
在大型语言模型(LLM)中,预训练和微调是两个关键步骤,它们共同决定了模型的性能和适应性。
预训练
预训练是模型学习的初始阶段。在这个阶段,模型会在一个巨大的未标记文本语料库上进行训练,学习语言的结构、语义关系和上下文信息。预训练的目标通常是通过语言模型任务(如预测下一个词或填补句子中的空白)来让模型学习广泛的语言表示1。预训练的主要特点包括:
无监督学习:模型在没有明确指导或标签的情况下从未标记的文本数据中学习。 捕获语言模式:通过大量数据,模型能够捕捉到语言的深层次规律和知识。 Transformer架构:预训练通常采用基于Transformer的架构,因为这种架构擅长捕获远程依赖关系和上下文信息。微调
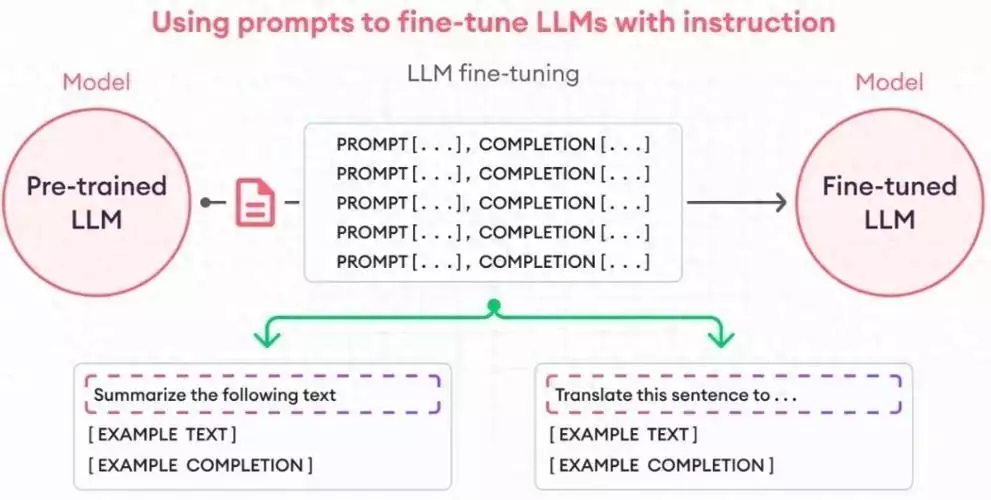
微调是在预训练完成后,针对特定任务或领域对模型进行进一步训练的过程。微调通常是在特定任务的数据集上进行,并且目标函数与下游任务直接相关1。微调的主要步骤包括:
冻结部分参数:为了保持预训练模型的初始表示能力,通常会冻结部分参数,使其在微调过程中保持不变。 更新顶层参数:添加新的层并根据目标任务的标签数据进行训练,主要更新这些顶层参数。 调整参数:通过反向传播算法和优化方法,根据目标任务的损失函数来调整模型的参数。预训练与微调的关系
预训练为模型提供了广泛的语言理解基础,而微调则使模型能够针对特定任务进行优化。这种预训练-微调的范式使得模型在各种自然语言处理任务中表现出色,如文本生成、情感分析和问答系统

