
摘要:协同过滤算法(Collaborative Filtering Algorithm,CFA)是一种通过分析用户之间的相似性或者物品之间的相似性,来推荐用户可能感兴趣的物品的技术。简单来说,就是“物以类聚,人以群分”,根据和你相似的人喜欢什么,来推荐你也可能会喜欢的东西。
本文介绍了如何利用Python和AI技术实现电商商品推荐系统的全过程。文章首先讲解了推荐系统的基本原理,重点介绍了协同过滤算法,并通过实际的用户商品评分表单,演示了如何用Python读取数据、计算用户相似度、预测兴趣分数以及为用户智能推荐商品。通过完整的代码实例,读者可以快速掌握推荐系统的实现流程和核心技术。该方法不仅适用于电商平台,还可扩展到各类需要个性化推荐的场景,为实际业务提供智能化支持。
本文主要介绍了怎么利用Python+AI人工智能技术实现电商商品推荐系统的过程,详细内容请参考下文。

一、检验AI大模型环境
1.访问Linux系统

2.检验Python和PyTorch开发环境

二、电商商品推荐系统
1. 什么是电商商品推荐系统
(1) 推荐系统的定义
电商商品推荐系统是一种基于用户历史行为、兴趣偏好和商品特征,为用户智能推荐商品的系统。它的目标是帮助用户快速发现感兴趣的商品,同时提升平台的转化率和用户粘性。
(2) 推荐系统的分类
说明:常见的推荐系统类型有“基于内容的推荐”、“协同过滤推荐”和“混合推荐”三种,本文将以协同过滤为例,介绍如何用Python实现一个简单且实用的电商商品推荐系统。
基于内容的推荐:根据商品本身的属性(如类别、品牌、关键词等)为用户推荐相似商品。 协同过滤推荐:根据用户的历史行为(如浏览、购买、评分等)和其他用户的行为进行推荐。分为基于用户的协同过滤和基于物品的协同过滤。 混合推荐:结合多种推荐方法,提升推荐效果。2. 推荐系统的工作原理
说明:推荐系统的工作原理就是通过分析你的兴趣和行为,找到与你喜好相似的其他人或你过去喜欢的东西,然后推荐你可能感兴趣的新内容。
通过表格直观的列出推荐系统的工作流程如下:

3. 协同过滤算法的核心知识
说明:协同过滤算法(Collaborative Filtering Algorithm,CFA)就是根据和你喜好相似的用户的选择,来给你推荐你可能喜欢的东西。
协同过滤是目前最常用的推荐算法之一,其核心思想是:
用户-用户协同过滤:如果用户A和用户B在历史上喜欢过相同的商品,那么A喜欢的其他商品也可能会被推荐给B。 物品-物品协同过滤:如果商品A和商品B经常被同一批用户喜欢,那么喜欢A的用户也可能喜欢B。三、利用Python实现协同过滤推荐系统
说明:下面将通过编写一个简单的商品推荐程序,一步步的实现一个基于用户协同过滤的电商商品推荐系统。
1. 准备用户商品评分数据
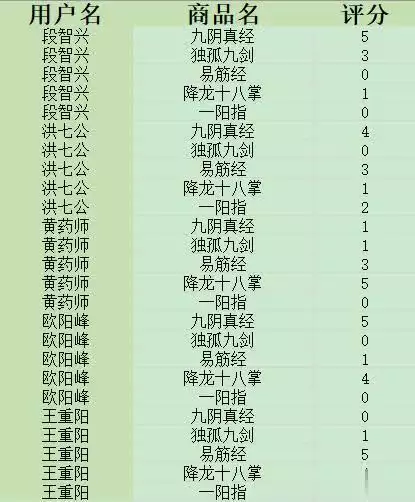
说明:在实际电商平台中,用户的行为数据(如浏览、购买、评分等)都会被系统记录下来。这里为了便于演示,我们将这些数据整理成一个Excel表单,表单包含用户名、商品名、评分三列。评分可以是用户对商品的打分,也可以用购买次数、浏览次数等行为数据代替。
用户评分表单如下:
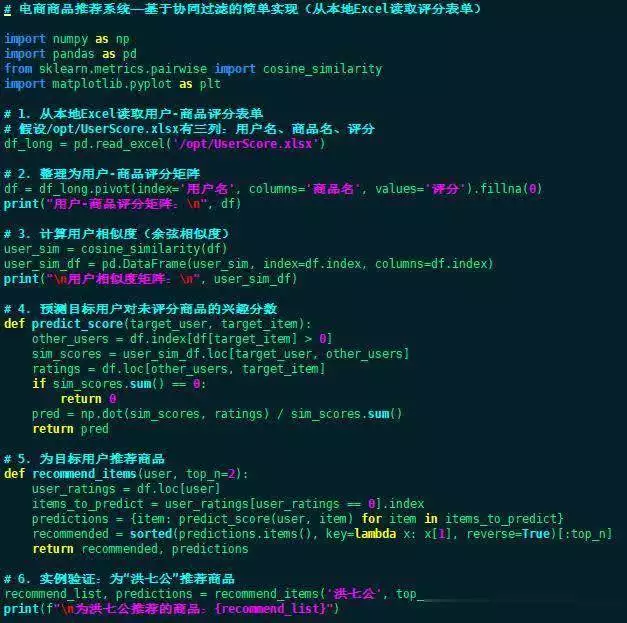
2. 导入必要的库
import numpy asnp
importpandasaspd
fromsklearn.metrics.pairwiseimport cosine_similarity
importmatplotlib.pyplotasplt
3. 读取并整理评分数据
# 从本地Excel读取用户-商品评分表单
df_long= pd.read_excel(/opt/UserScore.xlsx)
# 整理为用户-商品评分矩阵
df=df_long.pivot(index=用户名, columns=商品名, values=评分).fillna(0)
<pdata-track="17"> print ( "用户-商品评分矩阵: \n " , df )
4. 计算用户相似度
# 计算用户之间的余弦相似度
user_sim= cosine_similarity(df)
user_sim_df= pd.DataFrame(user_sim, index=df.index, columns=df.index)
<pdata-track="18"> print ( " \n 用户相似度矩阵: \n " , user_sim_df )
5. 预测用户对未评分商品的兴趣
说明:这里主要是通过相似用户的评分加权平均,预测目标用户对未评分商品的兴趣分数。
<pdata-track="19"> def predict_score ( target_user , target_item ):
other_users= df.index[df[target_item] 0]
sim_scores= user_sim_df.loc[target_user, other_users]
ratings= df.loc[other_users, target_item]
ifsim_scores.sum() ==0:
return0
pred= np.dot(sim_scores, ratings) /sim_scores.sum()
returnpred
6. 为用户推荐商品
说明:主要是通过用户对不同商品的评分,为每个用户推荐他们未评分且预测分数最高的商品。
<pdata-track="24"> def recommend_items ( user , top_n = 2 ):
user_ratings= df.loc[user]
items_to_predict=user_ratings[user_ratings==0].index
predictions= {item: predict_score(user, item) foriteminitems_to_predict}
<pdata-track="25"> recommended = sorted ( predictions .items (), key = lambda x : x [ 1 ], reverse = True )[: top_n ]
returnrecommended
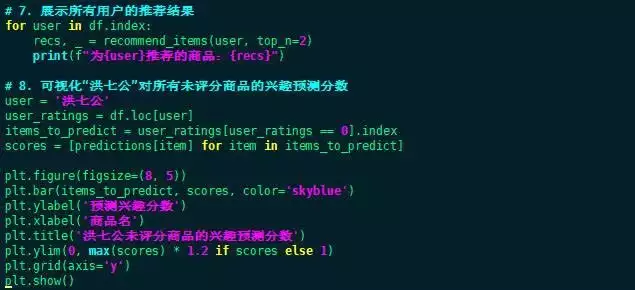
7. 验证与输出
# 为洪七公推荐商品
recommend_list= recommend_items(洪七公, top_n=2)
<pdata-track="27"> print ( f " \n 为 洪七公 推荐的商品: { recommend_list } " )
# 展示所有用户的推荐结果
foruserin df.index:
recs= recommend_items(user, top_n=2)
<pdata-track="28"> print ( f "为 { user } 推荐的商品: { recs } " )
8. 商品推荐系统的完整实例
(1)执行指令# vim CFA_recommand.py编写商品推荐程序
(2)执行指令# python3 CFA_recommand.py运行商品推荐程序
其可视化结果如下
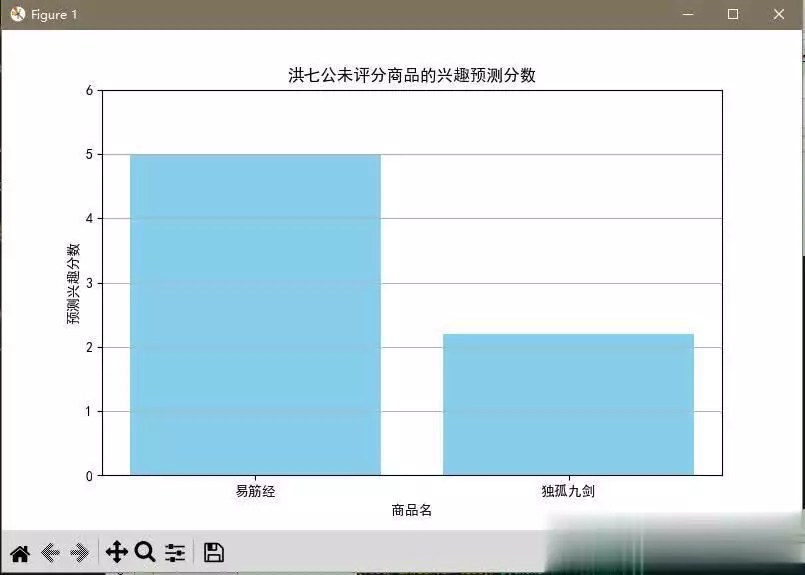
备注:以下是对程序运行结果进行逐项解说
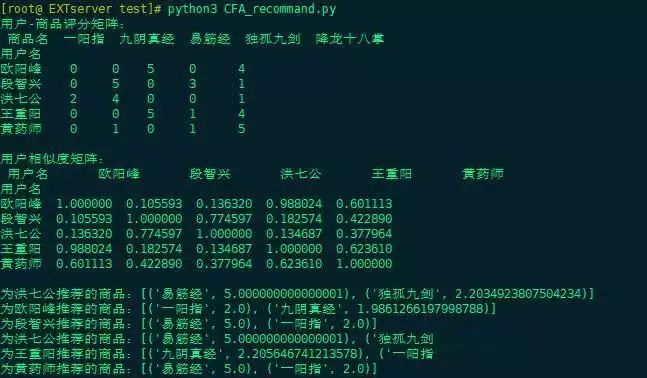
用户商品评分矩阵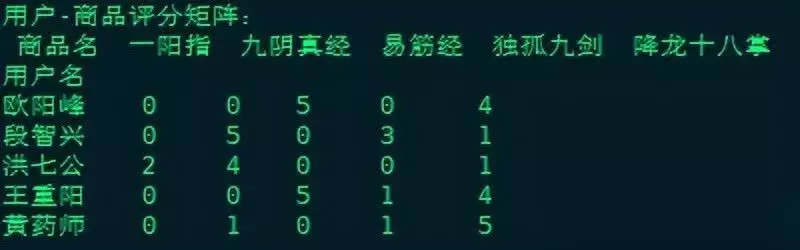
程序首先打印出一个用户商品评分矩阵,展示每个用户对每个商品的评分情况。评分为0表示该用户未对该商品评分或未购买。这个矩阵是后续推荐算法的基础。
用户相似度矩阵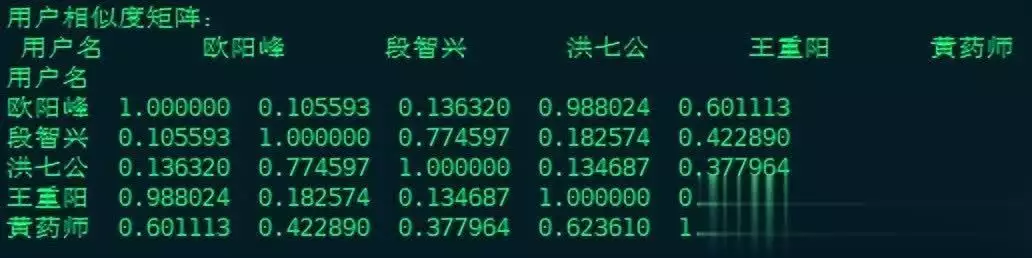
接着,程序会输出用户之间的相似度矩阵。每个值表示两个用户之间的兴趣相似程度,相似度越高,说明这两个用户的兴趣越接近。推荐系统会优先参考与目标用户兴趣相似的其他用户的行为。
推荐结果
程序会为各个用户推荐两个最可能感兴趣但未评分的商品,并输出推荐列表。
可视化结果最后,程序会生成一张柱状图,展示“洪七公”对所有未评分商品的兴趣预测分数。横轴是商品名,纵轴是预测兴趣分数。柱子越高,表示系统认为“洪七公”对该商品的兴趣越大,更值得推荐。

