
8月6号,真的今夕是何年了。
一晚上,三个我觉得都蛮大的货。
先是晚上10点,Google发了一个世界模型(但期货),Genie 3。
这个非常的强,我看的热血沸腾,我这两天也会单独写一篇文章,来聊聊这个玩意,真的,作为一个这么多年的游戏和VR玩家,看到Genie 3非常的激动。

然后就是12点半,Anthropic突然就发布了Claude Opus 4.1,在编程能力上继续进化。
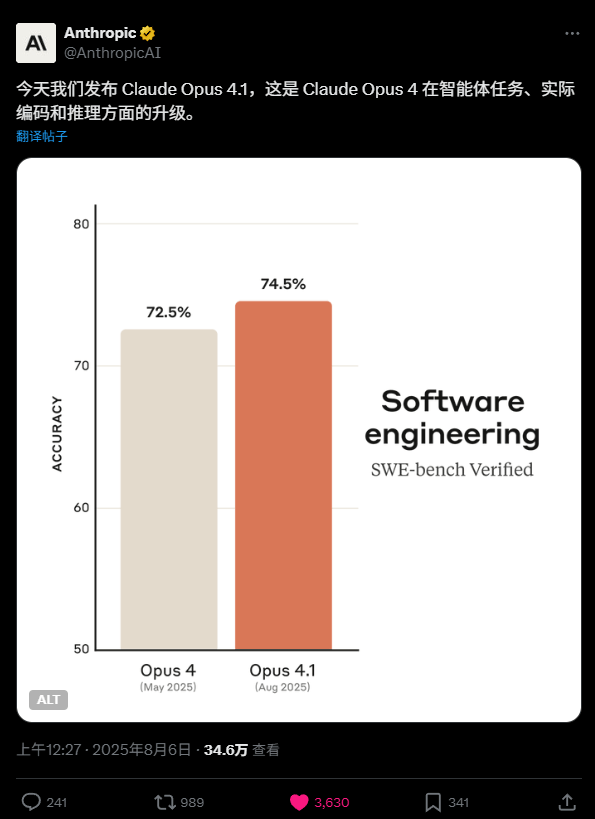
这节奏,感觉就是来狙击OpenAI的。
然后,重头戏来了。
凌晨1点,OpenAI在GPT-2后,在整个ChatGPT世代,官宣发布了他们的第一个开源模型,GPT-oss。
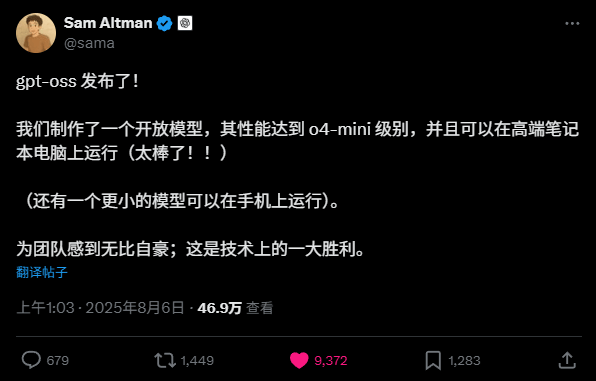
真的,不眠之夜。
直接来聊聊GPT-oss。
很强,非常强,OpenAI终于干了点人事。
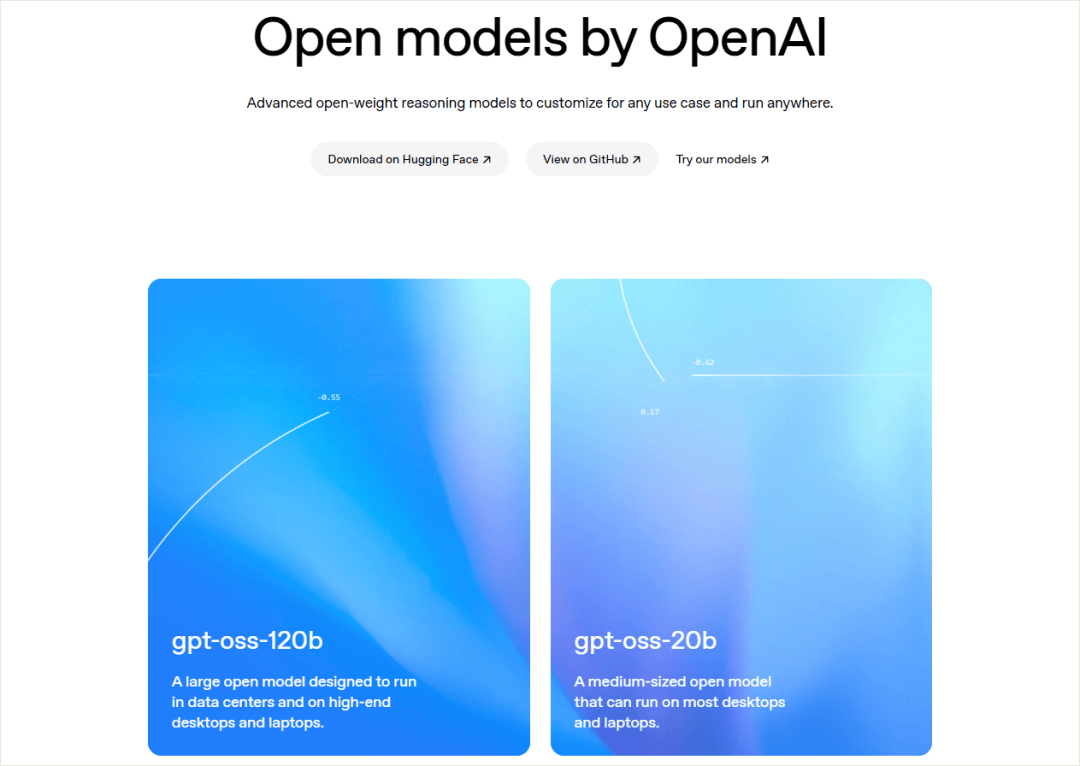
GPT-oss一共开源了两款模型,120B和20B,都是MoE,纯文本、非多模态的推理模型,Apache 2.0 许可,也就是最宽松的那种,你随便用。
120B参数117B,激活参数5.1B。
20B的则209亿参数,激活参数3.6B。
上下文都是128K。
最爽的东西来了,这两模型,是原生支持4-bit量化的。。。
也就是说,20B模型的大小就12.8GB,最低只要16GB内存就能跑,我这个破壁5080的16G卡,也能本地跑的动了20B的gpt-oss了。
而且,这不只是简单的那种事后压缩,就是社区常做的一些量化,那种方式性能会掉一大截。
比如DeepSeek-R1满血版是671B,8-bit精度,少数dense层依旧16 bit,最后的模型大小是720GB。
你想完整的部署它,8张96G的H100才行,如果你想省算力,那就你自己事后搞一层量化,量化到4-bit,这时候,模型体积就会小很多。
但是对等的,性能也会差一些。
而OpenAI是在后期训练的时候,就直接用了一种叫MXFP4的格式来做量化。也就是说,模型在出厂前就已经学会了如何在低精度的环境下工作,所以这种方式,不仅能大幅的缩小模型权重体积,性能损失极小。
比如gpt-oss-20b,总参20.9B,9成以上是MoE专家,被压成MXFP4,4.25 bit/权重,剩下不足一成的主干还是 FP16。
所以20.9B×4.25 bit≈11.1GB,再把那10%左右的FP16算进去,加点 header,模型最终大小就差不多落在了12.8GB,直接一张16G的显卡就能推的动,非常的爽。
120B的模型,也能跑在80G的单卡的,真的牛逼。
这块量化还是挺有意思的,今年6月的时候英伟达也搞了个NVFP4,跟OpenAI这个MXFP4稍微有点类似。

定位都差不多,4 bit速度,接近FP8的精度,还挺好玩的。
这波OpenAI上大分,让我这种本地玩家,也能跑一跑满血版的20B gpt-oss了。
再看看跑分。
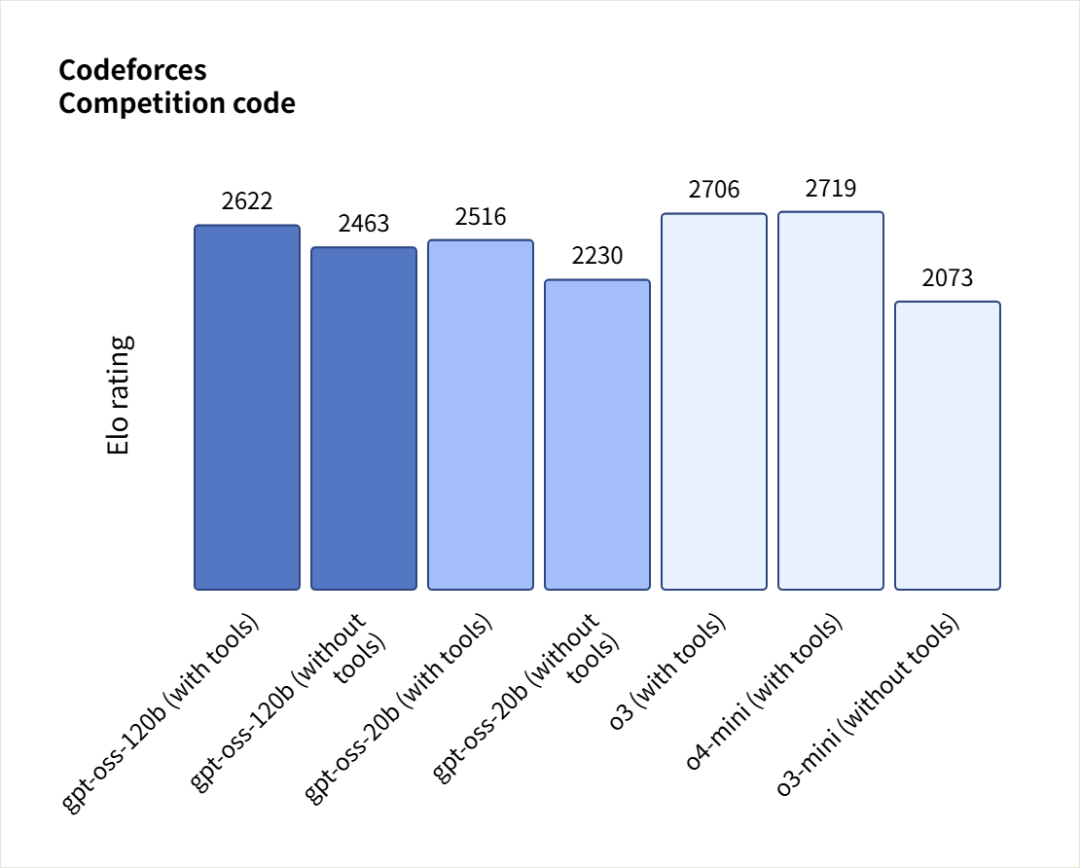
在 Codeforces(带工具)这个竞技编程测试中,gpt-oss-120b 和 gpt-oss-20b 分别获得 2622 分和 2516 分,表现我记得是优于DeepSeek R1的,但逊于o3和o4-mini。
在人类的终极考试中,gpt-oss-120b和gpt-oss-20b 的得分分别为19%和17.3%,低于o3。
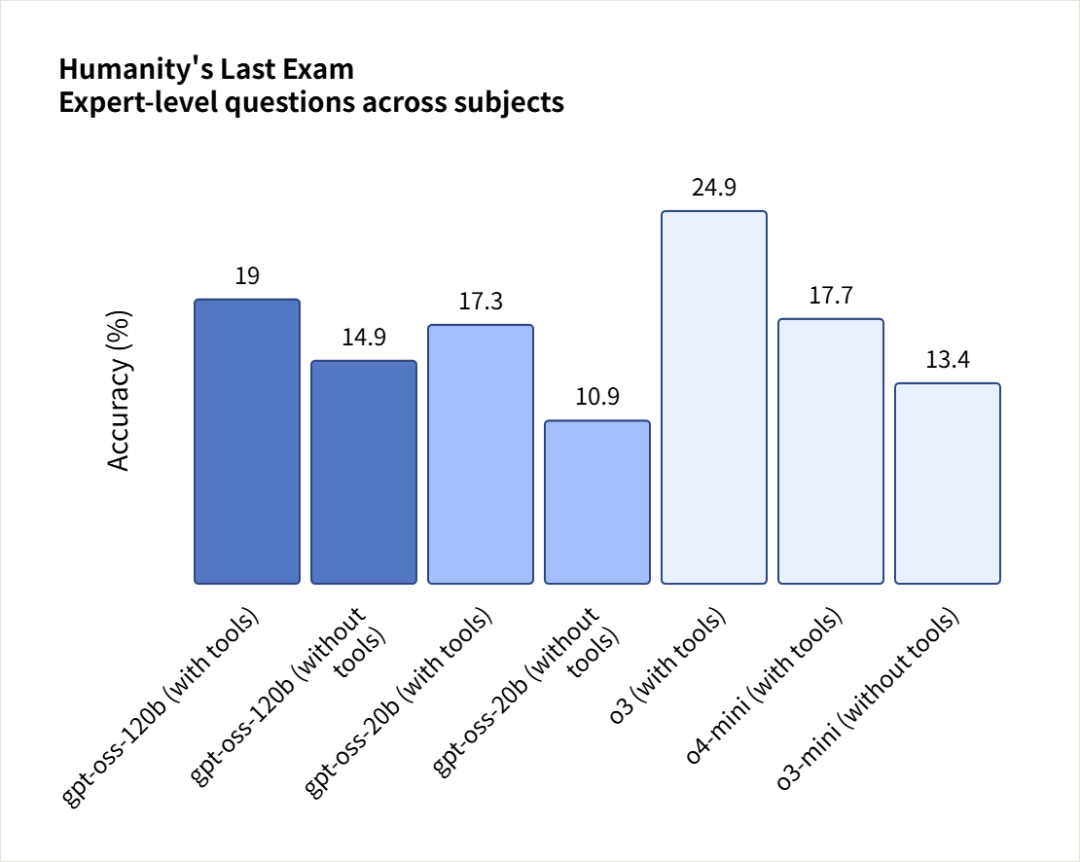
不过OpenAI这个跑分其实非常的不直观,因为只跟自己对比,挺狗的,正好前端时间差不多同尺寸的Qwen3和GLM-4.5也都发了,群友@洛小山 就把大家同尺寸模型的跑分都整合了一下。
结果不看不知道,一看吓一跳。
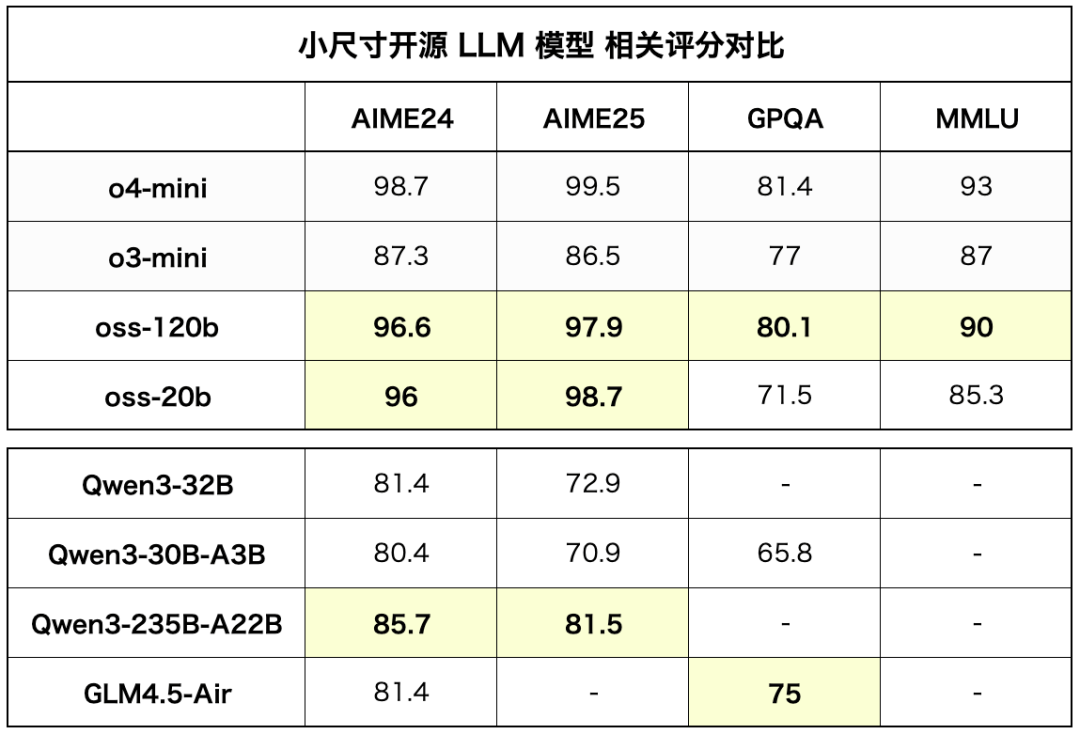
在同尺寸下,几乎是傲视群雄,没有敌手。
说说在哪用。
OpenAI自己做了一个在线的网站,供大家试用:
https://gpt-oss.com/
但是卡的一笔,经常动不了。
所以,你也可以在OpenRouter上用,他们已经第一时间支持了gpt-oss。
https://openrouter.ai/
比较可惜的是,截止到凌晨4点,我最常用的模型平台硅基流动还没支持gpt-oss,估计睡了。。。
此处对硅基流动工作人员喊话:快上模型。。。
而如果你想本地用的话,也可以直接下载一个Ollama。
https://ollama.com/
Ollama现在支持UI界面了,好用很多。
下载安装完Ollama之后,你就可以在这个地方选择模型。
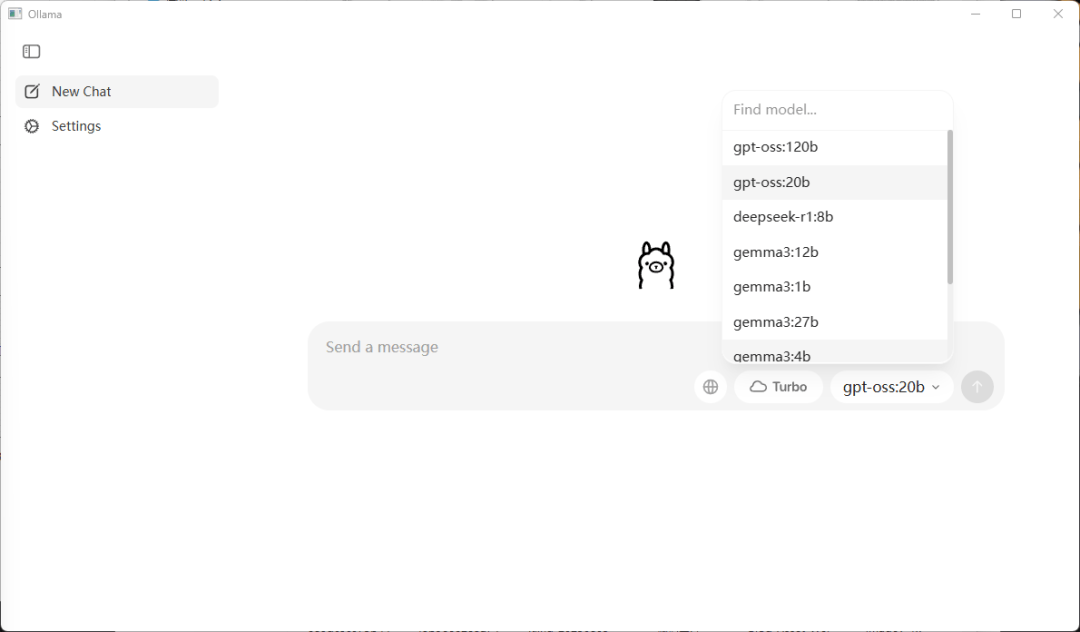
选完了以后,随手发个1或者你好之类的。
模型就会自动开始下载了。
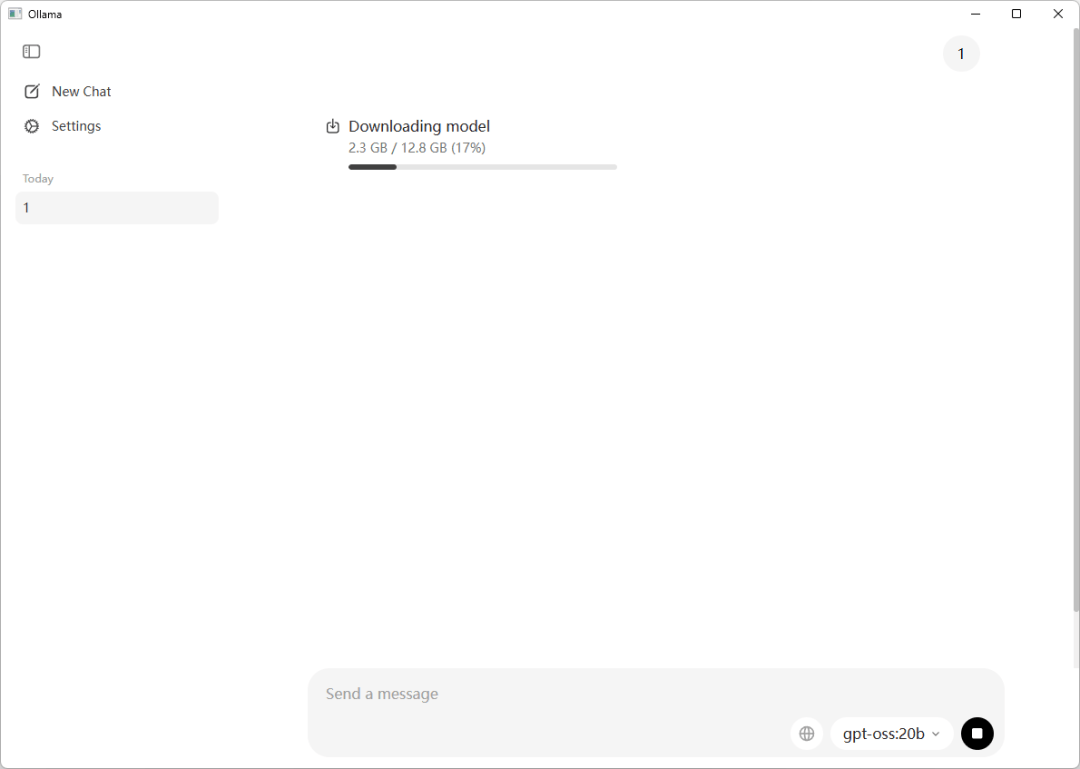
但是这个地方稍微注意一下,不要自不量力= =
20B的模型至少需要16G的显卡才能跑。
120B的模型至少需要80G。
没到的就别下模型了,老老实实去硅基流动或者OpenRouter接个API用就行。
我自己部署了一下20B,用了下,速度确实是快,而且快的离谱。
还是群友@洛小山 做了个对比。
在别的还在慢悠悠的跑的时候,gpt-oss-20B只花3秒就解决了战斗。
你用的时候就感觉,飞一样的感觉。
我自己也测了下代码审美,老样子,跑跑固定case像素弹球大师。
结果120B的给我看不会了,虽然能玩,但是真的丑。
emmmmmm。
至于20B的,就玩不了。。。
然后又在群里,看到了一张梗图。
一下子笑不活了。
而在推理和知识层面,确实还不错。
20B的模型,做这些烧脑的推理题,真的绰绰有余了。
写作文笔这块,我有一个常用的提示词:
"你是一位久负盛名的小说家,文字极富感染力,风格细腻,善于挖掘和表达复杂的情绪与心理。现在,给你一个场景:
夜晚十一点半,你独自坐在一列开往远方的小城的绿皮火车上,车厢内昏暗的灯光时明时灭,窗外掠过荒凉的村庄、星星点点的灯火、偶尔传来的犬吠,车厢内空气沉闷、混杂着烟草与泡面的味道。你对目的地怀着某种难言的情绪,夹杂着期待、犹豫、忐忑甚至是恐惧。
请你使用第一人称,以细腻且富有感染力的文字,深入描写你此刻的内心活动和车厢内外的细节,尤其要注重细节密度、情绪层次和氛围营造,不少于500字。"
能比较清楚的对比看出来模型的写作功底。
比如这个就是GPT4.5的。
这个是Gemini 2.5 Pro的,都还不错。
而gpt-oss 20B的文笔,是这样的。
不跟GPT4.5和Gemini 2.5 Pro比,在同尺寸模型中,还是不错的,微调一下,应该能很棒的处理很多垂直任务。
就是我自己实测中发现,幻觉还是有一点不低的。
比如我问它,三体里云天明的三个小说是什么。
直接给我来了个,打底三部曲???
还有NASA第四个登月的明明是Alan Bean,这个爱德华安德森是个什么鬼。
不过这毕竟是个20B的模型,虽然代码拉,幻觉有点高,但是在推理能力和数学能力上都很强了。
整体来看,确实在本地的消费级模型上,是很好也是很实用的。
后面微调一下,应该能干不少事,又燃起了我的斗志。。。
到时候后续也可以分享一下gpt-oss的微调教程和应用场景。
讲道理,OpenAI能把这事干出来,还是之前被DeepSeek给逼急了。
虽然每次看到OpenAI磨磨唧唧藏着掖着,我都会骂它一顿,但这次,确实真的可以给它鼓个掌了。
gpt-oss确实够诚意满满,够硬气,也足够改变未来开源社区的格局了。
这次OpenAI开了一个很好的头,拉低了门槛,提高了上限,让AI圈子的玩法更丰富了。
咱就是说,要不然,就Open到底。
周四不是发GPT-5吗?
索性,把GPT-5也开源了。
可好?返回搜狐,查看更多

