
近日,上海财经大学统计与数据科学学院教授张立文与其领衔的金融大语言模型课题组(sufe-aiflm-lab)联合财跃星辰、数据科学和统计研究院、滴水湖高级金融学院正式发布首款deepseek-r1类推理型人工智能金融大模型:fin-r1,以仅7b的轻量化参数规模展现出卓越性能。fin-r1基于qwen2.5-7b-instruct模型开发,通过构建高质量金融推理数据集与两阶段混合框架训练,实现了金融推理的逻辑闭环,其技术创新表明高校在垂直领域大模型研发中实现了从技术突破到产业落地的闭环,标志着高校在金融科技领域的自主创新迈入新高度。

github 地址:https://github.com/sufe-aiflm-lab/fin-r1
技术报告:https://arxiv.org/abs/2503.16252
模型地址:https://huggingface.co/sufe-aiflm-lab/fin-r1
01
简介
当前推理型大语言模型在众多领域正迅速发展,然而当通用推理模型落地金融领域时,仍面临垂直场景适配性不足的挑战。金融推理任务常涉及法律条款、经济指标、数理建模等知识,不仅需要跨学科知识融合,更要求可验证的、分步骤的决策逻辑。在实际的金融业务场景中,模型应用普遍面临知识整合困难、决策过程不透明、业务泛化能力不足等问题。
为此,我校团队从多个权威数据源蒸馏并筛选出约 60k 条面向金融专业场景的高质量 cot 数据集 fin-r1-data,该数据集涵盖中英文金融垂直领域的多维度专业知识并根据具体任务内容将其分为金融代码、金融专业知识、金融非推理类业务知识和金融推理类业务知识四大模块,可有效支撑银行、证券以及信托等多个金融核心业务场景。在 fin-r1-data 数据的基础上以 qwen2.5-7b-instruct 为基座进行指令微调 (sft) 预热和强化学习 (rl) 训练得到金融推理大模型 fin-r1。通过构建金融高质量 cot 数据集与结合指令微调(sft)和强化学习(rl)进行训练的两阶段工作框架为模型在金融领域的应用提供了坚实的理论支撑、决策逻辑以及技术实现能力,同时能有效提升模型的金融复杂推理能力和泛化能力,使模型在金融推理任务中展现出卓越性能。
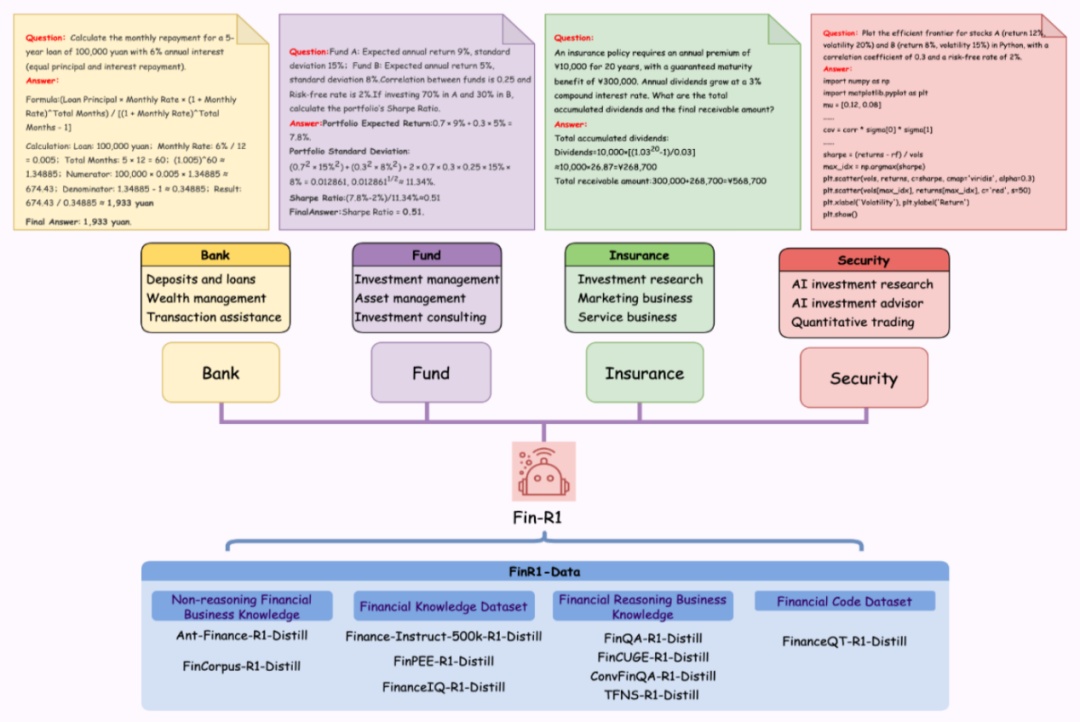
图 1 fin-r1 应用场景示例
fin-r1 的总体工作流程如下:首先通过构建 60k 规模的金融推理数据集 fin-r1-data,帮助模型重构知识体系,然后采用 "两步骤训练框架" 塑造模型认知和推理能力,最后在多个金融基准测试上验证模型的性能突破,实现了从 “数据构建 - 模型训练 - 性能验证 - 模型部署 - 场景应用” 的完整技术闭环。
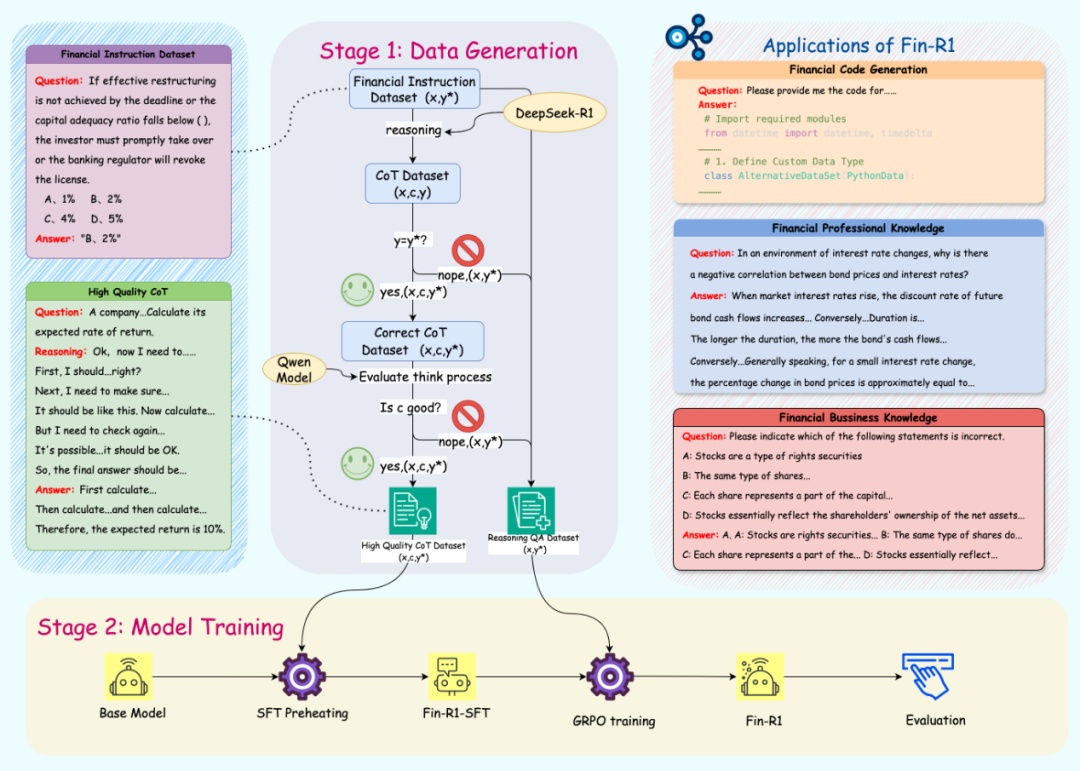
图 2 fin-r1 总体工作流程
02
场景应用
强大的多场景适配能力
金融代码是指在金融领域中用于实现各种金融模型、算法和分析任务的计算机编程代码,涵盖了从简单的财务计算到复杂的金融衍生品定价、风险评估和投资组合优化等多个方面,以方便金融专业人士进行数据处理、统计分析、数值计算和可视化等工作。

金融计算是对金融领域的各种问题进行定量分析和计算的过程,其核心在于通过建立数学模型和运用数值方法来解决实际金融问题,可为金融决策提供科学依据,帮助金融机构和投资者更好地管理风险、优化资源配置和提高投资回报率。

英语金融计算强调在跨语言环境下使用英语进行金融模型的构建和计算,并能够以英语撰写金融分析报告和与国际同行进行沟通交流。

金融安全合规聚焦于防范金融犯罪与遵守监管要求,帮助企业建立健全的合规管理体系,定期进行合规检查和审计,确保业务操作符合相关法规要求。

智能风控利用 ai 与大数据技术识别和管理金融风险,与传统风控手段相比,智能风控具有更高的效率、准确性和实时性,它通过对海量金融数据的深度挖掘和分析,能够发现潜在的风险模式和异常交易行为,从而及时预警和采取相应的风险控制措施。

esg 分析通过评估企业在环境(environmental)、社会(social)、治理(governance)的表现,衡量其可持续发展能力,确保投资活动不仅能够获得财务回报,还能促进可持续发展和社会责任的履行。金融机构和企业也通过提升自身的 esg 绩效,来满足投资者和社会对企业更高的期望和要求。

03
数据构建
破解知识碎片难题
传统的金融数据分散、标注成本高,而且缺乏对复杂推理逻辑的针对性设计,导致模型难以适配金融业务场景,为将 deepseek-r1 的推理能力迁移至金融场景并解决高质量金融推理数据问题,用 deepseek - r1(满血版)针对涵盖行业语料(fincorpus、ant_finance),专业认知(finpee),业务知识(fincuge、financeiq、finance-instruct-500k),表格解析(finqa),市场洞察(tfns),多轮交互(convfinqa)以及量化投资(financeqt)的多个数据集进行领域知识蒸馏筛选,构建了约 60k 条面向专业金融推理场景的高质量 cot 数据集 fin-r1-data 。
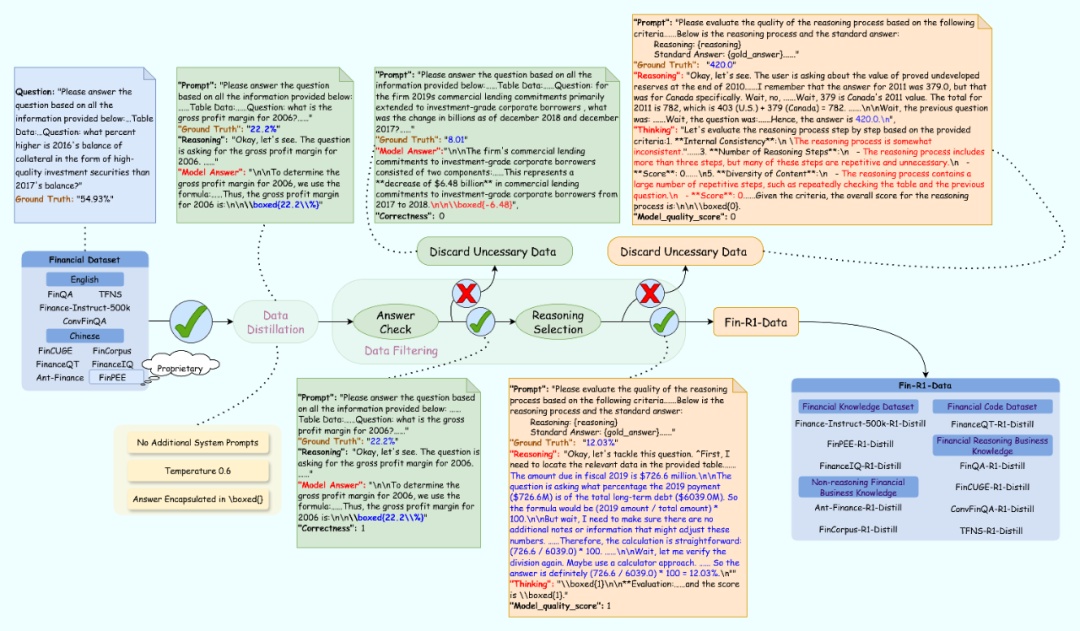
图 3 fin-r1 数据生成流程
04
性能验证
专业场景性能超越,验证技术闭环价值
fin-r1 的评测表现不仅反映出模型在投顾服务、投资者会议等多轮交互场景中具有长对话跟踪能力,能避免传统模型常见的上下文遗忘或逻辑跳跃问题并生成逻辑连贯的渐进式建议,同时展现出模型在处理财务报表重组、财务比率交叉验证时的强大数值推理能力。精准覆盖金融行业对可解释性、合规性、数值严谨性的核心诉求。
05
模型部署
github 现已提供 "开箱即用" 的本地化部署方案,只需运行一个安装脚本,就能在单张 4090 显卡上轻松部署 fin-r1 模型。无论是银行风控还是量化交易,用户都能快速上手,解决各类金融场景问题,真正实现 "一键部署,金融 ai 触手可及"!
fin-r1 从训练框架到模型权重均开源,计算资源需求量小,个人电脑即可部署,更加适用于金融场景,并且通过两阶段训练框架,解决了金融数据碎片化和推理逻辑不可控等问题,在各大金融基准测试中表现卓越,展现出强大的推理能力和业务泛化能力,为金融智能化发展提供了有力支持。
来源 | 统计与数据科学学院
编辑 | 烟文雪 校对|李京烁
审核|曹东勃 施蕾
上观号作者:上海财经大学
