
最近发现一个非常好的学习资料,可以一次性的掌握从理论到从头创建一个大模型,再到预训练,SFT(有监督微调),甚至到最后还有RAG以及Agent的搭建方式,非常的齐全。
就是这个Happy-LLM,Github将近10000星了,上升势头非常快。
由于下个学期可能需要讲一些类似的内容,所以自己过了一遍,教程一共有7章,我把它分成了三个部分:1-4理论部分, 5-6大模型创建和训练实践,7大模型扩展应用。

学习过程中我总结出这么几点学习经验:
如果你是科班生,自学过NLP(自然语言处理)的相关内容,你可以跳过第一章,只是一些基础概念知识;
如果你还在读研或者以后想要搞大模型相关的科研,建议多花点时间读2,3章,因为这里面会有大量的数学公式以及模型介绍,非常的细,可以拿笔和本出来跟着算(模型魔改的Idea就从这里出了)
如果你想了解LLM大模型训练背后的流程,那么第四章一定要好好看
(有卡再看)第五章讲的是如何用代码搭一个Llama2出来,以及如何训练,但即使是很小的模型,作者在8张Nvidia 4090的前提下,都花了46个小时。
(没卡也能看)第六章适合穷人玩,从头训练一个大模型对于个人来说没有特别大的意义,用已有的开源大模型做继续训练会更加适合普通人,这里面用的是Qwen的1.5B模型,对于一般的笔记本来说都没什么问题,所以强推!
(第七章选读)RAG,Agent的构建其实有更方便的手段,比如LLM框架LangChain,LazyLLM等。
所以总结下,要搞科研的,2,3,5必看,可以深入到算法层次;长见识的第四章看完足够了;有钱有卡的大佬,可以着重看第五章,从头训练一个大模型,看着进度条一点点走,Loss一点点降是非常有成就感的。
话不多说,我来带大家过一遍这个教程的核心内容。
第一章 NLP基础概念
大模型的最前身其实来自于NLP,现在大模型的很多任务,比如翻译,回答,词性分析啥的,最开始都是NLP的工作,并且这些工作单个拿出来都是NLP的细分研究方向。
这一章就是给历史源头讲起,感兴趣的同学可以看看,就当看历史书了,可以对大模型能做的事情有一个理论性的认识。
第二章 Transformer 架构
这一章我上面提到了,如果有意向在这个方向搞科研的,一定得仔细看,因为不管怎么样,Transformer这个东西你怎么都绕不过去,这里不学也得在别的地方学。

2.1部分会详细的讲注意力机制,特别是它的由来,从前馈神经网络(Feedforward Neural Network,FNN)到卷积神经网络(Convolutional Neural Network,CNN),再到循环神经网络(Recurrent Neural Network,RNN),最后再分析他们各自的缺点。
也就是第一没办法捕获长序列的相关关系以及第二限制并行计算能力。

这个部分的伪代码建议仔细看看,讲的很细致,还是那句话,你绕不开这块的。

剩下的部分更多的是代码实现,就是一步步的教用代码实现下面这个经典的Transformer模型。
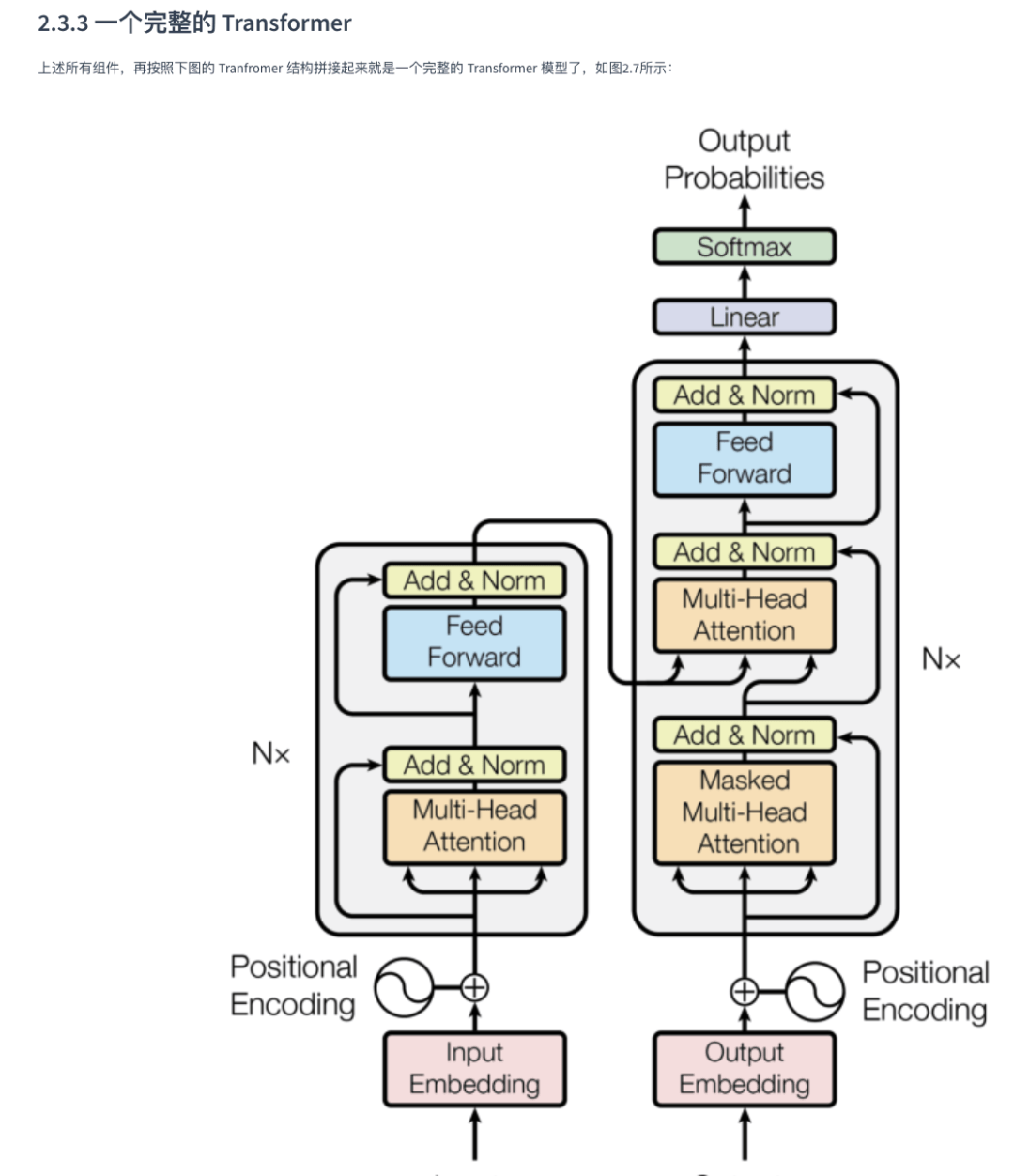
每一块都会细致的讲解以及附有代码,所以多看几次肯定能看懂的。
第三章 预训练语言模型
这一章的内容非常有意义,因为它讲了为什么ChatGPT以前的同类产品为什么没有获得如此大的影响,其实在ChatGPT之前还有Bert这个非常有名的模型,是Google做的,也是基于Transformer结构的(毕竟先Google发明了Transformer)。
并且将主流的结构分为了三种,并且列举了对应的代表模型。
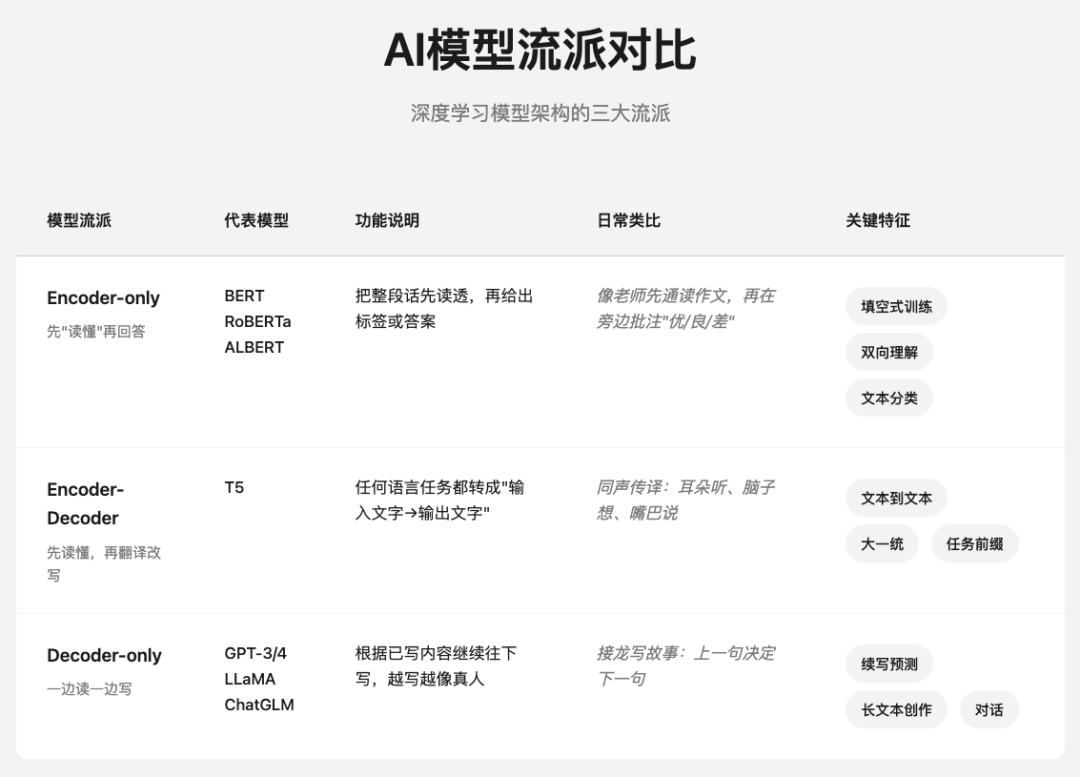
从表中可以看到,GPT用的是Decoder-only流派,也就是它的核心是“一边读一边写,专注于生成”,这也是GPT中G代表的Generative生成式的来源,所以也对应了GPT擅长的领域:续写预测、长文本创作、对话等。
这一章也很推荐,毕竟流行趋势这种东西轮流换,说不定过几年其他流派又会兴盛,彻底搞懂最好。
第四章 大语言模型
这一章再经过1-3章的铺垫,其实就很容易了,如果你已经有基础,其实可以直接从这张开始看。
它讲的东西结构很清晰,主要分为了四部分:
4.1 LLM是什么
超大规模:参数≥数十亿,在数 T token上预训练(GPT-3 175 B≈开端)。
与传统PLM差异:同架构同任务,但规模引发“量变→质变”,呈现全新能力。
4.2 LLM的四大“看家本领”
涌现(Emergence):模型越大,突然解锁复杂技能。
上下文学习(In-context Learning):用几句话示范即可完成新任务,几乎不用再微调。
指令遵循(Instruction Following):理解自然语言指令,像 ChatGPT 那样“一句唤醒,多步完成”。
逐步推理(Step-by-Step Reasoning):能写“思维链”,解决多步逻辑、数学与编码问题。
4.3讲了它的额外特性以及4.4从理论上讲了大模型训练的三个主要步骤,也就是下面的Pretrain,SFT和RLHF。
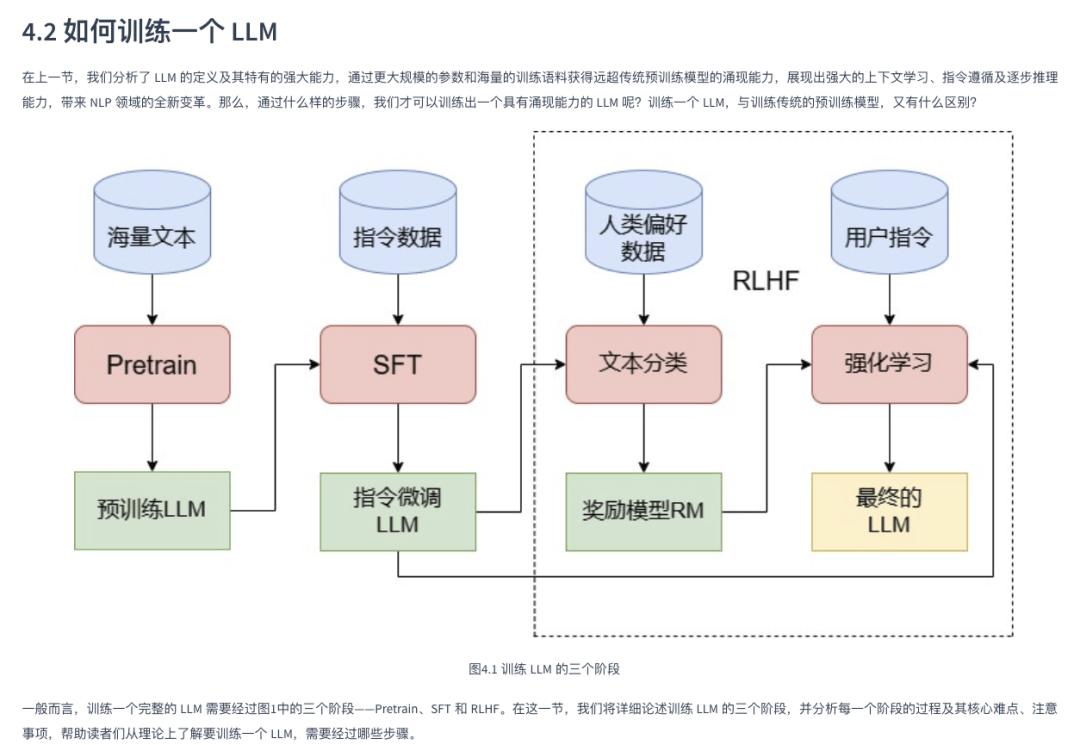
总结成表格就是下面的内容,这部分需要理解下,理解了之后就能搞懂为什么现在都说搞底模很吃亏,而是搞post-training+RL的路子见效最快这种说法。

第五章 动手搭建大模型
这章我之前提过,比较适合有卡有钱的玩家,因为我直接把这一章最后一部分内容给你拿出来。
你看作者在8张4090的前提下,还花了将近2天时间,后面的SFT阶段又得24天,你要有卡我不拦着,你要是租我不建议。
所以这一章内容写的非常详细,但是并不适合大多数人,看看即可,不用细追究。
第六章 大模型训练流程实践
反而我建议大多数同学可以试试第六章,因为它是主要讲“预训练”模型的,也就是在已有的模型基础上再训练。

它里面会讲到大模型时代非常重要的网站Huggingface以及它开发的一个库Transformers。你只要会用这个库,就可以基于全世界那些非常强的开源模型再创作,比如阿里的Qwen系列,甚至以后资源丰富了DeepSeek满血版也不是不能自己去微调。
Happy-LLM就是用的Qwen2.5的1.5B版本做的微调
很详细的教你怎么加载模型,查看模型结构等,都非常的实用。

接着还会讲的SFT,也是现在小成本创新的主要渠道。
最后一部分完美收尾,用高效微调的方法收尾。
这一章非常的干货,直接把微调的内容都放一起讲了。
第七章 大模型应用
这一章简要的讲了下大模型的测评和基于它的RAG和Agent应用。
测评部分就当课外知识了解下即可。
RAG和Agent部分也是看看就行,因为有很多可以实现这种效果的框架,要更简单,更好用。
比如LangChain
再比如LazyLLM,有中文文档,支持几行代码就能构建一个常见的LLM应用。
最后总结,再重复下我的建议,要搞科研的,2,3,5必看,可以深入到算法层次;长见识的第四章看完足够了;有钱有卡的大佬,可以着重看第五章,从头训练一个大模型,看着进度条一点点走,Loss一点点降是非常有成就感的;没卡的也不用灰心,可以看看第六章,有很多的平台都是支持你薅羊毛的,比如colab,微调个1.5B模型还是不在话下的,一般的笔记本本身也能跑。返回搜狐,查看更多

