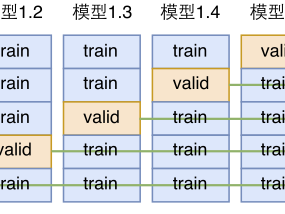
交叉验证是验证机器学习算法的效果时最常用的一种方法。将已有的数据分成十份,随机取其中八份用来作为训练模型的数据,用其他两份做验证,以防止模型过拟合,然后重复上面的过程,直到每一份数据都已被用来做验证。
这篇小文想说说交叉验证背后的思想能怎样指导我们过好日常的生活。在此之前,想先谈谈交叉验证背后的假设。首先是我们对世界的认识是不完全的,我们无论收集到了多少数据,都只是当前的部分数据。正因为数据不完全,将其中一部分人为的拿掉(作为验证集),不会造成明显的训练效果的降低。其次是数据中的规律不是完全连续的,当前的规律不会一成不变的应用到未来,否则就不需要去验证了。
交叉验证更重要的假设是,对模型为之的信息进行预测是有价值的。人们不关心机器学习的模型在训练集上的表现,而只关心其在模型未知的测试集上的表现。这里就引出了这篇小文的核心观点,交叉验证告诉我们,判断一个模型,一种解释,一个理论的价值,需要看这个理论如何影响未来;而判断支持某个观点的人时,需要判断的是其是否愿意为其观点所做出的预测承担风险。
这对应的是Taleb提出 “have a skin in the game",在信息泛滥的年代,在各种理论层出不穷的时代,判断一种理论是否靠谱的方法就是看其支持者是否愿意为此买单。如果一种制度,一种市场的安排能够让人们不止是为了接受信息付费,还能为了传播观点承担风险,那么这就能解决信息过载时代的普遍焦虑,从而以搭建平台的方式来改变未来的社会。
具体的举个例子,如果你写了一篇,或者转发了一篇支持希拉里当下一任美国总统的文章,然后在发表时后台系统的自然语言处理系统识别出了你文章中的观点,要求你付一笔钱,到时候如果希拉里赢得了大选,你会按照出价时的赔率获得相应的赔偿,若是你猜错了,你会损失这笔钱。或者你在这样的预测市场上下了注,你写了篇文章解释你为什么要下注。这里的要点是要想发出声音,你需要花钱,愿意将越多的钱用来做风险投资,你的声音就越大。
如果你的读者不把你的作品当回事,不愿意为了文字花钱,那么写作者会因此不花精力去打磨自己的文字,或者在文字中加入极端化的观点来吸引更多的读者。付费阅读试图解决这种逆向选择。而内容创业遇到的问题,即公众号订阅者动辄上万,阅读量却难以破千,则可以通过让写作和转发不在免费来解决。如果我转发一篇对机器学习在自然语言处理上应用的文章,并标注我因为这个转发购买了1块钱的某家从事自然语言处理的startup的股票,那么会让每个人在转发前多想一想,从而避免刷屏式的分享,而从整体上来看,当所有的人都这样做了以后,股票的投资也会更倾向于理性,如果你在购买股票时必须转发一篇文章解释给你的朋友你为什么购买,那么你的投资时也许会更多的考虑长远,考虑股票的价值本身,而不是投机性的买涨杀跌。
交叉验证首先是承认我们所知有限,我们所发现的规律在未来不一定有效。而无论是阴谋论,还是那些单方面的解释某个现象的理论,则不会承认自己的理论具有局限,不会承认认知到的规律可能不适用于未来。面对这样的声音,最好的判定方法是看发出声音的人是否按照其所传播的观点进行了相应的投资,无论是时间还是金钱,或者只是说说而已。发出声音的人比接受信息的人有更多的”内幕消息“,如果我们不想让我们的朋友圈充斥着信息经济学中所说的”酸柠檬“,那么我们需要构建一种制度,要求信息的发布者必须have a skin in the game。为此,我们需要一个《Superforecast》这本书中所描写的预测市场,在其中人们可以做出预测,同时还要规定人们在发表和传播言论时需在相应的预测下下注,以便让看到你的信息的人能够知道你到底对这个观点的支持程度。