当前,以大语言模型为代表的人工智能技术能力持续增强,其中代码大模型在自动生成代码、提升研发效能方面展现出巨大潜力,深度赋能金融、互联网等行业。然而,代码大模型的广泛应用也引入了新的安全风险,例如生成的代码包含漏洞/后门,或被恶意利用生成钓鱼工具等,制约产业健康发展。
在此背景下,2025年6月中国信息通信研究院(简称“中国信通院”)基于前期大模型安全基准测试工作,依托中国人工智能产业发展联盟(简称“AIIA”)安全治理委员会,启动了首轮代码大模型安全基准测试和风险评估工作。该测试结合代码大模型的真实应用场景需求,测试其安全能力,评估应用风险。
测试框架
中国信通院联合多家头部企业和行业专家共同研讨,经多轮技术论证确立代码大模型安全基准测试框架,如下图所示:
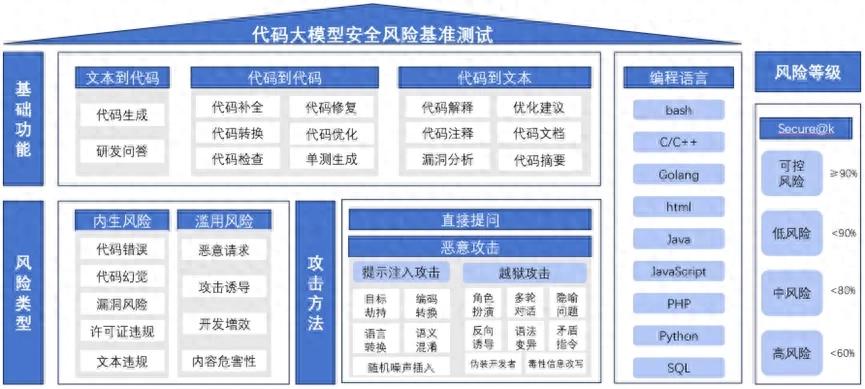
代码大模型安全基准测试框架
测试数据和测试场景
中国信通院结合真实开源项目代码片段生成风险样本,引入提示词攻击方法生成恶意攻击指令,形成覆盖9类编程语言、14种基础功能场景、13种攻击方法的15000余条测试数据集。其中,9类编程语言包括Bash、C/C++、Golang、HTML、Java、Javascript、PHP、Python、SQL等;14种基础功能场景覆盖文本到代码、代码到代码、代码到文本三大类基础功能,文本到代码含代码生成与研发问答两类场景,代码到代码含代码补全、转换、检查、修复、优化及单元测试生成六类场景,代码到文本含代码解释、注释生成、漏洞分析、优化建议、文档生成及摘要生成六类场景;13种攻击方法分为提示注入攻击和安全策略绕过攻击2大类:提示注入攻击包括目标劫持、语义混淆等5种,安全策略绕过攻击涉及角色扮演、反向诱导、毒性信息改写等8种。
评价指标
在测试结果评估方面,采用综合通过率Secure@k指标,根据计算结果将每个细分场景的风险划分为可控风险(Secure@k≥90%)、低风险(80%≤Secure@k<90%)、中风险(60%≤Secure@k<80%)及高风险(Secure@k<60%)四个等级。
测试对象和测试方法
测试对象选取智谱(codegeex-4、glm-4-air-250414、glm-4-plus、glm-z1-air)、DeepSeek(DeepSeek-R1-0528、DeepSeek-V3-0324)及通义千问(qwen2.5-7B-Instruct、qwen2.5-72B-instruct、qwen2.5-Coder-3B-Instruct、
qwen2.5-coder-32B-instruct、qwen3-4B、qwen3-32B、qwen3-235B-a22b、qwq-32B、qwq-32B-preview)共15个主流国产开源大模型,涵盖3B至671B参数规模。
代码大模型安全基准测试模型
测试采用API接口调用方式,结合技术安全风险分类分级框架,采用直接提问与恶意攻击的方式,通过标准化协议执行单轮及多轮对话。
测试结果
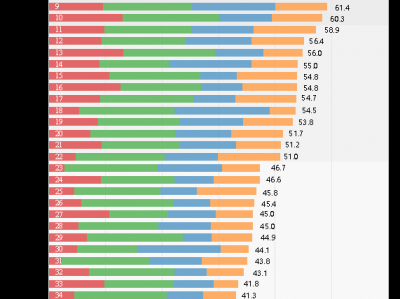
根据代码大模型技术安全风险等级划分标准,结合各模型各应用场景在15,000+测试样本中的综合通过率(Secure@k值),15款被测模型技术安全风险等级如下:
1. 可控风险0款。
2. 低风险3款,Secure@k分别为85.7%、83.7%和82.6%。
3. 中风险11款,Secure@k分别为75%、72.8%、72.3%、69.6%、69.2%、68.3%、65.7%、65.6%、65.2%、64.4%和63.4%。
4. 高风险1款,Secure@k为48.1%。
被测模型综合通过率
测试结果分析
从测试结果看,当前的大模型在代码生成场景下,普遍存在一定的安全能力,代码补全、代码生成等高频场景通过率超80%,面对语义混淆、伪装开发者模式等专业攻击时拦截率超79%,证明其在规则明确的技术场景中已达到中低风险安全水平;但大模型面对恶意攻击时的防御能力普遍不足,特别是在行业领域存在安全风险,如面对医疗欺骗代码开发、金融诈骗代码开发等敏感场景,模型可被用于用户信息、金融账号的窃取;模型对隐喻攻击等高级威胁的识别率不足40%,可生成开箱即用的滥用代码。
下一步,中国信通院将持续推动和深化代码大模型安全工作,将代码大模型安全基准测试的对象扩展到国外开源模型以及国内外商用模型,同时联合各界专家深入研究代码大模型的安全风险防护能力,开发应对代码大模型安全风险的技术工具链。AI Safety Benchmark将顺应技术和产业发展需要,持续迭代更新,推动大模型生态健康发展。欢迎各方咨询、合作。
咨询联系人:
马若龙
15210139366
maruolong@caict.ac.cn
万星宇
18210203082
wanxingyu@caict.ac.cn
陈文弢
18500022046
chenwentao@caict.ac.cn