
原创 张薇 伍之昂 审计观察
在政策跟踪审计中,传统的结构化数据分析方法仅关注资金,存在一定的局限性。本文认为,对非结构化文本数据的自然语言分析能够揭示下级政府传达上级政策的守正和创新情况、各级政府传达政策的异同以及政府传达政策的历时趋势,由此能够为研判审计对象的政策落实情况提供一定的参考,并与其他方式的政策跟踪审计形成补充,从而丰富审计监督内容、延伸审计评价证据链、提升审计监督效能。
按照研究型审计要求,重要政策文件、项目会议纪要、官方新闻报道等反映政策传达情况的文本也属于审计的重点对象。针对文本类非结构化数据,可以使用大数据自然语言分析技术进行加工处理。通过文本对比分析,从大量政策中选择优先关注的政策领域、精准识别关键问题,准确高效确定审计重点,并通过语义智能分析和文本关联研判,考察下级传达上级政策的情况,为审计下级是否落实上级政策提供参考依据。
文本分析对象
“要做好研究型审计,审计机关开展的研究调查覆盖面要尽可能广泛,内容应尽可能详细,通过获取大量、真实、全面、最新的调查数据,拓宽研究型审计的研究范围”(晏维龙,2021)。鉴于此,被审计单位的相关资金、项目所关联的国家重大政策及地方政策细则,其所涉及地方日报报道,以及本单位会议纪要,均是审计应关注的内容。
一是国家重大政策分析。主要梳理政府的持续关注点和最新关注点: 政策问题和目标、政策方案和资源、政策评价标准、政策环境和效果。
二是地方政策细则分析。可从地方官方机构文本层面,梳理上传下达情况: 对国务院和地方政策文本进行对比、对不同地方政策文本进行对比、对特定地方政策文本的历年演进进行梳理、对不同地方政策文本的历年演进进行梳理。
三是项目会议纪要分析。可从地方项目的会议文本层面,梳理上传下达情况:对地方政策和项目会议纪要文本进行对比、对不同项目会议纪要进行对比、对特定项目会议纪要文本的历年演进进行梳理、对不同项目会议纪要文本的历年演进进行梳理。
四是地方日报报道分析。可从地方日报文本层面,梳理上传下达情况:对地方政策和地方日报文本进行对比、对不同地方日报文本进行对比、对特定地方日报文本的历年演进进行梳理、对不同地方日报文本的历年演进进行梳理。
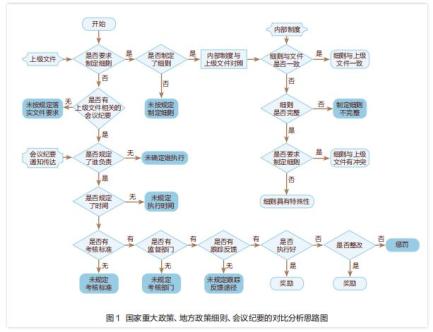
以项目会议纪要的分析为例(如图 1 所示),在上级出台和下发文件后,审计人员需考察以下内容:一是被审计单位是否被要求制定细则,如果已作要求,则考察被审计单位是否制定了细则,如果已制定,则需将内部制度与上级文件对照,考察下级制定的细则是否与上级文件相一致。如果不一致,则需进一步考察细则是否完整,如果完整,还要考察是否要求制定细则,如果是,则要考察细则与文件是否冲突,如果为否,则考察细则是否具备特殊性。二是被审计单位如果没有被要求制定细则,则需要考察上级文件执行的会议纪要,这是下级按规定落实文件要求的一个重要考量指标。被审计单位如有与上级文件相关的会议纪要,则需进一步考察在会议纪要传达时,是否规定了由谁负责,是否规定了具体时间,是否有系统的考核标准。如有,是否有监督部门,是否有跟踪反馈,是否做得好,做得好是否有奖励,做得不好是否要整改,是否有惩罚机制。
文本分析方法
作为考察下级是否落实上级政策的辅助方法,梳理国家重大政策的关注点、研读地方政策细则、对比项目会议纪要、分析当地日报报道,都需要一套系统的基于大数据的自然语言处理和语义分析方法。
(一)文本数据获取与预处理
首先,从互联网获取相关文本数据并构建数据库。具体为使用Python爬虫抓取有关国家政策的文本、地方政策的文本、地方项目的会议文本、地方日报文本等,以及领域内专业报纸、论文、专著等文献信息。数据经清洗后用MongoDB等工具构建两类数据库,一是参照语料库,即上级重大政策文本数据库,以便梳理重大政策的历时推进情况;二是目标语料库,即审计对象的相关文本语料库,后期可做上下级文件共时对比,同部门文件历时比较,不同部门文件共时对比等。同时,需考量领域专业词汇,并分语义域对词汇分类分级,以便提取和统计相关词。
其次,对数据清洗并加工处理。具体为使用大数据技术对数据在词汇和句法层面进行加工处理。一是词频分类统计,即在批量分词的基础上,进行词频自动化统计,语义标记和分类。统计热词、关键词、高频词等(如图 2所示),重点结合专业领域词库,分类分级梳理与政策相关的若干语义域中的具体词汇。二是知识图谱构建,即对文档中表示实体、关系、属性的关键信息及主谓宾句法特征进行提取,并实现可视化。

(二)文本数据建模
首先,提取主题特征。具体为基于算法提取关键词或短语,分析文本的主题特征。一是特定时间点的共时凸显特征,提示当下的主题特征;二是一段时间内的历时趋势特征,提示主题的演化趋势。
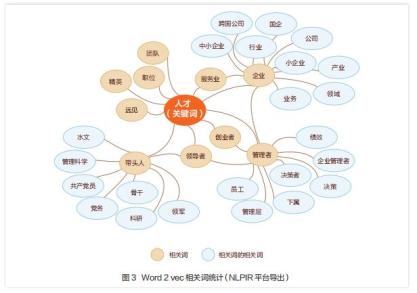
其次,分析词汇网络。具体为考察目标语料库中与政策相关的词汇共现和词汇关系情况。一是上义词及其下义词、相关词(如图3所示)的词汇共现情况(如同义、反义、互补、上下义、组合等形式);二是词汇形成的语义网络(如人物、动机、施事、受事、方式、属性、因果等语义关系)。
(三)文本语义分析
首先,分析词汇丰富度。具体为考察目标文本的关键词及其相关词的词汇丰富度情况。一是显性相关词的丰富度。以“创新”为例,需考察“研发”“科创”“新型”“换代”等字面义相关的词汇;二是隐性相关词的丰富度。仍以“创新”为例,需考察“育苗造林”“孵化小鸡”“老树发新芽”等暗含义相关的词汇。此外,“独角兽”“瞪羚”等新词也是考察的要点。显性相关词,尤其是隐性相关词和相关新词的出现频率对创新这类词汇的丰富度考察有更实际的意义。
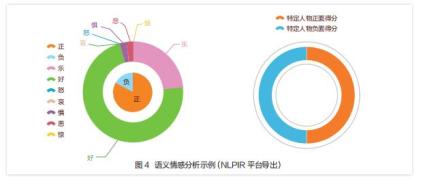
其次,分析语篇衔接性。具体为考察目标文本与其库中系列文本的衔接情况。一是文本内部和文本之间的显性衔接情况(语义一致或相关),仍以“创新”为例,“技术创新”“科技创新”“改革创新”“创新链”“资源链”“孵化器”“新型研发机构”之间在语义上明显具有一致性;二是文本内部和文本之间的隐性衔接情况(语义内涵相关),“孵化科技”“独角兽企业”“创新型老母鸡”“老树发新芽”在创新方面语义内涵相关,“雁阵”“齐飞”和“便车”“顺风车”在合作方面语义内涵相关。此外,针对全文或指定对象的情感分析(如图4所示)也是考量的一个维度,可以揭示文本暗含的舆情风险并预测信息。
文本关系研判
针对与政策相关的非结构化文本数据,可在文本向量化表征的基础上分析计算文本之间的邻近性,揭示不同政策文本之间的相似性情况。基于上述原理,可对照地方政策细则、项目会议纪要与国家重大政策文本、地方日报报道之间的关联指数,辅助考察下级对上级政策的传达落实情况,及其对政策的重视程度,从而考察下级在政策传达落实方面的守正及创新情况。
(一)守正点分析
以上下级政策文本对比为例,守正情况可分为三个级别,并相应适当赋值。
第一级:与上级文本相比,下级文本出现了少量相同表述,仅为重复,或出现相关表述,可赋值50 分。如针对“创新”这个主题,下级文本出现了“创新”“源头创新”“融合创新”等词。
第二级:与上级文本相比,下级文本出现了相同或相关表述,但词汇的丰富度有限,可赋值60 分。如针对“创新”这个主题,下级文本出现了“新型研发”“科创企业”“孵化科技”等词。
第三级:与上级文本相比,下级文本出现了相同或相关表述,且词汇的丰富度较好,可赋值70分。如针对“创新”这个主题,下级文本出现了“新型研发”“孵化科技”“独角兽企业”“瞪羚企业”等词。
(二)创新点分析
以上下级政策文本对比为例,创新情况可分为三个级别(守正第三级和创新第一级有部分重叠),并相应适当赋值。
第一级:与上级文本相比,下级文本不仅出现了相同表述,而且出现了相关的具体表述,可赋值70分。如针对“创新”,下级文本出现了“新型研发”“孵化科技”“创新型老母鸡”等词。
第二级:与上级文本相比,下级文本出现了新型表述,表面上不相关,实际上相关,可赋值80分。如针对“创新”,下级文本出现了“独角兽企业”“瞪羚企业”“移栽大树”等隐喻性表述。
第三级:与上级文本相比,下级文本出现了新型表述,且词汇丰富,文本内和文本间实现衔接,呈现一定的 体系化,可赋值90分。如针对“创新”,下级文本出现了“先手棋”“瞪羚企业”“创新型老母鸡”“老树发新芽”等隐喻性表述,且“先手棋”和“瞪羚企业”等词汇之间存在有关开创的隐性衔接,“创新型老母鸡”和“老树发新芽”等词汇之间存在有关新气象的隐性衔接。这些词汇具有一定的丰富度和系统性,在语义间相互关联,形成一个有关“创新”的语义网络。
(三)风险点分析
以上下级政策文本对比为例,有两种情况提示风险可能。
一种是与上级文本相比,下级文本未出现相同或相关表述,说明下级可能未传达上级的政策;另一种是与上级文本相比,下级文本仅出现大部分重复表述,说明下级可能未真实有效地传达上级的政策。
(四)历时趋势分析
以某机构会议纪要细则的历时对比为例,主要有四种情况:第一种为有关某政策主题,会议纪要细则之前无相关表述,现在有相关表述,提示之前该地区或机构之前没有重视有关政策,或认为不需重视;第二种为有关某政策主题,会议纪要细则之前无相关表述,现在也无相关表述,提示目前该地区或机构在上传下达方面没有改进;第三种为有关某政策主题,会议纪要细则之前有相关表述,现在仍表述相同,提示目前该地区或机构在上传下达方面无新进展或平稳;第四种为有关某政策主题,之前无相关表述而现在有相关表述,或之前有相关表述而现在则更为创新,提示目前该地区或机构完成了上传下达,或在传达上级政策方面有一定的思考和行为。
(五)共时差异分析
同理,以同级地区日报报道对比为例,主要有三种情况:第一种为有关某政策主题,地区A的日报报道无相关表述,而地区B有相关表述,提示地区A可能没重视传达该政策,或认为不需传达该政策,或没有较好地传达;第二种为有关某政策主题,地区A的日报报道无相关表述,地区B也无相关表述,提示两地区在政策传达上无实质进展;第三种为有关某政策主题,地区A的日报报道有相关表述,地区B也有相关表述,对比两地区传达政策时表述的守正和创新情况,提示两地区传达政策的不同程度。
总之,对政策跟踪审计而言,非结构化文本数据的自然语言分析是一种尝试性的创新型方式方法,它能够与传统的结构化数据分析方法形成补充,相互印证,更好地发挥审计“查病”和“治已病、防未病”的职能作用,今后可在更广泛的审计领域探索应用。
本文受2019年度江苏省“六大人才”高峰高层次人才项目(SZCY-004)、2021年度江苏省社科基金重点项目(21YYA001)和 2020 年度国家语委“十三五”科研规划一般项目(YB135-150)资助。
作者张薇单位系南京审计大学外国语学院;伍之昂单位系江苏省审计信息工程重点实验室
原标题:《审计观察 | 非结构化文本数据的自然语言分析在政策跟踪审计中的应用》

