OpenAI 在 2025 年 2 月 27 日 发布了 GPT-4.5,这是他们目前最大、知识最丰富的模型。
GPT4.5呈现三大特点,为语言理解和生成出色,编程数学偏弱,价格昂贵。

GPT-4.5 在语言理解和生成方面表现出色,尤其在提升词汇直觉和减少模型“幻觉”(生成不准确或虚构信息)方面有了显著改进。按OpenAI发布会描述,GPT-4.5采用无监督学习模式,GPT-4.5交互将更加自然,它具有更深层次的知识,更好的语言意境理解能力,是目前OpenAI最好的聊天模型。发布会举一个例子,向GPT-4.5发送一个问题:“我的一个朋友又取消了约会,帮我写一条短信告诉他我讨厌他”。

GPT-4.5的短信内容很机智,既表达了不满,同时又不过于严肃或伤感情。
而GPT o1的表现则直接生硬。对比发现,GPT-4.5能够更加理解人的意境,并且善于掌握人的细腻心理,回答更加富有智慧。

不过,大家也看到了GPT-4.5在编程、数据方面不尽理想。据解释,GPT-4.5重心在于无监督学习上的突破,通过大规模预训练和后训练,模型能更好地识别模式、建立联系,甚至生成创意洞察。它语言能力强且可靠,更加适合内容创作者、企业用户。但它不是推理模型,推理能力弱,因此编程和数学能力较弱,属于偏科生。

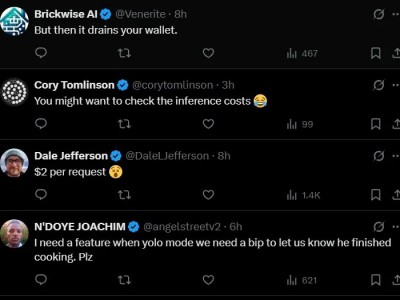
GPT-4.5的另外一个特点,就是价格昂贵。有网友列出GPT-4.5的价格,api输入每百万token要546元,输出要1092元。比deepseek贵了一百多倍。目前GPT-4.5在PRO用户使用,月订阅费200美元。
 最后,就AI大模型的无监督学习和监督学习两种训练模式进行简单分析。无监督学习无需标注数据,从海量未标注数据中自动发现模式和结构。它更适合处理大数据,节省标注成本。比如 GPT-4.5 的预训练就依赖无监督学习,让模型具备“直觉”能力。但是这种方式,目前显示出的问题就是贵。监督学习则需要大量标注数据,学习输入与输出之间的映射关系。在特定任务上精度高,比如 Grok 3 、claude 3.7 sonnet在数学任务中的表现就得益于监督训练。而更优的方法是综合两者的优点,譬如deepseek,采用混合体系训练方法。其核心预训练阶段基于无监督学习(自监督学习),在大规模未标注文本数据上进行;特定任务优化可能涉及监督学习的微调;推理能力提升则加入了强化学习。
最后,就AI大模型的无监督学习和监督学习两种训练模式进行简单分析。无监督学习无需标注数据,从海量未标注数据中自动发现模式和结构。它更适合处理大数据,节省标注成本。比如 GPT-4.5 的预训练就依赖无监督学习,让模型具备“直觉”能力。但是这种方式,目前显示出的问题就是贵。监督学习则需要大量标注数据,学习输入与输出之间的映射关系。在特定任务上精度高,比如 Grok 3 、claude 3.7 sonnet在数学任务中的表现就得益于监督训练。而更优的方法是综合两者的优点,譬如deepseek,采用混合体系训练方法。其核心预训练阶段基于无监督学习(自监督学习),在大规模未标注文本数据上进行;特定任务优化可能涉及监督学习的微调;推理能力提升则加入了强化学习。
因此,未来的方向就是无监督方法和监督学习方法两者的混合。就比如笑傲江湖里面的气宗、剑宗,最终还要融合成一体才爆发出最强武艺。
关注本公众号,回访不迷路。