

题记:2025年6月9-10日,“2025罗汉堂-北大国发院数字经济年会”在北京大学国家发展研究院召开。本文为蚂蚁集团资深副总裁、财富与保险事业群总裁黄浩在本次年会上的主题演讲。

以下是黄浩演讲的全文:
大家好,我是黄浩。这是我第三次来参加罗汉堂年会的活动。现在大家一说起 AI 都默认是大语言模型,而大语言模型和金融的结合,我觉得如果用一句话来说,就是“理想有多么的丰满,现实就有多么的骨感”。目前在金融领域,大语言模型的实际落地应用接近为零。大家可以回想一下,最近一次使用大语言模型的金融服务是在哪里,是用了什么?实际情况是很少很少的。基于这个接近为零的应用状况,我就简单地分享一下行业的现状,以此抛砖引玉。
01
金融科技发展的三个阶段
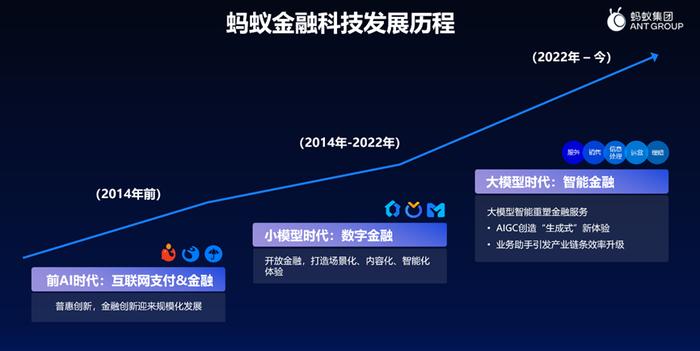
如果用几分钟简单地回顾金融科技的发展历程,我们发现其实中国的金融科技就是世界的金融科技。在过去 20 年里,金融科技的发展可以分为三个阶段。
第一个阶段是前 AI 时代,代表作是支付宝。支付宝开创了中国乃至全世界数字化支付的新时代。这是在 2014 年之前,几乎没有 AI。互联网支付大家都很熟悉了,我们使用得最多的技术,包括大数据、云计算、分布式架构,都是为了解决海量交易高并发的普惠性服务。这方面中国解决得最好,除了金融科技企业之外,银联、网联也都建立了高并发的系统,后来全世界都开始向中国学习。当时的技术解决的核心问题就是线上化、实时化和规模化,实现了绿色、便捷和普惠。
第二个时代是小模型时代,或者叫数字金融时代。一个代表作是余额宝(余额宝诞生于 2013 年,快速发展于 2014 年之后,可以说是介于第一个和第二个时代之间)。更有代表性的是数字化信贷,比如网商银行首创的 “310” 模式,即 “三分钟申请、一秒钟贷款、零人工干预”。我曾经担任过网商银行的行长。十多年前刚推出这个服务的时候,人们都在问:没有客户经理,没有网点,没有抵押的贷款能够有效的运转吗?十年之后走到今天,我们看到的数据是,中国的消费信贷实际上 60% 以上是纯数字化的,小微企业的信贷 —— 特别是 100-200 万以下的 —— 绝大部分是数字化的。也就是说,数字化信贷从蚂蚁出发,已经成为包括蚂蚁的合作伙伴、竞争对手,以及所有银行和金融机构都在使用的标配,就像互联网支付一样。它所代表的数字金融其实是真正的 AI 应用。可在 ChatGPT 和 DeepSeek 兴起之后,我们都不太好意思提这事了,好像小模型就不是 AI,但实际上这已经是 AI 技术,并且在金融领域得到了广泛应用。
第二个阶段另一个创新实践项目是 “大山雀”,这也是基于 AI 技术。我们利用卫星对农作物 —— 不管是粮食作物还是经济作物 —— 进行拍照,然后利用 AI 技术去识别农民种的是什么、种的怎么样,再基于算法来判断他们是否需要贷款、贷款是否安全。这也是网商银行首先推出的一项服务,目前有超过 120 万的种植户通过这项服务获得了贷款。实际上现在有很多金融机构也已经开始使用这种纯正的 AI 技术,但这还不是大语言模型。
这个时代的再一个创新例子是在保险领域的数字理赔。理赔以前是采用非常重人工的模式,可能一个机构对医疗险或重疾险的理赔需要 30 到 60 天或者更长的时间。而现在蚂蚁的绝大多数保险理赔是在 10 秒内完结的,用户只需要把所有的医院理赔材料勾选上传,不用做任何的分类,立刻就能出理赔结果。我们每年这样办理的案例超过 300 万起。这也是纯正的 AI 技术,但仍然不是大语言模型(最近我们开始部分地应用大语言模型技术)。
由此,在金融科技的第二个时代,我们基于海量的数据,通过算法的优化,深刻地结合场景,进行了各种金融业务的创新。我觉得毫不夸张地讲,经过第一个和第二个阶段的发展,中国已经引领了数字化支付和数字化信贷的全世界浪潮。在第一个和第二个时代,中国是领先全球的,甚至说遥遥领先也不为过。
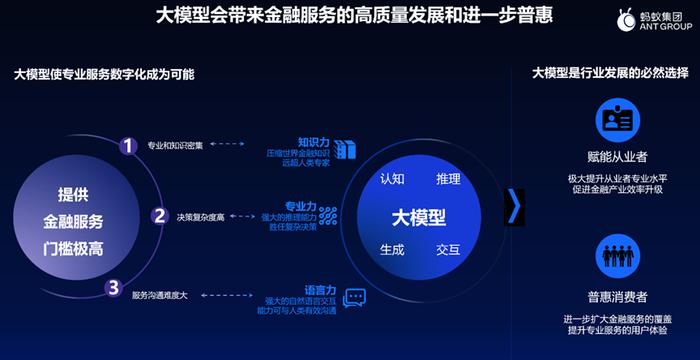
第三个时代就是大模型时代,也就是现在大家谈到更多的智能金融。这个时代才刚刚开始,谁也没有领先。大家在同一条起跑线上竞争,蚂蚁也一样 —— 蚂蚁很幸运,在这三个阶段都是其中主要的参与者之一。大语言模型必将会为金融领域的 AI 应用打开新空间,因为模型足够大、数据足够多,而语言又是人类区别于动物智能的最主要的特征。如果在这个点上取得突破的话,会给很多金融产品的制造和交付的过程都带来巨大的想象空间。这个想象空间在哪儿呢?我们认为在三件事上:知识力(解决专业知识密集的问题)、专业力(解决决策复杂度高的问题)和语言力(解决服务沟通难度大的问题 —— 通过多轮次的沟通,深入了解用户需求,并为其提供服务)。
这三种力发挥作用的领域,肯定不是在支付这类瞬间发生的、资金搬家的流程,也不是在基于 AI 评估能否贷款、贷多少款的流程,而是会触及金融业务最复杂的环节。如果金融业务有一部分是融资性业务,那么还有一部分是融智性业务,那就是资产管理、财富管理、保险等等。在大语言模型推出之前,这些业务在中国可能是通过数十万的银行网点、数百万的银行员工、数百万的保险代理人员来提供服务。服务的质量高吗?够吗?大家心里都有判断。你得到过像私人银行或者财富管理那样专业的、有品质的、贴身的服务吗?答案是都没有。正是网点数量和员工数量的限制,使得十亿人无法得到既有高水准又有温度的金融服务。所以这次突然给了所有人想象空间。
02
大模型时代的现实及
蚂蚁的应对
就我了解,圈内几乎没有人质疑大模型会带来金融服务的高质量发展以及进一步普惠。如果今天有人对此表示怀疑 —— 就像二十年前怀疑数字支付会普及、十年前怀疑数字信贷会普及 —— 就会显得很傻,好像自己既缺乏想象力,也没有记忆力。但是现实的骨感就在于:ChatGPT 发布已经有两年半了,DeepSeek 也出来不短时间了,可截至目前实际上没有任何一家正规金融机构推出结合了生成式大模型 —— 特别是推理的生成式大模型 —— 的金融服务。无论在哪个银行开户、在哪个证券公司炒股、在哪个平台买基金、在哪个地方买保险,大家可以了解一下它们的网页端或手机端有没有提供这样的服务?答案是没有,不仅在国内没有,在全世界范围内也没有。为什么?卡点在哪里?
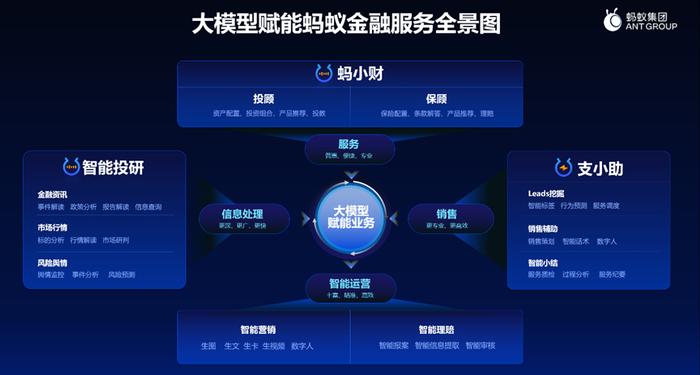
我谈一谈蚂蚁对这个事情怎么看。蚂蚁尝试在四个方向上进行实践和探索。请看这张大图。最上面的是投资顾问和保险顾问,提供 to C 的财富管理和保险规划服务。这项服务叫 “蚂小财”,其实已经有超过 8000 万的用户每个月在支付宝端内使用这个服务了。这里列出了他们咨询的主要问题类型,我就不展开讲了。这个服务是不是基于大模型?是的。有没有用到推理大模型?还没有,但 6 月底就会有,我们将上线新模型。这张图的下方(“智能运营”)是我们帮助与蚂蚁合作的金融机构,用大模型来高效地生产推广素材,比如在小红书、抖音等平台编写内容。
注意这张图的左右都是 to B 的业务。右边的 “支小助” 是为蚂蚁自己的以及合作金融机构的销售和客服人员提供智能辅助服务,让理财师、规划师等能够更高效。大家想一下,一位理财师或者规划师能够高质量服务 5000 位客户吗?哪怕在中国做得最好的财富管理机构和银行,一位理财师能提供在线服务的有效范围大概也很难超过 500 人。这就是为什么私人银行和财富管理很难下沉到普惠的人群:成本太高,太贵。一个人服务的范围有可能变大 10 倍吗?这是我们希望解决的普惠的问题。实际上,今天在线上已经基本可以实现绝大部分了。今天在支付宝的蚂蚁财富端内,超过 50% 提供给用户的服务内容是由 AI 产生并且被理财师拿来使用的。
这张图的左边,是蚂蚁结合合作的金融机构、资管机构和证券公司做 “智能投研” 的服务。如果你在资管机构工作,应该对这个印象最深刻。我们推出了 PC 端的 “蚂小财 PRO” 服务,它为金融分析师去分析资讯报表,快速地产生内容。这一部分有没有使用推理大模型?有。实际上这部分都使用了推理大模型。那为什么我们在 to B 的场景就敢用推理大模型,而 to C 就不敢呢?问题在于监管不允许吗?并不是。监管其实还是非常鼓励 AI 创新的,截至目前没有对金融领域使用 AI 有禁令。
03
大模型在 to C 金融落地时的
三大关键问题
我们觉得,要解决大模型落地 to C 金融,有三个关键的问题是我们行业的从业者不得不面对的。
第一,严不严谨?怎样控制实时性幻觉?
第二,怎样确保服务模型的可解释性。
第三,怎样防止大众策略的集中风险,比如推荐所有人都去买同一只股票或基金带来的共振。
我们认为,这三个问题中有任何一个问题不能得到有效地解决,作为一个负责任的金融服务者 —— 不管是线上还是线下,不管自称是金融机构还是金融科技机构 —— 都没有资格推出这样的 to C 服务。所以,当 DeepSeek 出来后,有一些机构说自己满血接入 DeepSeek 等等,也有人问我们为什么没有满血接入。DeepSeek 的幻觉率大家都知道,满血接入的后果就不用展开讲了。

针对这三个问题,我简单介绍一下蚂蚁的对策。第一,必须精准地控制幻觉率,要把现在市场上普遍在百分之十几以上 —— 甚至在金融领域高达百分之二三十以上 —— 的幻觉率降到个位数,降到不影响用户基本的业务决策。以技术发展之名,忽视风险,简单地推出一些技术应用,其实是非常危险的。今天蚂蚁的客户群足够大,责任也就足够大,必须考虑这个问题 —— 我们今天已经不是穿着开裆裤满街跑的小孩了。
解决的基本方法,一是建立高质量金融知识库,严格控制数据源,杜绝被污染的、非权威的数据。二是强化模型训练。不同于直接全部接入,也不同于做一些简单的提示词方面的工程强化,我们在蚂蚁自研的底座大模型和阿里的通义大模型基础上,会做非常严格的强化学习和加训,目前已经成功地将幻觉率控制在一个比较低的水平。
第二,确保专业领域的可解释性。办法很简单,就是不能把所有的问题都交给推理大模型。我们做了每个领域的大模型和小模型的对比(刚才讲的第二个阶段其实就是小模型,是可解释的,基于专业经验加上海量数据的 AI 应用),发现有些地方是大模型胜出,有些地方是小模型胜出。越是严谨的部分 —— 比如金融工程等 —— 我们会越多地使用小模型的应用。所以我们今天给 to C 用户推出的服务,就是大模型和小模型的结合。当我们严肃地给用户提供保险和理财的建议时,一定要具备可解释性。
第三,防止策略的集中度。这方面要做的既包括金融本身,也包括 AI 本身。从金融本身来说,我们要严格地控制给用户推荐的资产总量。一只基金再好,也不会把所有的用户都推到这只基金,因为它可能到了两三百亿的规模之后,就超过了阿尔法能够体现的上限了,所以首先我们会有金融层面的控量。另外在用户层面,基于大数据的 AI 会真正为用户提供千人千面的方案。每个人都不一样,且每个人在不同时刻的心理诉求也不一样 —— 有时候求稳,有时候求赚 ——AI 不会让用户涌向单一的产品。
基于这三点,我觉得大模型大概率在今年会有一些 to C 业务的落地。
04
前瞻和判断
最后分享一些目前还不成熟的思考。第一,不存在 “开箱即用”。无论是满血接入,或者是用通用人工智能 (AGI) 的方式直接接入一个底座大模型,就能解决所有的金融问题、保险问题,甚至医疗问题吗?我们觉得,在事关消费者生命财产安全的领域,不存在 “开箱即用” 的方案。我们要结合数据、知识、算力,还要结合业务流,去提供真正为用户负责的、严谨专业和可靠的金融服务。
第二,我们相信时代的趋势是不可阻挡的,但是用户的理解和接受一定是有一个过程的。AI 发展了已有 70 年,ChatGPT 的出现是在几乎 70 年之后。自动驾驶也十几年了,今天很快可能要从 L2 跨入到 L3。这都是一个从量变到质变的过程。而大模型和金融的结合其实才刚刚开始,前年、去年、今年,都有人说是元年。不管哪年是元年,我认为大模型在金融领域落地的 ChatGPT 时刻(或者说 DeepSeek 时刻,或者 L3 时刻)可能还没有到来。它需要时间的积累,积累的既是技术,也有专业知识,也有监管经验,还包括消费者对这件事的接受。就像十年前你不太敢把自己的命交给自动驾驶一样,今天你可能会有 10% 的情况会交给它,未来可能会有 20% 和 30%。我觉得金融也需要一样长 —— 甚至更长 —— 的时间,因为自动驾驶给人的反馈是非常及时的,它加速、减速、并道对不对,你立刻就能感觉到。但给你推荐一个金融产品,当你意识到它是错的时候,可能需要好些年。所以我们要有足够的耐心,随着时间一点一点做好我们该做的事情。
我就说这么多,谢谢大家。

