

背景
在机器学习中,过拟合是一个常见的难题。简单来说,过拟合指的是模型在训练数据上表现得非常好,甚至能够完美预测每一个样本,但在新的、未见过的数据上(常指测试集)却表现得很差。这意味着模型对训练数据的噪音和细节过于敏感,无法概括出数据的普遍规律
这里提供一种思路,结合SHAP值和训练集与测试集上的性能表现来进行分析,为了识别出那些可能导致过拟合的特征,首先要理解SHAP值的作用。SHAP值可以衡量每个特征对模型预测结果的影响,并为每个样本的预测提供透明的解释,如何利用SHAP值分析特征
SHAP值与目标变量的相关性:每个特征的SHAP值反映了该特征对模型预测结果的影响程度。而这种影响通常是线性或非线性的,具体取决于模型的复杂性。可以通过计算每个特征的SHAP值与目标变量之间的相关性来量化这个影响的程度
训练集与测试集上的SHAP趋势一致性:在理想情况下,训练集和测试集上的SHAP值与目标变量之间的关系应该是一致的。这意味着,无论是在训练数据还是测试数据中,某个特征的SHAP值与目标变量之间应该维持类似的趋势。如果训练集和测试集上的SHAP值与目标变量之间的关系发生了显著的变化,那么这可能是一个过拟合的信号。例如,某个特征在训练集上产生了很强的预测信号,但在测试集上其SHAP值与目标变量的关系较弱或者完全不同,说明这个特征可能在模型中过拟合了
识别过拟合特征:如果某个特征在训练集上的SHAP值与目标变量有很高的相关性,但在测试集上的相关性较低,或者SHAP值与目标变量的影响趋势发生反转,这说明该特征在训练集中过拟合了模型。此时,可以考虑减少该特征的影响,或者对该特征进行正则化,从而提高模型的泛化能力对于第一点为什么计算相关性给出解释,虽然可以通过计算SHAP值的绝对值的均值来判断特征对目标变量的影响程度,但这种方法并不完全理想。因为SHAP值不仅包含了特征的主效应(即该特征单独对模型输出的影响),还包括了特征与其他特征之间的交互效应(即该特征与其它特征共同作用对模型的影响)。因此,单纯依赖SHAP值的绝对值可能无法准确反映特征对目标变量的实际影响。如果我们能在计算特征的重要性时,先消除其他特征的影响,比如使用偏相关系数或单独提取出主效应部分,这样得到的影响度量可能会更加精准和可靠,所以这里暂且采用相关性来代替,看看在实际的代码训练上有没有真正的降低过拟合,个人观点,仅供参考
代码实现
初步模型构建
采用数据所有特征
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltplt.rcParams[font.family] = Times New Romanplt.rcParams[axes.unicode_minus] = Falseimport warnings# 忽略所有警告warnings.filterwarnings("ignore")df = pd.read_excel(2025-2-6公众号Python机器学习AI.xlsx)from sklearn.model_selection import train_test_split# 划分特征和目标变量X = df.drop([y], axis=1)y = df[y]# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=df[y])from xgboost import XGBClassifierfrom sklearn.model_selection import StratifiedKFoldfrom sklearn.metrics import accuracy_score# 定义 XGBoost 默认二分类模型xgboost = XGBClassifier(random_state=42)# 拟合模型(直接使用训练数据)xgboost.fit(X_train, y_train)
加载数据,划分训练集和测试集(使用数据所有特征),然后使用 XGBoost 分类器对训练数据进行拟合,使用的 XGBClassifier 是默认参数下的模型,即没有对 XGBoost 分类器的任何超参数进行调整或优化。它使用的是 XGBoost 的默认设置,包括学习率、最大树深度、树的个数等。因此,该模型在训练时并未进行任何针对数据特征或问题的定制化调参,而是直接应用 XGBoost 默认的参数进行训练
模型评价
from sklearn.metrics import classification_report# 预测测试集y_pred_test = xgboost.predict(X_test)# 输出测试集的分类报告print("测试集分类报告:")print(classification_report(y_test, y_pred_test))# 预测训练集y_pred_train = xgboost.predict(X_train)# 输出训练集的分类报告print("训练集分类报告:")print(classification_report(y_train, y_pred_train))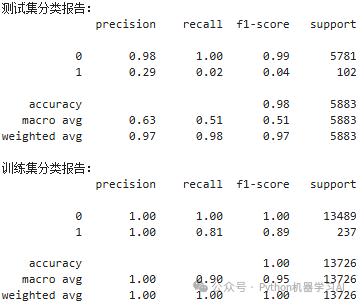
从分类报告可以看出,虽然 accuracy 在训练集和测试集上都表现得很好,尤其在训练集上为 100%,但通过 f1-score 和 recall 的对比,尤其是对于少数类别的样本,模型的表现存在严重的过拟合。训练集中的 f1-score 和 recall 都非常高,而测试集中的 f1-score 和 recall 对于少数类别样本的表现却非常差,这表明模型在训练集上过拟合了。总之,模型的效果不能单纯依赖于 accuracy,因为它可能掩盖了少数类别的预测问题,类似于样本不均衡的情形中,模型可能仅凭多数类别预测达到高准确度,但对于少数类别的识别能力却不足,通过下面的ROC曲线图可以明显的看出模型存在过拟合

shap值计算
import shapexplainer = shap.TreeExplainer(xgboost)# 计算shap值为numpy.array数组shap_train = explainer.shap_values(X_train)shap_train = pd.DataFrame(shap_train, columns=X_train.columns)# 计算shap值为numpy.array数组shap_test = explainer.shap_values(X_test)shap_test = pd.DataFrame(shap_test, columns=X_test.columns)shap_test
使用SHAP库计算了训练集和测试集数据的SHAP值,并将其转换为DataFrame格式,以便更方便地查看和分析每个特征对模型预测的贡献
计算特征与目标变量的相关性
from scipy.stats import pointbiserialr# 对于每一列特征,计算其与 y_train 和 y_test 的点二列相关系数# 计算 shap_train 与 y_train 的点二列相关系数train_correlations = []for column in shap_train.columns: correlation, _ = pointbiserialr(shap_train[column], y_train) train_correlations.append((column, correlation))# 计算 shap_test 与 y_test 的点二列相关系数test_correlations = []for column in shap_test.columns: correlation, _ = pointbiserialr(shap_test[column], y_test) test_correlations.append((column, correlation))# 将结果保存为 DataFrametrain_corr_df = pd.DataFrame(train_correlations, columns=[Feature, Point-Biserial Correlation])test_corr_df = pd.DataFrame(test_correlations, columns=[Feature, Point-Biserial Correlation])test_corr_df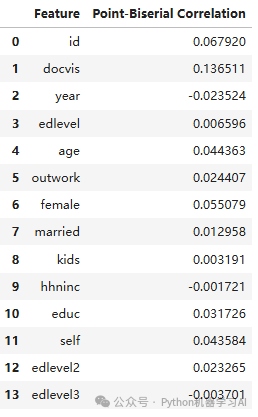
计算训练集和测试集中特征的SHAP值与目标变量y_train和y_test之间的点二列相关系数,并将结果保存为DataFrame格式。这里使用点二列相关系数,因为特征的SHAP值是连续变量,而目标变量是二分类变量,因此选择这种相关系数来衡量它们之间的关系,如果目标变量是连续性变量更推荐采用偏相关性用于剔除潜在的混杂因素,以便更准确地衡量两个变量之间的真实关系,当然也可以提取shap值的主效应值不采用shap值来做相关性
可视化训练集、测试集相关性

绘制一个散点图,展示训练集和测试集中特征的点二列相关系数之间的关系,理想情况下,特征应该位于对角线附近或完全重合,说明该特征在训练集和测试集上表现一致,表明模型没有过拟合或欠拟合。如果特征位于对角线下方,则表明它在测试集上的表现较训练集差,可能存在过拟合问题
量化点到x=y的距离
# 计算每个点到x=y直线的欧氏距离distances = []for i in range(len(train_corr_df)): x = train_corr_df[Point-Biserial Correlation].iloc[i] y = test_corr_df[Point-Biserial Correlation].iloc[i] distance = abs(x - y) / (2 ** 0.5) # 欧氏距离公式 distances.append((train_corr_df[Feature].iloc[i], distance))# 将特征名和对应的距离转换为DataFramedistance_df = pd.DataFrame(distances, columns=[Feature, Euclidean Distance])# 按照距离排序,距离最大的排在前面distance_df_sorted = distance_df.sort_values(by=Euclidean Distance, ascending=False)distance_df_sorted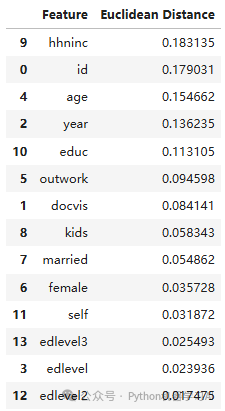
计算每个特征在训练集和测试集之间的点二列相关系数的欧氏距离,并将这些距离按照从大到小的顺序排序。这样做的作用是帮助识别哪些特征在训练集和测试集之间表现差异最大,从而可能揭示出哪些特征可能存在过拟合
特征剔除训练模型
from sklearn.metrics import roc_auc_score# 初始化XGBoost模型xgboost = XGBClassifier(random_state=42)# 初始化结果记录列表results = []# 逐步训练模型,按特征欧氏距离排序逐个剔除特征remaining_features = distance_df_sorted[Feature].tolist()for i in range(len(distance_df_sorted)): # 获取当前要剔除的特征 if i == 0: removed_feature = "no" # 第一次训练,不剔除特征 else: removed_feature = distance_df_sorted[Feature].iloc[i - 1] # 获取剔除的特征 # 选择要使用的特征(排除当前要剔除的特征) selected_features = remaining_features[i:] # 剩下的特征 X_train_selected = X_train[selected_features] X_test_selected = X_test[selected_features] # 使用XGBoost训练模型 xgboost.fit(X_train_selected, y_train) # 预测训练集和测试集的ROC-AUC值 train_pred = xgboost.predict_proba(X_train_selected)[:, 1] test_pred = xgboost.predict_proba(X_test_selected)[:, 1] # 计算ROC-AUC值 train_roc_auc = roc_auc_score(y_train, train_pred) test_roc_auc = roc_auc_score(y_test, test_pred) # 记录结果 results.append([removed_feature, train_roc_auc, test_roc_auc])# 将结果保存为DataFrameroc_auc_df = pd.DataFrame(results, columns=[Removed Feature, Train ROC-AUC, Test ROC-AUC])roc_auc_df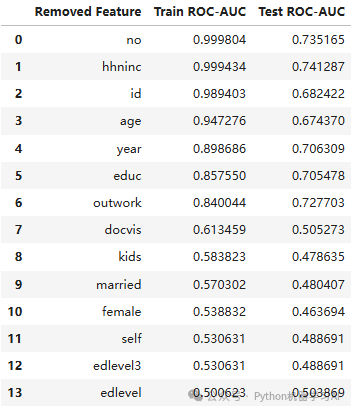
通过逐步剔除特征(按照欧氏距离排序)来训练 XGBoost 模型,并计算每次训练后训练集和测试集的 ROC-AUC 值,从而评估剔除不同特征对模型性能的影响
可视化结果
# 将数据框中的“Removed Feature”列转换为字符串类型,用于绘图roc_auc_df[Removed Feature] = roc_auc_df[Removed Feature].astype(str)# 创建折线图plt.figure(figsize=(12, 6))# 添加浅灰色的网格虚线plt.grid(True, linestyle=--, color=lightgrey, alpha=0.5)# 绘制训练集和测试集的AUC折线图plt.plot(roc_auc_df[Removed Feature], roc_auc_df[Train ROC-AUC], label=Train ROC-AUC, color=b, marker=o)plt.plot(roc_auc_df[Removed Feature], roc_auc_df[Test ROC-AUC], label=Test ROC-AUC, color=g, marker=o)# 设置标题和标签,字体加粗plt.title(Train vs Test ROC-AUC by Removed Feature, fontsize=16, fontweight=bold)plt.xlabel(Removed Feature, fontsize=14, fontweight=bold)plt.ylabel(ROC-AUC Score, fontsize=14, fontweight=bold)# 设置x轴标签旋转和字体大小plt.xticks(rotation=45, ha="right", fontsize=12)plt.yticks(fontsize=12)# 添加图例plt.legend()plt.savefig("2.pdf", format=pdf, bbox_inches=tight, dpi=1200)plt.tight_layout()plt.show()
绘制了训练集和测试集的ROC-AUC随着特征逐步剔除的变化折线图。结果显示,当剔除到outwork特征时,模型的过拟合现象有所缓解,测试集的ROC-AUC逐渐接近训练集,表明模型的泛化能力得到了改善,接下来绘制剔除到outwork特征时剩余特征所构建模型得到的ROC曲线图

通过比较前后两张ROC曲线 的图表,可以看到,经过特征剔除处理后,模型的AUC从训练集上的0.84降低至 0.73,而测试集的AUC从0.732到0.728,表明模型的过拟合现象有所缓解。具体来说,在剔除某些特征后,训练集和测试集之间的差距缩小了,模型的泛化能力有所提高
不过,需要强调的是,这种方法只是提供了一种思考方向。虽然特征的剔除可能有助于缓解过拟合,但这并不意味着被剔除的特征对模型的预测没有任何帮助。这里的分析只是为了提示,在面对过拟合时,除了调参,还可以尝试通过特征选择等方式来改进模型的泛化性能,方法效果的具体情况仍然需要通过实验验证,完整代码与数据集获取:如需获取本文的源代码和数据集,请添加作者微信联系
往期推荐
SHAP值+模型预测概率解读机器学习模型的决策过程聚类与解释的结合:利用K-Means聚类辅助SHAP模型解释并可视化期刊配图:RFE结合随机森林与K折交叉验证的特征筛选可视化期刊配图:变量重要性排序与顺序正向选择的特征筛选可视化期刊配图:SHAP可视化改进依赖图+拟合线+边缘密度+分组对比期刊配图:SHAP蜂巢图与柱状图多维组合解读特征对模型的影响基于mRMR筛选和递归特征选择的多模型性能评估与AUC可视化对比期刊配图:SHAP可视化进阶蜂巢图与特征重要性环形图的联合展示方法期刊配图:基于t-sne降维与模型预测概率的分类效果可视化 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~
个人观点,仅供参考
