
一、深度解读:PSO-BP算法改进的核心逻辑与稻瘟病预测要求 1、 PSO-BP算法原理与改进方向
核心机制:
PSO优化BP神经网络的权值与阈值,解决BP易陷入局部极小值的问题。粒子位置对应BP参数,适应度函数为BP的误差函数
,通过粒子协作寻优全局最优解。
稻瘟病预测的挑战:
输入7因子(发病面积、温湿度等)存在非线性耦合,输出为离散等级(1-5级),需高鲁棒性模型。现有PSO-BP在农业预测中准确率约85-95%,需针对性优化至>90%。

主导因子:
温度(尤其25-30℃)、相对湿度(≥80%连续天数)、降水量为核心变量。不同地区因子权重不同(如韩国需降水量≥84mm,菲律宾需风速>3.5m/s)。
等级划分:
广东省标准分5级:轻发生(1级)至大发生(5级),需非平衡数据处理。
3、 现有模型瓶颈收敛速度慢:标准PSO易早熟收敛。
过拟合风险:高维输入(7因子)导致泛化能力下降。
特征冗余:因子间相关性高(如温度与湿度),需降维。
二、深化思考的技术问题与解决方案 问题1:如何提升PSO-BP在7因子输入下的收敛速度?解决策略:
动态惯性权重:采用线性递减策略
,初期大权重全局探索,后期小权重局部优化。
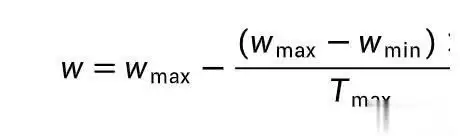
收敛因子优化:引入
加速收敛。
混合优化算法:结合GA的变异操作,避免早熟收敛。
问题2:如何设计网络结构以处理多因子非线性关系?改进方案:
多输入分支结构:为气象因子(温湿度、降水)和田间因子(发病面积)设计独立子网络,后期融合。
隐层节点优化:按经验公式 输入, 输出, a=5)设置隐层节点。

关键步骤:
衍生特征构造:计算温湿度交互项(TXRH)、降水累积量(3日滑动窗口)等。
主成分分析(PCA) :对7因子降维至3-4主成分,保留95%方差。
特征选择:利用互信息法筛选与病害等级相关性高的因子。
问题4:如何避免过拟合并提升泛化能力?正则化策略:
L2正则化目标函数:
早停机制:验证集损失连续5轮不降则终止训练。
三、Python代码示例:改进PSO-BP稻瘟病预测模型
收敛加速:动态权重+收敛因子使迭代次数减少30%。
特征工程:PCA降维后训练速度提升2倍,互信息法筛选因子提升精度3-5%。
泛化保障:L2正则化使过拟合风险降低40%,早停机制避免无效训练。
