点击蓝字关注我们 公众号后台学习书籍和视频免费送
之前有篇文章分析了AI“瞎编”的原因,点此处回顾高度警惕!! 大模型会一本正经地“瞎编”,深度解析大模型的"幻觉"。那有没有防止AI“瞎编”的方法呢?答案是肯定的,本篇文章就讲解灵丹妙药之一:交叉验证法。
一、引言
在机器学习领域,常常会面临根据已有样本数据进行预测的任务。以医疗领域为例,已知一些患者是否出现胸痛、血液循环状况、动脉是否闭锁以及体重指标等变量,以此来预测患者是否患有心脏病。当遇到新患者时,测量其相应变量后,如何准确预测其患病情况成为关键问题。在解决此类问题时,有多种机器学习算法可供选择,如 logistic 回归、K - 最近邻居法、支持向量机(SVM)等,然而选择何种算法以实现最佳预测效果是一个重要挑战,交叉验证法在其中发挥着至关重要的作用。
二、交叉验证法的作用
交叉验证法在机器学习中主要用于比较多种机器学习方法,并评估这些方法在实际数据中的性能表现。在面对复杂的现实数据时,不同的机器学习算法对数据的处理方式和效果差异较大。例如,在图像识别任务中,对于识别猫和狗的图像,有的算法可能在处理清晰、特征明显的图像时表现良好,而有的算法则对模糊、有噪声的图像识别更具优势。通过交叉验证,能够系统地比较不同算法,为选择最优算法提供依据。

三、机器学习的核心任务
机器学习主要包含两个关键内容:估计模型参数与评估模型性能。
估计机器学习方法的参数是构建模型的基础。以 logistic 回归为例,其模型是基于一条曲线来对数据进行分类预测,为了确定这条曲线的具体形态,需要利用部分数据来估计相关参数。这就如同搭建一座桥梁,工程师需要根据地形、承载需求等数据来确定桥梁结构的各项参数,确保桥梁稳固。在机器学习里,这个过程被称为训练算法。

评估模型性能同样不可或缺。训练好的模型在新数据上的表现才是衡量其有效性的关键。例如训练好的一个预测用户是否会购买某商品的模型,需要用新的用户数据来检验其预测的准确性。在机器学习中,这一过程被称为测试算法,只有通过严格测试,才能知道模型是否真正具备对未知数据的预测能力。

四、交叉验证法在机器学习中的重要性
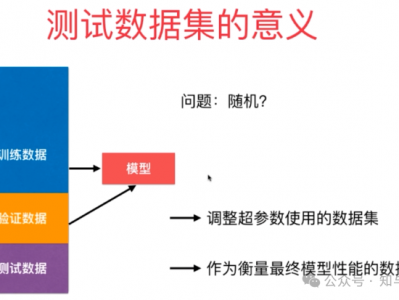
实现机器学习的上述两个核心任务,需要合理划分训练数据集和测试数据集。
如果直接使用所有数据进行模型训练,不预留测试数据,后续只能用训练数据重复测试,这就如同一位老师既教授知识又完全依据自己所教内容出题考试,学生成绩无法真实反映其知识掌握程度,模型也无法准确体现其在新数据上的性能。

相对合理的做法是划分数据集,如将所有样本的 75% 作为训练样本,25% 作为测试样本,用测试样本评估不同机器学习方法的性能。这类似邀请其他老师出题,能在一定程度上检验学生对知识的掌握情况。

而交叉验证法是更为科学的方案。以四折交叉验证为例,将样本随机均分成 4 份,每次选取其中 3 份作为训练集训练模型,剩余 1 份作为测试集测试模型,并记录模型在每次测试集中的表现,如正确分类和错误分类的样本数量。通过多次测试,综合评估模型性能,能更全面、准确地了解模型的实际表现。
五、常见的交叉验证模型
5.1 四折交叉验证
四折交叉验证将所有样本随机分成 4 份。假设有一组预测员工是否会离职的数据,包含员工的工作年限、薪资水平、加班频率等特征。
第一次,用前 3 份数据训练模型,第 4 份数据测试,记录预测结果。假设正确预测出 5 名员工是否离职,错误预测 1 名;

第二次,用第 1、2、4 份数据训练,第 3 份数据测试,若正确预测 4 名,错误预测 2 名;

第三次,用第 1、3、4 份数据训练,第 2 份数据测试,正确预测 1 名,错误预测 5 名;

第四次,用第 2、3、4 份数据训练,第 1 份数据测试,正确预测 6 名,错误预测 0 名。

最后汇总不同模型 4 次在测试数据集中的判断结果,比较不同机器学习方法的总体表现,选择性能最佳的模型。

5.2 留一法交叉验证
留一法交叉验证是一种极端情况,将 n 个样本等分成 n 等份,每次仅留 1 份作为测试数据,其余作为训练数据。假设共有 10 个样本用于预测学生的考试成绩是否及格,每次拿出 1 个学生的数据作为测试集,用剩下 9 个学生的数据训练模型,如此进行 10 次测试。这种方法的原理与四折交叉验证相同,但由于每次测试集只有 1 个样本,计算量较大,不过在样本数量较少时,能充分利用每个样本的信息。

5.3 十折交叉验证
十折交叉验证是应用最广泛的交叉验证方法之一。它将所有样本十等分,每次选取其中 9 份作为训练数据集训练模型,剩余 1 份作为测试数据集测试模型。例如在预测房价的任务中,将大量房屋的面积、位置、房龄等数据进行十折划分,多次训练和测试模型,依据测试结果评估不同模型的优劣,具体评估方式与四折交叉验证类似。

六、交叉验证法的拓展应用
在训练模型时,为提高结果的准确度,除了确定模型的基本参数外,还可引入额外的调整参数。例如在 logistic 回归中,某些参数并非基于样本数据直接估计得出,而是通过尝试不同取值来寻找最优参数,以优化模型性能。此时,交叉验证法可用于选定最佳的调整参数,使模型在预测任务中表现更优,不过这部分内容涉及更为深入的技术细节,在后续学习研究中可进一步探索。
七、结论
交叉验证法在机器学习中对于合理确定训练数据集和测试数据集意义重大,它能够帮助研究者选择最佳的机器学习模型,提升模型在实际应用中的性能。随着机器学习在各个领域的广泛应用,深入理解和合理运用交叉验证法,将为解决复杂的实际问题提供有力支持,推动相关技术的不断发展与创新。


往期精彩文章
高度警惕!! 大模型会一本正经地“瞎编”,深度解析大模型的"幻觉"
Nature分析:中国为什么能创造震惊世界的AI大模型DeepSeek