
关键词人工智能 机器学习 大语言模型
作者简介
程雨涵( 山东大学管理学院)
邹杰(山东大学经济学院)
梁钧霆(北京大学国家发展研究院 北京大学全球健康发展研究院)
刊 期2024年第5期
一、引言
人工智能技术是通过特定的算法来模拟人类智能行为的技术,它具备感知环境、进行学习、执行推理以及做出决策等能力。随着数据量和计算能力不断提升,人工智能已成为引领未来科技发展的重要战略领域和各国竞相布局的核心战略重点。习近平总书记指出,人工智能是新一轮科技革命和产业变革的重要驱动力量,将对全球经济社会发展和人类文明进步产生深远影响。深入挖掘人工智能在经济金融领域的应用潜力,探索人工智能在经济金融领域更高水平应用的可行道路,对大力提升经济金融学科的实用价值具有极强的战略意义。
然而,机器学习方法不是计量经济学方法的完全替代品,也并非是计量经济学方法的附庸,它是与计量经济学相辅相成但又不失其独立性的一套重要方法。本文通过厘清机器学习与计量经济学的异同,总结机器学习相较于传统计量经济学的显著优势及机器学习在经济金融领域作出的边际贡献,以展示现有研究者如何通过“扬长避短”以实现机器学习对经济金融实证研究的有益补充,也为后继研究者提供有益借鉴。
二、机器学习概述及与传统计量经济学方法的异同
三、机器学习方法在经济金融研究的应用
相较于传统计量经济学方法,机器学习方法既有如灵活性更高的“精华”,又有解释性不足的“糟粕”。已有研究通过对机器学习方法“扬长避短”,成功摸索出机器学习应用在经济金融领域研究中的“三板斧”,实现对经济金融领域的研究补充和完善。
(一)“三板斧”
“第二板斧”:另类数据处理。另类数据(如文本、图像和语音)中蕴含着极为丰富的有价值信息,如市场情绪、政策不确定性等。但在与机器学习方法密切相关的自然语言处理技术和计算机视觉技术出现之前,经济金融领域的研究无法有效地利用文本、图像和语音等另类数据。例如,若想在海量文本、图片数据中测度政策不确定性,传统的方法可能是依赖于人工打分,但依靠人力难以避免主观性的影响,需要一个始终能保持“客观”的主体对这些文本、图像等另类数据进行统一处理。机器学习方法就可以实现这一客观性,特别是近年来广泛应用的深度学习方法,实现了对另类数据中的有价值信息进行充分提取,并构建代理变量对其进行测度,极大地拓宽了经济金融研究中可使用数据的范围,拓展了研究的边界和可能。
(二)案例分析
机器学习方法凭借上述“三板斧”在经济金融领域的研究中得到广泛应用,特别是在变量预测、另类数据处理和因果推断等多个领域的研究中取得重要突破。图1总结了这些应用的具体研究问题及与“三板斧”之间的联系。
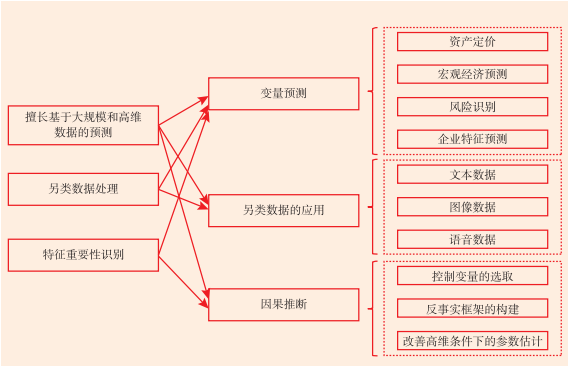
图1 机器学习在经济金融研究领域的具体应用导图
1.变量预测
(1)资产定价。追求更精确的资产价格与收益预测是资产定价的重要目标,机器学习算法在对股票、债券、期权等金融资产未来收益的预测中均展示出了优异的性能。特别是股票市场,应用最为广泛。Chinco 等(2019)指出传统研究中“根据直觉提出预测因子并验证”的方法无法找出未预期到的、短期存在且稀疏的因子。因此,提出一种“数据驱动”的方法:利用LASSO模型,将整个滞后收益截面作为潜在的预测变量,实施滚动式的提前一分钟收益预测。随后,诸多学者在不同股票市场研究了机器学习方法在预测股票风险溢价方面的表现,其中以美国股票市场为主(Gu et al., 2020;Gu et al., 2021;Dong et al., 2022;刘莉等,2024),亦不乏中国等发展中国家股票市场有关的研究(李斌等,2017;李斌、龙真,2023;林昱等,2022;陈炜等,2023),上述研究均发现机器学习方法相较于传统方法能够有效提高预测准确度以及收益的夏普比率。以GPT系列为代表的大语言模型的出现也为股票市场研究注入新的活力。Cheng 和 Tang(2024)提出一种利用GPT-4模型的知识推理等能力自主生成市场因子的新方法,这种方法在资产收益预测方面比传统机器学习方法具有更好的性能;Cheng等(2024)探索了大语言模型在财务分析中的新应用。
(2)宏观经济预测。传统的宏观经济预测方法包括时间序列分析、动态随机一般均衡(DSGE)等方法,存在多种局限性。机器学习在处理非线性关系、交互效应以及高维变量等方面具有显著优势,可以有效弥补传统方法的不足,在宏观经济预测领域展现出巨大潜力(Goulet Coulombe, 2022)。现有研究基于机器学习算法,结合传统宏观经济数据和文本数据,显著提高了对通货膨胀、消费增长和GDP增速等重要宏观经济指标的预测精度(Hong et al., 2022;Kalamara et al., 2022;张一帆等,2023;Zheng et al., 2024)。
2. 另类数据的应用
除了指标测度,机器学习还可以进行文本数据的情绪测度(宫晓莉等,2024;范小云等,2022a),如从文本中判断乐观或悲观等情绪特征,涉及的主要技术是向量机、朴素贝叶斯等有监督学习模型(Ke et al., 2019),应用情景十分丰富,包括分析师研究报告文本语调分类(吴武清等,2020)、税法宣传报道内容分类(毛捷等,2022)和上市公司研究报告中的特质信息测度(伊志宏等,2019)等。
尽管较传统方法而言,机器学习方法已经大幅度提升了非结构化文本数据测度的精度,但仍然存在诸如掺杂主观性而导致客观性不足等问题,以Chat GPT为代表的大语言模型基本解决了机器学习方法在处理另类数据中存在的问题。大语言模型基于以自注意力机制为核心的变换器(Transformer)架构,具有高度复杂的结构和庞大的参数规模,能够在预训练阶段(Pre-train)根据庞大的语料库学习语言的通用表示,并通过微调(Finetune)进一步掌握深度理解语义和语境的能力。大语言模型的横空出世使得文本数据在经济金融研究中的应用突破了原有瓶颈(Chen et al., 2022b;刘青、肖柏高,2023;Kim et al., 2024)。大语言模型在另类数据处理中的一个典型应用场景是对企业数字化转型的测度,金星晔等(2024)使用大语言模型ERNIE实现了对企业所使用数字技术的预测分类,为企业数字化转型的测度难题提出了一个解决思路。
除了文本数据外,图像、语音数据中包含了市场情绪、资产价格走势等丰富的、有价值的信息。卷积神经网络(CNN)的诞生使得将图像这一非结构化数据用于经济金融领域的研究中成为可能。现有研究者凭借卷积神经网络在图片分类等方面展示出的优越性能,成功实现了基于股票价格序列的图像预测股票未来涨跌趋势或市场回报逆转(Jiang et al., 2023; Obaid and Pukthuanthong, 2022)。Edmans等(2022)则通过分析人们收听歌曲的偏好,使用机器学习方法创建了一种全球可比的国家情感测量方法,探讨了音乐情绪与股票市场波动之间的关系,是非结构化音乐数据在金融领域的首次应用。
3. 因果推断
二是在反事实框架构建方面。传统的计量模型隐含线性假设,而这在复杂的现实环境中往往难以成立。机器学习可以在没有严格的假设约束下,更加灵活地处理非线性关系和高维变量,更精确地构建反事实,进而提升因果推断的精度和可靠性。现有研究将机器学习方法引入基于双重差分和合成控制法(Doudchenko and Imbens, 2016)以及工具变量(Hartford et al., 2017)的因果推断方法中,以提升反事实预测能力。如孙三百等(2023)和史新杰等(2022)在研究机会差异与财富不平等问题中均使用了机器学习方法进行反事实构建。
三是高维条件下因果推断的参数估计方面。因果关系的精确推断依赖于参数估计的准确性,而在当今大数据时代,数据具有更复杂的结构以及更高的维度,基于传统统计方法的因果推断参数估计正面临极大的挑战。机器学习方法可以帮助研究者获得关于平均处理效应(ATE)和处理组平均处理效应(ATTE)的有效推论,即使在存在大量潜在混杂因素的情况下也能保持估计的准确性(Chernozhukov et al., 2017)。
因果森林、双重机器学习等方法结合了机器学习在处理复杂数据结构方面的能力与传统的统计推断框架,为因果推断提供了一种强大的工具。Wager 和 Athey(2018)通过开发非参数因果森林算法来估计治疗效应的异质性,为从随机森林中进行有效统计推断提供了理论支持,并在实验中显示出比传统最近邻匹配方法更高的效能,特别是在处理无关协变量方面。另外,现有研究使用双重机器学习框架克服传统因果推断方法的线性假设局限,并且提升了高维控制变量下的参数估计精度(倪宣明等,2023)。而Athey等(2021)通过评估不同估计量在无混淆条件下平均处理效应的稳健性,发现不存在普遍最优的估计量,并强调根据具体情境定制分析方法和进行系统性模拟研究的重要性。除平均处理效应外,研究者也致力于使用机器学习方法改善IV的参数估计(Hansen and Kozbur, 2014; Carrasco, 2012),为高维工具变量情境下的参数估计提供了新的解决方案。
四、不足与应对之道
(一)模型的透明度、可解释性不足
机器学习方法的可解释性分为事前可解释性和事后可解释性,其中事前可解释性是指模型自身架构设计是否清晰可理解;事后可解释性则指借助解释性技术来理解训练好的模型的难易程度。事后可解释性又分为全局可解释性和局部可解释性(纪守领等,2019),全局可解释性是指理解模型如何从训练数据中学到从输入到输出的函数表示,即模型是如何根据训练数据进行学习和预测的;而局部可解释性则是指理解模型的单个预测,即模型为何对某一特定实例做了特定预测。
可解释性不足的问题已然成为机器学习在经济金融领域应用中的绊脚石,未来如何保证机器学习方法预测精度这一优势的同时,通过优化模型结构以提升事前可解释性和开发新的解释性技术以增强事后可解释性,将是机器学习研究的重点突破方向。
(二)高度依赖于训练数据的质量和可用性
作为数据驱动模型,机器学习模型的性能取决于训练数据的质量和可用性,机器学习普遍面临的“小样本”、噪声过多等问题都会削弱模型对数据生成过程中真实函数的拟合能力(Wang and Hebert, 2016; Ying et al., 2021),不利于机器学习模型的样本外预测表现,特别是基于神经网络的深度学习模型由于具有更加庞大的参数规模,需要更大量的样本以保障模型预测表现。而经济金融领域的数据往往质量和可用性不尽如人意,如一些宏观经济数据的更新频率低,“小样本”问题突出;金融市场存在明显的低信噪比问题(Chen et al., 2023),加之我国金融市场起步相对较晚,存在样本期过短的问题。因此,如何使机器学习模型在低信噪比、“小样本”等条件下取得更好的预测表现是一个亟待解决的问题。Chen等(2023)尝试使用迁移学习解决上述问题,利用结构模型的理论基础和解释能力指导深度学习模型的学习过程,以提高深度学习模型在数据质量和可用性限制下的预测精度和适应性。
(三)数据安全问题
机器学习作为一种纯数据驱动的方法,依赖高频、高维的大数据,在数据获取、处理及应用的过程中面临数据安全和隐私保护等问题。例如,很多大数据的构建是通过爬虫方法获取的,爬虫行为的合法合规性无法完全保证。近年来,我国政府的各个部门陆续颁布了数据安全管理办法,显示了我国在维护数据安全方面的决心,因此在享受大数据给机器学习方法带来有效支撑的同时,也要确保数据来源的合法性。机器学习方法本身处理数据的能力较强,当使用机器学习在文本中获取另类数据时,如果原始文本包含了涉及隐私问题的信息,应当注意对数据进行脱敏、匿名化等特殊处理。
五、结论
当前大数据和算力迅速增长,人工智能取得蓬勃进展,已成为引领未来科技发展潮流的重要战略性新兴领域。其中,机器学习作为人工智能的前沿技术,在经济金融领域研究中得到广泛应用,与自然语言处理技术(NLP)及计算机视觉技术(CV)共同为经济金融领域的研究提供了新的研究视角。
在未来,随着机器学习算法的进一步优化,以及算力、数据等资源要素的进一步改善,机器学习有望在更复杂、更动态的经济金融系统中提供更具前瞻性和精确度的预测与分析,进而为政策制定提供更有力保障。返回搜狐,查看更多

