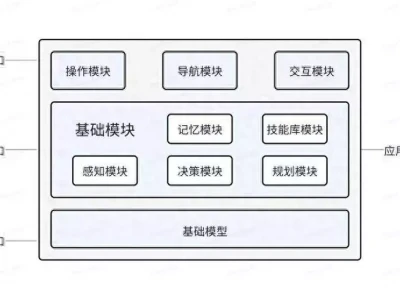
文章一:深度剖析:大模型测试基准LMBench2.0发布,引领行业新风向

在人工智能技术日新月异的今天,大模型作为推动AI进步的核心力量,其性能评估与测试标准成为了业界关注的焦点。近日,一款备受瞩目的新工具——大模型测试基准LMBench2.0正式发布,标志着大模型性能评估领域迈入了一个全新的阶段。
LMBench2.0的诞生,是对当前大模型测试体系的一次重要革新。随着大模型参数规模的不断膨胀和应用场景的日益丰富,原有的测试方法已难以全面、准确地衡量模型的性能。LMBench2.0应运而生,它不仅继承了前代版本在基础性能测试上的优势,更在测试维度、测试场景和评估标准上进行了全面升级。

在测试维度上,LMBench2.0突破了传统测试的局限,将测试范围从单一的文本处理扩展到了图像、语音、视频等多模态领域,实现了对大模型综合能力的全面评估。这一变革,使得测试结果更加贴近实际应用场景,为模型优化和选择提供了更为可靠的依据。
测试场景的丰富性也是LMBench2.0的一大亮点。它不仅涵盖了常见的自然语言处理任务,如文本分类、情感分析、机器翻译等,还引入了复杂的多轮对话、知识推理等高级任务,以及跨模态的图像描述生成、视频内容理解等挑战性任务。这些场景的加入,使得测试过程更加贴近真实应用环境,有助于发现模型在实际使用中的潜在问题。
评估标准的科学性和客观性,是LMBench2.0赢得业界认可的关键。它采用了一套全面、细致的评估指标体系,不仅考虑了模型的准确率、召回率等传统指标,还引入了效率、鲁棒性、可解释性等多个维度的评估标准。这种多维度的评估方式,使得测试结果更加全面、客观,有助于推动大模型技术的健康发展。
LMBench2.0的发布,对于大模型技术的研发和应用具有深远的意义。它不仅为模型开发者提供了一个权威、公正的测试平台,帮助他们更好地了解模型的性能特点,优化模型结构,提升模型性能;也为模型应用者提供了一个可靠的参考依据,帮助他们选择最适合自己需求的大模型,推动AI技术在各个领域的广泛应用。
展望未来,随着LMBench2.0的广泛应用和不断完善,我们有理由相信,大模型性能评估将变得更加科学、客观、全面。这将有助于推动大模型技术的持续创新和发展,为人工智能时代的到来奠定坚实的基础。
文章二:大模型测试基准LMBench2.0发布,开启性能评估新篇章
近日,人工智能领域迎来了一项重要进展——大模型测试基准LMBench2.0正式发布,这一消息迅速在业界引起了广泛关注。作为一款旨在全面、准确评估大模型性能的测试工具,LMBench2.0的发布无疑为当前蓬勃发展的大模型技术注入了新的活力。
据悉,LMBench2.0在继承前代版本优势的基础上,进行了全面的升级和优化。它不仅扩展了测试维度,将图像、语音、视频等多模态领域纳入测试范围,还丰富了测试场景,涵盖了自然语言处理、知识推理、跨模态理解等多个高级任务。这一变革使得测试结果更加贴近实际应用场景,为模型优化和选择提供了更为可靠的依据。
值得一提的是,LMBench2.0在评估标准上也进行了创新。它采用了一套多维度的评估指标体系,不仅考虑了模型的准确率、召回率等传统指标,还引入了效率、鲁棒性、可解释性等多个维度的评估标准。这种科学、客观的评估方式,有助于推动大模型技术的健康发展,提升模型在实际应用中的表现。
业内专家表示,LMBench2.0的发布对于大模型技术的研发和应用具有重要意义。它不仅为模型开发者提供了一个权威、公正的测试平台,帮助他们更好地了解模型的性能特点,优化模型结构;也为模型应用者提供了一个可靠的参考依据,有助于他们选择最适合自己需求的大模型,推动AI技术在各个领域的广泛应用。
随着LMBench2.0的广泛应用和不断完善,我们有理由相信,大模型性能评估将变得更加科学、客观、全面。这将有助于激发大模型技术的创新活力,推动人工智能技术的持续进步和发展。返回搜狐,查看更多