1.交叉验证都干了什么
我们先来了解下交叉验证都干了什么,举一个StatQuest讲的例子:


这时候,我们就可以使用交叉验证来判断选择哪个模型可能最优。
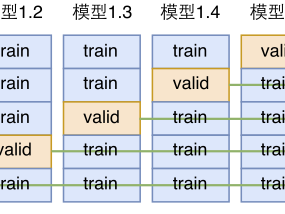
这里,我们以四折交叉验证为例,使用四折交叉验证法(four-fold cross validation)将样本随机分成4份,其中任意3份均用作训练样本,剩余1份用作测试样本。依次记录每一种方法在每一次测试样本中的表现(正确分类的样本数、错误分类的样本数)。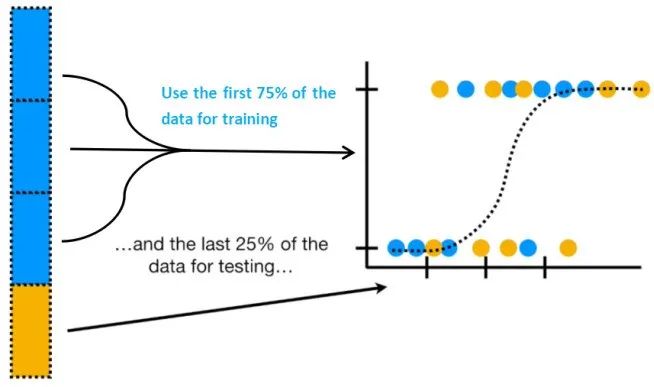
我们首先来使用逻辑回归演示一遍四折交叉验证的过程。
1.第一次:使用前3份作为训练集训练模型,第4份作为测试集测试模型,记录模型在测试集中的表现情况。正确5个人,错误1个。
 2.第二次:使用第1,2,4份作为训练集训练模型,第3份作为测试数据集测试模型,记录模型在测试数据集中的表现情况。正确4个,错误2个。
2.第二次:使用第1,2,4份作为训练集训练模型,第3份作为测试数据集测试模型,记录模型在测试数据集中的表现情况。正确4个,错误2个。
3.第三次:使用第1,3,4份作为训练集训练模型,第2份作为测试数据集测试模型,记录模型在测试数据集中的表现情况。正确1个,错误5个。
 4.第四次:使用第2,3,4份作为训练集训练模型,第1份作为测试数据集测试模型,记录模型在测试数据集中的表现情况。正确6个,错误0个。
4.第四次:使用第2,3,4份作为训练集训练模型,第1份作为测试数据集测试模型,记录模型在测试数据集中的表现情况。正确6个,错误0个。
好,总结下,逻辑回归在这个数据集中,一共正确分类16个,错误分类8个。同样对其它几种机器学习模型进行四折交叉验证,结果如下图:

支持向量机(SVM)在测试样本中的正确分类个数为18,错误分类个数为6,其表现性能优于其他两种方法(logistic 回归)和KNN(K-最近邻法)。故我们可以考虑选择SVM。
2.交叉验证的原理
交叉验证大致分为三种:简单交叉验证(hold-outcross validation)、k-折交叉验证(k-fold cross validation)和留一交叉验证(leave one out cross validation)。交叉验证(Cross validation),有时亦称循环估计,是一种统计学上将数据样本切割成较小子集的实用方法。可以先在一个子集上做建模分析,而其它子集则用来做后续对此分析的效果评价及验证。一开始的子集被称为训练集(Train set)。而其它的子集则被称为验证集(Validation set)或测试集(Test set)。交叉验证是一种评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力(Generalize).假设利用原始数据可以建立 n 个统计模型,这 n 个模型的集合是M={M1,M2,…,Mn},比如我们想做回归,那么简单线性回归、logistic回归、随机森林、神经网络等模型都包含在M中。目标任务就是要从M中选择最好的模型(这一点相信在前面的例子中大家已经知道了)。(1).简单交叉验证假设训练集使用T来表示。如果想使用预测误差最小来度量模型的好坏,那么可以这样来选择模型:
1).使用T来训练每一个M,训练出参数(模型的系数)后,也就可以得到模型方程Fi。
2).然后选择预测误差E最小的模型。
这种方法可行吗?显然不可行,大家可以回忆下在线性回归系列分享的多项式回归,如果单纯的从训练集看模型性能的话,多项式回归是要优于多元线性回归的,甚至可以拟合到每个数据点,但是容易过拟合,泛化能力差。
因此,我们做了一些改进,对于这个改进,大家应该都耳熟能详:
1).从全部的训练数据T中随机选择70%的样本作为训练集T-train,剩余的30%作为测试集T-validation。2).在T-train上训练每一个M,得到模型Fi. 3).在T-validation上测试每一个Fi,得到相应的预测误差E。4).选择具有最小预测误差的作为最佳模型。这种方法称为hold-outcross validation或者称为简单交叉验证。由于测试集和训练集中是两个世界的,因此可以认为这里的预测误差接近于真实误差(generalization error)。这里测试集的比例一般占全部数据的1/4-1/3。30%是常用值。还可以对模型作改进,当选出最佳的模型M后,再在全部数据T上做一次训练,显然训练数据越多,模型参数越准确。但是,简单交叉验证方法的弱点在于得到的最佳模型是在70%的训练数据上选出来的,不代表在全部训练数据上是最佳的。还有当训练数据本来就很少时,再分出测试集后,训练数据就太少了。其实严格意义来说hold-out-validation并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性。
(2).K-折交叉验证所以,根据hold-out-validation的缺点,我们做下改进:1).将全部训练集T分成k个不相交的子集,假设T中的训练样例个数为m,那么每一个子集有m/k个训练样例,相应的子集称作{T1,T2,…, Tk}。2).每次从模型集合M中拿出来一个Mi,然后在训练子集中选择出k-1个{T1,T2,Tj-1,Tj+1…,Tk}(也就是每次只留下一个Tj),使用这k-1个子集训练Mi后,得到假设函数Fij。最后使用剩下的一份Tj作测试,得到预测误差Eij。3).由于我们每次留下一个Tj(j从1到k),因此会得到k个预测误差,那么对于一个Mi,它的预测误差是这k个预测误差的平均值。4).选出平均经验误差E最小的Mi,然后使用全部的T再做一次训练,得到最后的模型Fi。此方法称为k-fold cross validation(k-折交叉验证)。说白了,这个方法就是将简单交叉验证的测试集改为1/k,每个模型训练k次,测试k次,预测误差为k次的平均。k一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。一般k取值为10,因为经验证明此时模型的偏差和方差达到最优。这样数据稀疏时基本上也能进行。显然,缺点就是训练和测试次数过多。(3).留一交叉验证极端情况下k-折叠交叉验证中k可以取值为m,意味着每次留一个样例做测试,这个称为leave-one-outcross validation(LOOCV)。如果设原始数据有N个样本,那么LOOCV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。相比于前面的K-CV,LOO-CV有两个明显的优点:1).每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。2).实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。使用较差验证注意事项:
1.训练集中样本数量要足够多,一般至少大于总样本数的50%。
2.训练集和测试集必须从完整的数据集中均匀取样。均匀取样的目的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量足够多时,通过随机取样,便可以实现均匀取样的效果。
3.交叉验证的R实现
library(ISLR)data(Auto)head(Auto)
我们先做两个模型测试下:
set.seed(1234)train=sample(n,n/2) ## 选择50%的样本作为训练集test=(-train) ## 50%的样本作为测试集lm.fit=lm(mpg~horsepower, data=Auto, subset=train) ## 使用训练集拟合线性回归模型## 以horsepower来拟合mpg的值mean((Auto[test,mpg]-predict(lm.fit, newdata=Auto[test,]))^2) ## 均方误差



1.这个循环的意思是将原始数据随机分10次,每次都分为了不一样的训练集还有测试集。
2.接着建立10个多项式模型,当然degree=1的时候,属于简单线性回归。
3.使用MSE评价每一种模型在训练集的表现。
## 将结果可视化plot(MSE[1,], ylim=range(MSE), type=l, lwd=2, col=rainbow(10)[1], xlab=degree, ylab=the estimated test MSE)for(seed in 2:10){ points(MSE[seed,], type=l, lwd=2, col=ggsci::pal_npg()(10)[seed])}
可以看到,当degree=9的时候,模型的MSE达到最优,但是考虑到9阶多项式过高了,所以我们可以选择2阶多项式模型。
(2).K-折交叉验证library(boot)cv.error.10=rep(NA,10)for(degree in 1:10){ glm.fit=glm(mpg ~ poly(horsepower,degree), data=Auto) set.seed(1234) cv.error.10[degree] <- cv.glm(Auto,glm.fit,K=10)$delta[1]}cv.error.10
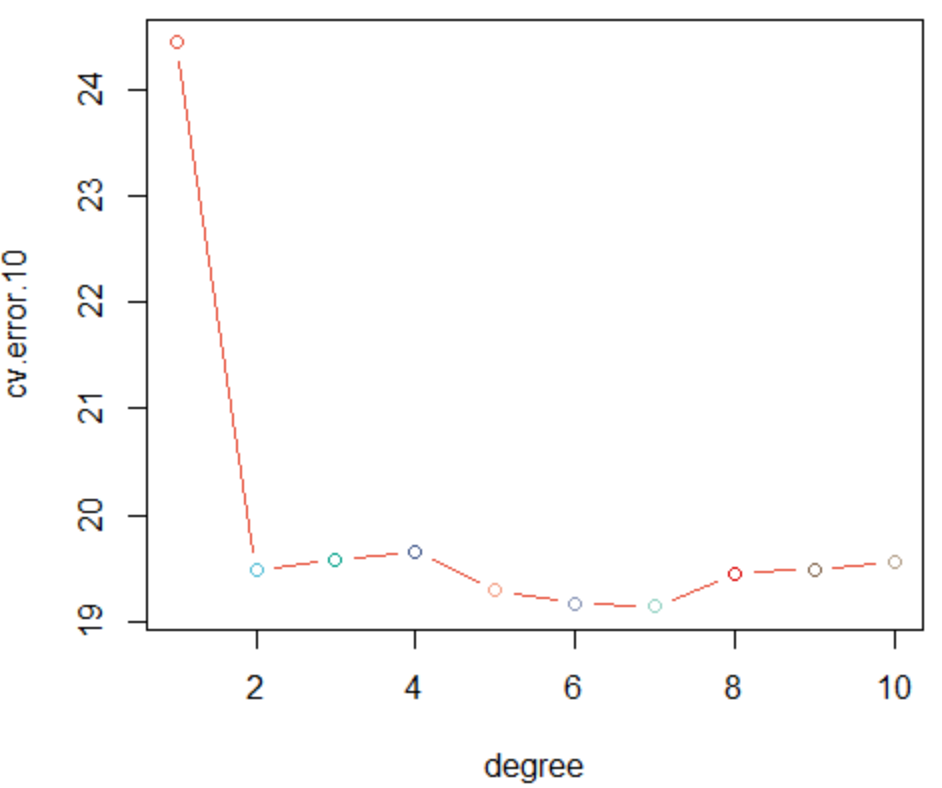
与简单交叉验证不一样的是,7阶多项式的表现最佳。
(3).留一交叉验证loocv.error=rep(NA,10)for(degree in 1:10){ glm.fit=glm(mpg ~ poly(horsepower,degree), data=Auto) loocv.error[degree]=cv.glm(Auto,glm.fit,K = nrow(Auto))$delta[1]}loocv.error fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
可以观察到,跟10折交叉验证的结果差不多。
LOOCV中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。而且实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但是,代码运行的时候它最大的缺点就暴露出来了:耗时久。我之后计时比较了一下,十折交叉耗时0.33秒,LOOCV耗时14.94秒。计算成本增加了太多了。
加编者微信入群 "生信交流群-医学僧"
加微信时请备注 "学校-专业-姓名"
参考:
1.StatQuset--Youtube
2.交叉验证,模型选择(cross validation)-- 计量经济圈