
要在边缘计算节点部署轻量级模型实现毫秒级响应,需综合硬件适配、模型优化、部署框架及网络传输优化等多维度策略。以下为系统性解决方案:
一、边缘节点硬件适配与资源优化边缘设备普遍存在算力弱、内存小、存储有限等约束(如典型配置:ARM Cortex-A53@1.2GHz CPU,512MB-2GB内存,4-32GB eMMC存储),需针对性优化:
1、硬件选型
专用加速芯片:集成NPU/TPU(如昇腾310、NVIDIA Tesla P4)提升推理效率,满足8 TOPS算力需求。
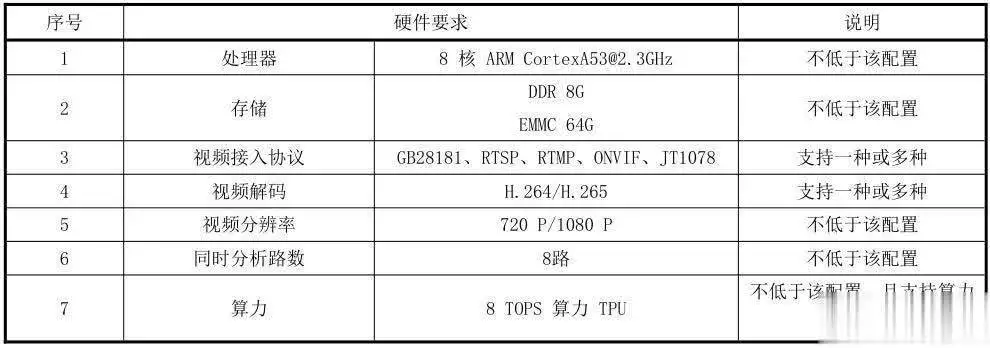
工业级设计:设备需支持宽温(-40℃~85℃)、防震、防电磁干扰,适应户外部署。
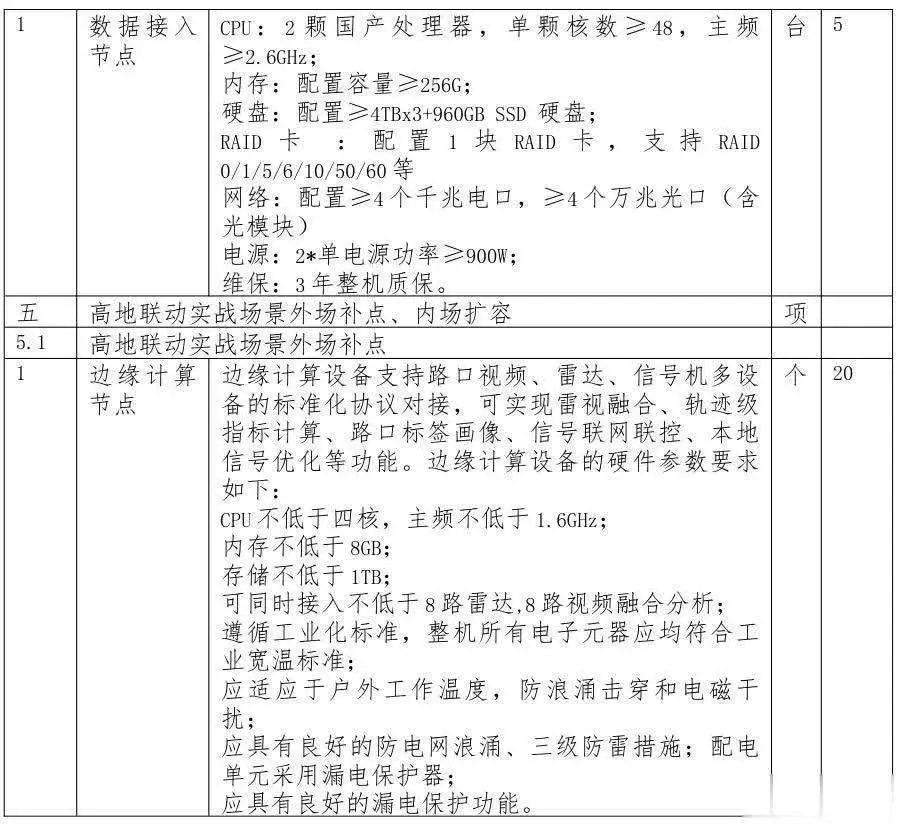
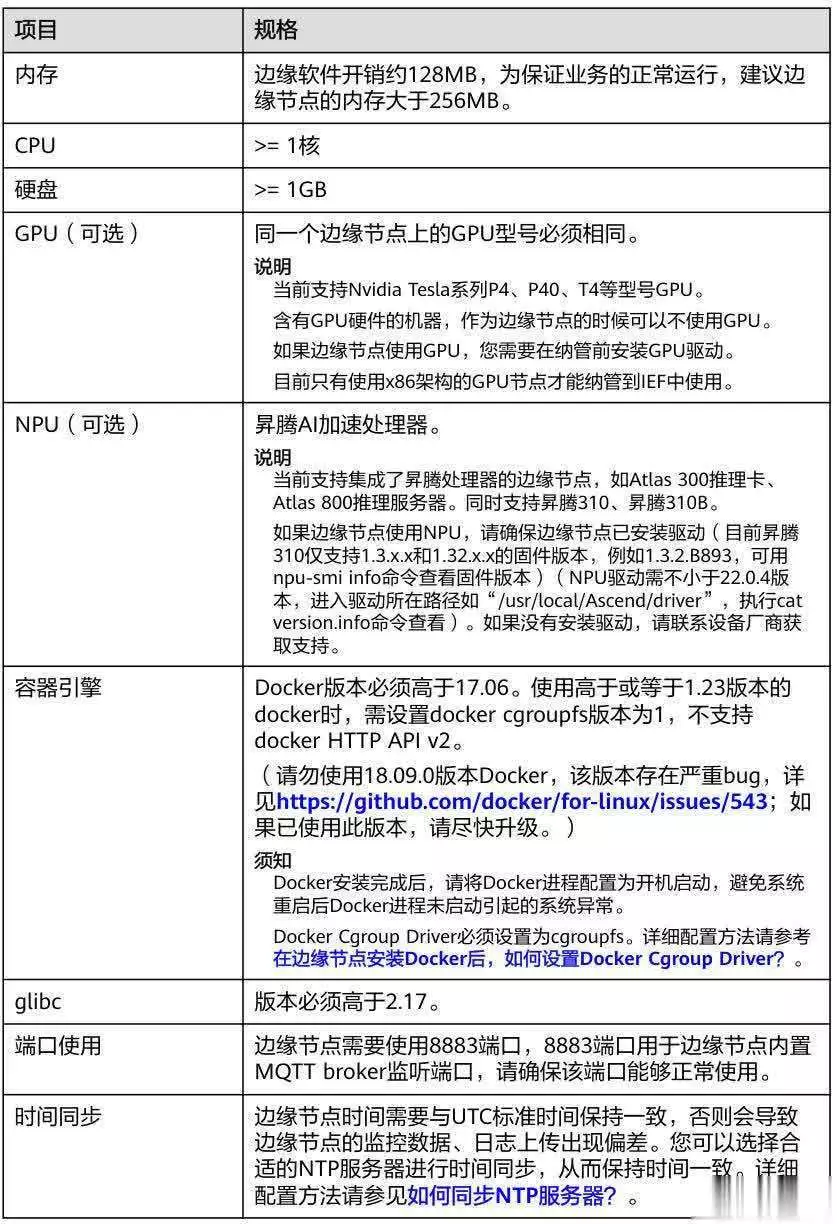
2、资源动态管理
内存复用:采用环形缓冲区减少动态内存分配,避免频繁I/O操作。
计算卸载:建立代价模型(E=α·T_process + β·T_trans),动态分配任务至NPU/MCU异构架构,如农业无人机续航提升25%。
容器化调度:通过K3s(Kubernetes边缘版)动态调整容器数量,维持CPU利用率≤70%。
二、轻量级模型选型与压缩优化 (1)模型架构选择(低计算复杂度)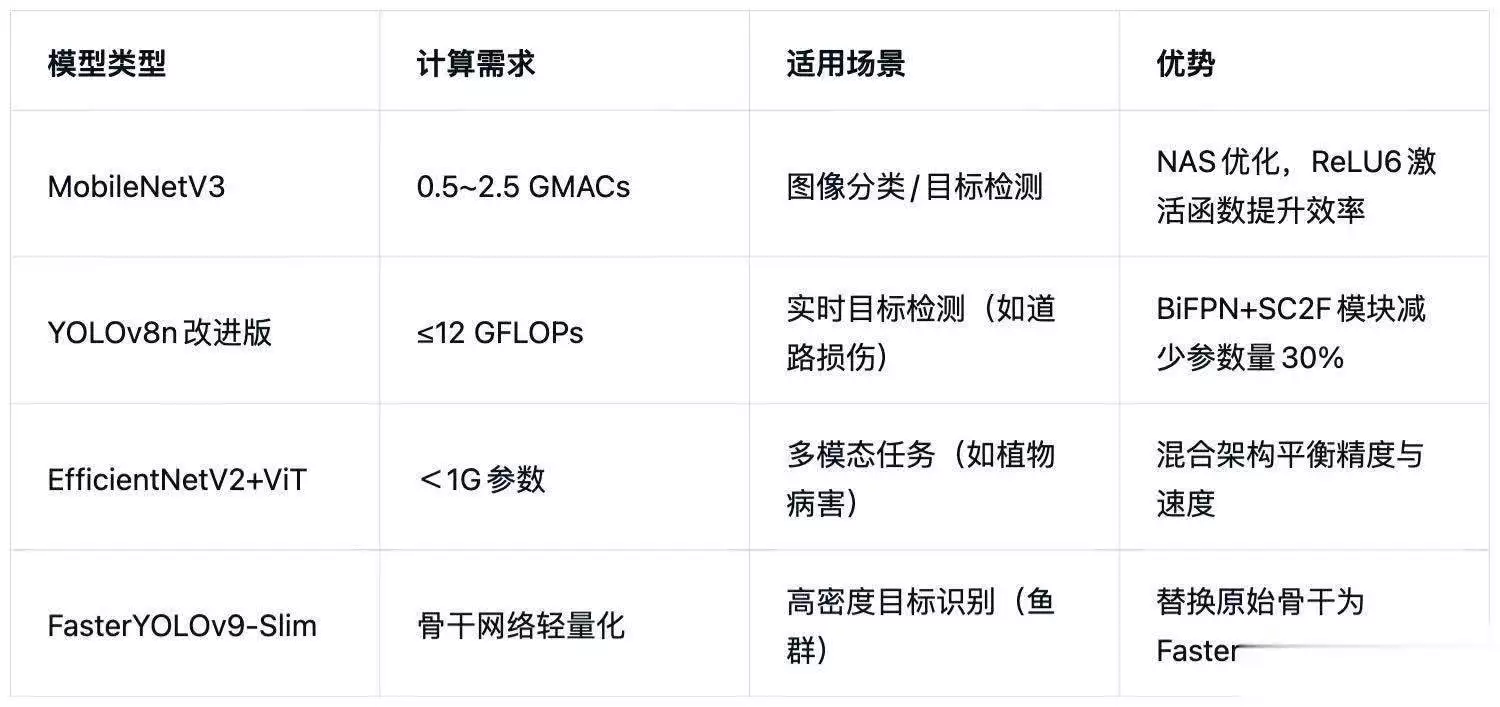
量化(Quantization):
INT8/FP16转换:权重从32位浮点压缩至8位整数,存储需求减少4倍,推理速度提升2-3倍。
极低比特量化:边缘处理器支持4位精度(如昇腾310B),进一步降低功耗。
知识蒸馏(Knowledge Distillation):
用大模型(教师)监督小模型(学生),如DeepSeek蒸馏版1.5B模型在部分任务超越GPT-4o。
分层蒸馏技术实现边缘设备高效推理。
剪枝(Pruning):
结构化剪枝:移除冗余通道(如RLSL-YOLO11的GSConv模块),参数量减少15%。
自适应压缩:根据设备电量动态启用/禁用网络层。
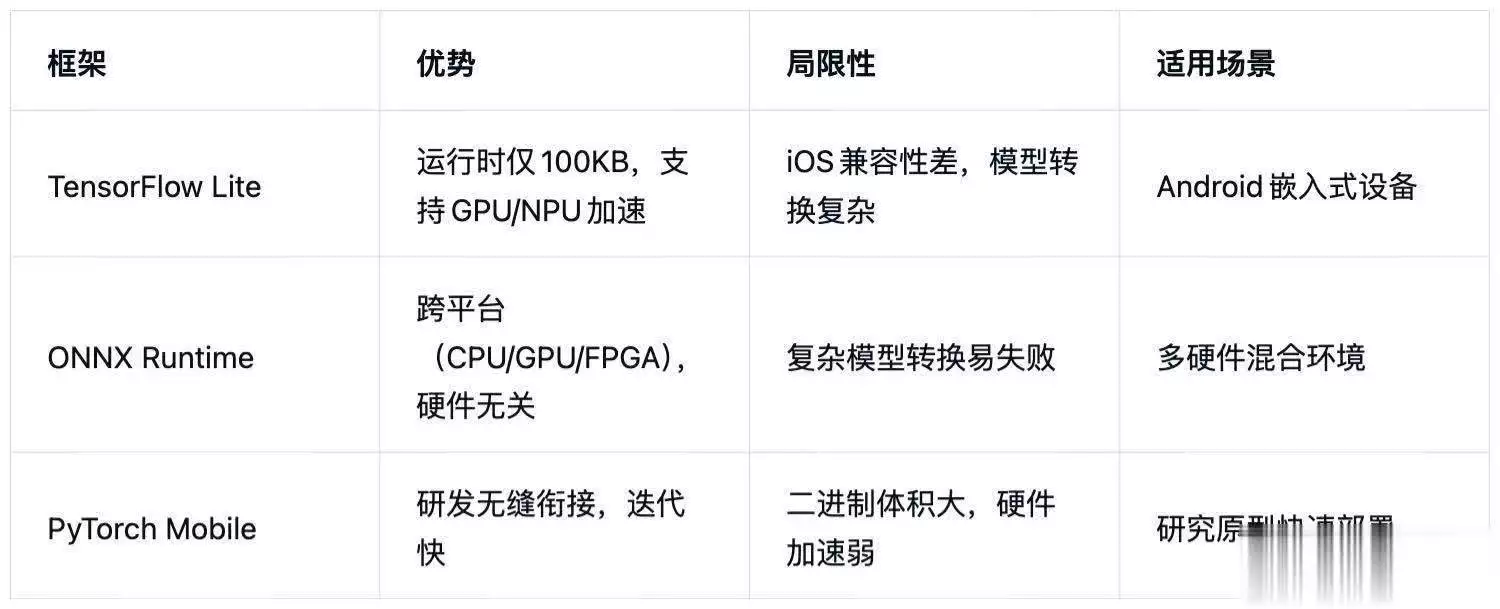
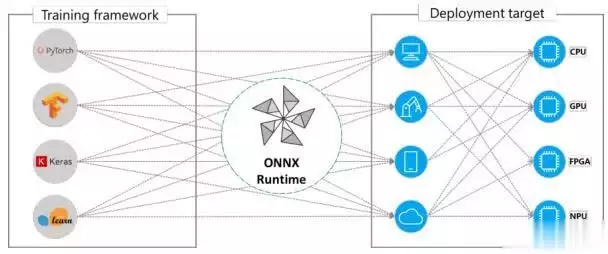
硬件加速集成:
TFLite通过Delegate机制调用NPU(如华为昇腾),ONNX Runtime支持TensorRT优化。
算子定制:
替换标准卷积为深度可分离卷积(Depthwise Separable Conv),计算量降至1/9。
内存预分配:
避免推理时动态分配内存,减少延迟抖动。
四、网络传输与实时性保障1、数据本地化处理
边缘节点直接处理传感器数据(如路口雷视融合),避免云端传输,延迟降低50%以上。
2、低延迟协议优化
MQTT协议:开销<1ms,适合传感器数据上传。
QUIC协议:0-RTT连接建立,比TCP减少3次握手。
3、边缘缓存与预处理
视频流本地解码降分辨率(1080P→720P),带宽需求减少60%。
五、全链路延迟分解与优化(毫秒级目标)
物理防护:三级防雷+漏电保护,适应户外电网波动。
数据安全:
本地脱敏处理(如医疗影像去标识化)。
TLS双向认证+AES-256加密传输。
冗余设计:多节点Raft协议保障一致性,故障切换<50ms。
七、典型部署流程硬件配置:选配NPU(≥8 TOPS)+工业级机箱。
模型压缩:原始模型→剪枝→蒸馏→量化(INT8)。
框架部署:ONNX/TFLite格式转换→集成硬件加速Delegate。
资源监控:K3s动态扩缩容器,CPU利用率阈值70%。
实现毫秒级响应的核心在于模型轻量化(压缩技术)、硬件加速(NPU/TPU)、边缘就近计算(数据零传输)三者的协同。随着MoE架构(如混元-A13B模型)和自适应压缩技术的成熟,边缘AI将逐步覆盖工业控制、自动驾驶等高实时场景。
