
今天在看论文的过程中,发现自己对一些机器学习的基础知识把握的不清晰,遂查找资料回顾一番,方便之后查看。
本文将从数据集划分过渡到交叉验证,最后引申至模型的Stacking。
交叉验证
在机器学习训练过程中,标准的做法是将数据集划分为三个子集:训练集、验证集和测试集。顾名思义,训练集用于模型的训练,验证集用于模型调优和参数选择,测试集测试模型泛化能力。需要注意的是,在模型训练过程中,测试集是完全独立出去的,否则会出现数据泄漏的问题。
对于数据集的划分,有一个非常通俗易懂的例子。我们将模型训练的过程看作是一个学生学习的过程,训练集则是学生学习课本知识,验证集可以看作学生自己做一套试卷检测学习效果,而测试集可以看作是做后的期末考试。学生通过验证集的反馈不断调整学习计划,优化训练过程,找到最优的学习参数,最用在测试集上进行预测。
然而我发现,很多情况下一些机器学习过程都未划分验证集,这是我比较困惑的一点,这样做的原因一般是因为数据集较小,划分出验证集后整个训练过程所能接触到的数据将会更少,不利于模型训练。
交叉验证方法便是解决这一问题的潜在方法之一。这里我只介绍最常用的k-folds交叉验证。k-folds交叉验证的过程很好理解,这里有一张经典的图解[1]可以帮助很好理解。
在此之前我们需要明确一些基本概念,参数与超参数,模型与学习器。
超参数:模型训练过程需要人为预先设定的参数,这些参数不能从模型训练过程中获得。比如CNN的卷积层的filter数,kernel大小等等。一般所谓的调参也就是针对这些参数而言的,传统的调参方法有GridSearch,RandomSearch等。
参数:参数就是我们在模型训练过程中需要学习的内容。比如,CNN中每个卷积核的具体参数,全连接层的每个权重。而全连接层包含多少个节点则属于超参数。
模型:当我们在模型空间中选择一个具体的模型,比如XGBoost,并给定具体的超参数,这是我们就确定了一个模型。
学习器:这里的学习器和模型是相对而言的,当我们给定具体模型和超参数后,针对不同的数据集,学习到不同的参数,我们将学习到具体参数的模型称为学习器。这应该算是一个相对的概念,这种说法会帮助我们理解交叉验证的过程。
下图所示,以k=5来举例,首先将数据集分为训练集和测试集两部分,交叉验证过程仅作用于训练集。每次将训练集划分成五个部分,其中四分用于模型训练,另外一部分用于模型验证。每次选择不同的部分作为验证集,这样重复五次,将整个训练集遍历,实现交叉验证。
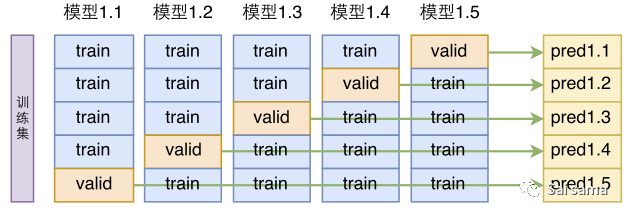 交叉验证图解,图片来自知乎
交叉验证图解,图片来自知乎了解交叉验证过程后,有两个重要的问题需要理解。
交叉验证的作用是什么?我们使用交叉验证,就是为了在有限的数据上尽可能的得到最优的模型。一般情况下,对一个具体的问题,我们往往会使用多种模型,比如XGBoost,RF,Adaboost等,或者使用同一个模型的不同超参数,比如XGBoost的min_child_weight。当我们对这一组模型进行交叉验证时,通过比较交叉验证的结果,可以从中选出较优的模型。也就是说,交叉验证实际上是为了选择较优模型。
怎么从交叉验证结果确定最终模型?在理解第一个问题后,我们需要确定最终的模型。参加上图,采用5折交叉验证会产生5个学习器(子模型,对应于同一个超参数模型),这五个学习器学到的具体参数是不同的,我们怎么挑选呢?事实上,由于这五个学习器都是由部分数据学习得来的,都是片面的学习结果,所以在我们第一步确定好具体模型后,我们需要再将这个模型在整个训练集上进行训练,此时得到的模型才是我们所要的结果。
Stacking Model
Stacking是集成学习(Ensemble Model)的一种,常见的集成学习还有Boosting,代表模型有Adaboost,XGBoost;Bagging,代表模型由RandomForest;还有一些较为简单的权重分配,取平均值方法。
Stacking是一种多层模型结构,这里以两层结构为例简单介绍。Stacking的策略在于集合多种模型的优点,要求其每个子模型具有较好的预测能力,并且每个子模型的底层算法不同,比如一般会搭配使用线性模型(Lasso)、Bagging模型(RF),Boosting模型(XGBoost),基于距离计算的模型(MLP,SVM)等等。Stacking的第一层会使用多种模型,第二层一般使用的较少,常用的有LR。Stacking具体的过程将会下下面介绍。
第一眼看到Stacking,会发现和交叉验证过程很像,实际上是两个完全不同的东西。这里引用一张Stacking框架图[2],便于理解。前文提到Stacking是一种多层结构,这里显示的是其第一层结构。
第一层包含多个模型,对于每一个模型,我们在训练集上使用5折交叉验证,可以看到图中5个test的预测结果组成一个与训练集大小一致的数据集(A),在交叉验证的过程中,每一个学习器都需要对整个测试集进行预测,最终预测的结果是5个学习器预测结果的平均值(B)。第一层中的每个模型都经历同样的操作,以三个模型为例,这样会得到(A1,A2,A3),(B1,B2,B3)。
对于第二层的模型而言,(A1,A2,A3)将作为其训练集,(B1,B2,B3)为测试集,最终训练出来的结果作为Stacking的结果。
 Stacking图解
Stacking图解写了这么多,实际上是为了看懂下面一幅图[3]。当我第一看看到这幅图时,以为是一个Stacking结构,于是补了一些基础知识,待补完之后,发现它根本不是!!
 GAM framework
GAM framework这个图看起来十分复杂,同样是一个两层结构,具体的两层结构看下图。 在原文中第一层使用了RF进行数据插补,第二层用了4个模型,XGBoost,LMM,RF和一个三维模式。可以看到第二层模型的结果作为第三层模型的输入,最终第三层预测结果作为最终结果,从这里看起来和上文的Stacking一摸一样,然后在看到其具体的交叉验证过程后发现事情不是那么简单。
在原文中第一层使用了RF进行数据插补,第二层用了4个模型,XGBoost,LMM,RF和一个三维模式。可以看到第二层模型的结果作为第三层模型的输入,最终第三层预测结果作为最终结果,从这里看起来和上文的Stacking一摸一样,然后在看到其具体的交叉验证过程后发现事情不是那么简单。
文中将整个数据集分为三个部分,训练集80%,验证集10%,测试集10%。这里和平常的分发不一样,因为验证集的10%是留给第三层模型的,可以看到整个过程迭代了10次,也就是这个验证集在每次迭代过程中都会变换,直到遍历整个数据集。
用一句话来概括整个训练过程,就是对第三层模型进行了10则交叉验证,但由于第三层模型建立在第二层模型之上,需要第二层模型结果作为输入,所以在交叉验证的每一次划分中,对第二层模型也进行交叉验证,只不过这次的k=9,因为需要留有10%的数据作为第三层模型的验证集。所以总结起来就是,一个嵌套的交叉验证过程😂。
Reference
[1]交叉验证: https://zhuanlan.zhihu.com/p/67986077
[2]Stacking: https://ieeexplore.ieee.org/document/8930485
[3]Estimating daily PM2.5 and PM10 over Italy using an ensemble model: https://pubs.acs.org/doi/suppl/10.1021/acs.est.9b04279/suppl_file/es9b04279_si_001.pdf

