处理算法研究院


