

特邀笔谈:人工智能对社会科学的影响
编者按:DeepSeek的出现,让大语言模型等人工智能等技术再一次成为我们的关注重点。从规范的社会科学学术研究角度,我们该如何回应和反思大语言模型等技术的影响?中国人民大学吴喜之教授将从传统统计学的局限、传统统计和机器学习的区别以及大语言模型的作用与局限性等角度予以深入剖析。《社会研究方法评论》第6卷特邀北京大学乔晓春教授、中国人民大学吴喜之教授和北京工业大学林绍福教授分别从社会科学、统计学和计算机科学的角度谈人工智能对社会科学的影响,并组成专题笔谈。本文为专题笔谈中的内容。统计、数据科学和大语言模型来源 | 社会研究方法评论第六卷
作者 | 吴喜之
作者简介:吴喜之,中国人民大学统计学院教授,研究方向为统计学、机器学习、数据科学。
模型驱动的传统统计必须转向数据驱动的机器学习,否则会被边缘化;非数据科学领域的研究者必须学会使用包括大模型在内的机器学习方法,否则迟早会被取代。本笔谈主要通过回顾传统统计在研究中的局限性,比较以模型驱动的传统统计和以数据驱动的机器学习之间的差异,提出大语言模型的应用、局限性和发展前景。
一、传统统计学的局限性
传统统计常用的线性模型包括一系列的假设,如独立同分布等,这意味着研究者借用模型对研究现象设置了一系列的统计假定。这些统计假定从数学和统计学的角度来看是没问题的,但是对应用而言则难以验证。在传统统计学中,有两个最常用但问题也最大的方面。
第一个就是统计显著性,这是传统统计最应当率先摒弃的内容。统计显著性的本质是什么?我们以 t 检验为例简单介绍一下。

国际科学界 (包括统计学界) 在积极反思被显著性统治的统计学。2019 年,多位研究者在 Nature 杂志上发表论文反对统计显著性,八百多名学者呼吁终止显著性骗人的结论并消除其带来的可能的重要影响, 他们认为有 51% 的研究中的显著性结果是错误的(Amrhein et al.,2019)。另外一篇发表在The American Statistician 上的题为《抛弃显著性》的文章呼吁研究者放弃将统计显著性作为二元的阈值,而是将其作为众多证据中的一个,结合其他统计量综合考量结果的有效性(McShane et al.,2019)。
统计模型另一个影响巨大的骗术是线性模型系数的可解释性(包括Logistic 那样的广义线性模型)。通常,其对系数的解释为“在多自变量线性回归中,某变量系数的值为其他变量不变时该变量增加一个单位时它对因变量的贡献”。值得注意的前提是,如果其他自变量可以不变,而某一个变量可以自由变动,那说明这些变量是独立的。如果这些变量是独立的,单独回归就可以得出结果,为什么需要进行多自变量回归呢?原因在于,这些自变量之间并不一定独立,人们关心它们对因变量的综合性的共同贡献。下面以一个多重回归及单变量回归的系数比较为例,数据源自波士顿房价数据。由图1 可知,单变量回归中系数最大的变量 (NOX,指一氧化氮浓度) 在多重回归中的系数为负数(系数最小),这又该如何解释呢?

实际上,没有任何方法可以证明产生数据的变量是否独立。使得单变量回归和多重回归系数相等的一个严格数学条件是:自变量矩阵 X 为正交矩阵,但这在真实数据中几乎不存在。为了便于进行数学推导,最小二乘线性回归是传统统计中首选的模型,作为回归方法,其全部内容如以下公式所示:
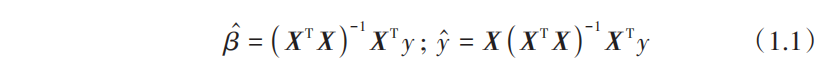
但为什么如此简单的线性回归会在社会科学的教学中成为单独一门课程呢?主要原因在于要进行各种显著性检验,以及所谓的 “线性回归的可解释性”探讨。在上百种机器学习回归模型中,最小二乘线性回归通常是预测精度较差的模型 (仅仅作为单层神经网络的一个特例),对一个预测精度不高的方法做精雕细刻的分析以及逻辑不清的显著性检验有意义吗?最小二乘线性回归 (和logistic回归) 中所谓的可解释性对其他学科 (如计量经济学、生物学、医学等) 造成了误导。机器学习回归模型具有强大而可靠的可解释性,能够替代传统回归模型。
为展示机器学习相较于传统最小二乘线性回归的可解释性,我们利用波士顿房价数据来比较两者预测的误差。
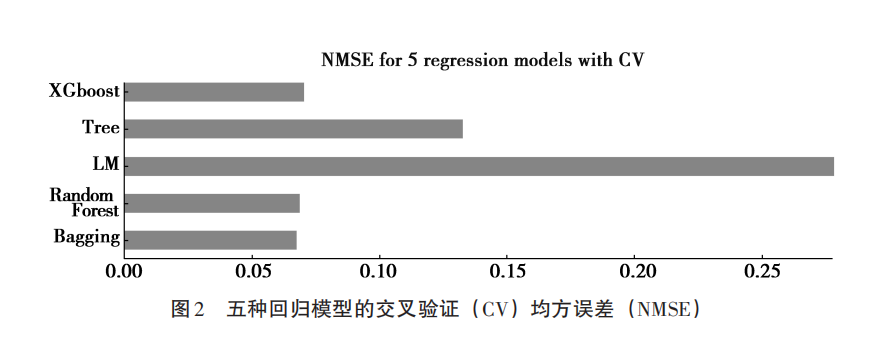
针对波士顿房价数据进行回归时,使用机器学习方法,包括 XGboost、Bagging、随机森林(Random Forest)、决策树(Tree) 等,并将其与经典回归(LM) 进行比较。图2 展示了这些方法的10 折交叉验证 (10-fold cross-validation) 的标准化均方误差 (NMSE)。在 10 折交叉验证中,整个数据集被随机分成10 个大小相等的子集,从而尽可能地利用所有可用的数据来进行训练和验证,这能给出一个很好的对模型泛化能力的估计。结果如图2 所示,经典回归的标准化均方误差最大,远远高于机器学习方法。对一个预测精度很差的传统回归模型进行各种显著性检验,并根据系数估计对变量作解释,是没有任何意义的。
二、传统统计和机器学习的区别
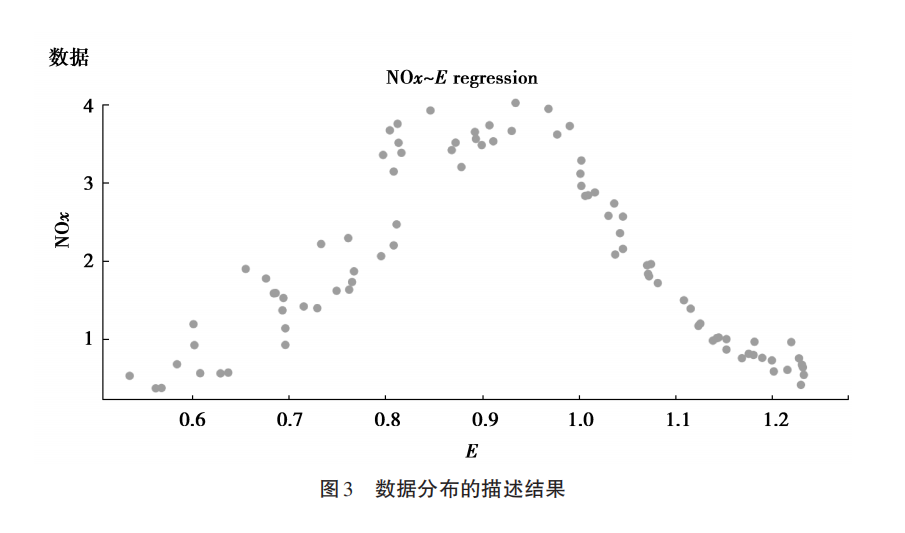
传统统计和机器学习思维的本质区别在哪?统计学家图基(Tukey) 在哲学思维上给出了出路:寻找正确问题的近似答案,而不是错误问题的精确答案。用简单的说明性例子可以解释图基的这一观点。图 3 是数据的分布图,图 4 和图 5 描述了数据驱动和模型驱动的拟合结果。图4 是使用线性回归的结果,可被称为“错误问题 (假定主观模型) 的精确解”。图 5 是决策树模型及其与线性回归的比较。决策树可被称为“正确问题(以预测为目标) 的近似解”,显然,机器学习模型远比传统的线性模型更加优越。
数据科学是世界上发展最快的领域,其核心是机器学习。大语言模型是深度学习,也是机器学习的类型之一。下面简单介绍一下机器学习的主要内容。

机器学习可被分为四类:第一类是有监督学习(如回归、分类);第二类是无监督学习 (如聚类、降维、关联规则等探索);第三类是深度学习 (各种复杂神经网络), 包括AlphaZero、AlphaFold3、大语言模型等;第四类是强化学习 (如自动驾驶、博弈等)。后两者与前两者有大量交集。从算力目标来看,前两者主要为低算力目标 (传统统计目标) 服务,而后两者主要为高算力目标服务。机器学习中应用最为广泛的是有监督学习,我们以此为例来看看数据驱动和模型驱动的数据分析两者之间的差异。

三、大语言模型的作用与局限性
大语言模型 (LLM) 旨在理解自然语言并大规模生成自然语言(这里所说的自然语言,已经延伸到艺术、舞蹈、摩尔斯电码、遗传密码、象形文字、密码学、手语、肢体语言、音乐符号、化学信号、表情符号、动物交流、触觉通信、交通标志和信号、数学方程式、编程语言等)。
LLM 从广泛的数据源中进行学习(训练),并以大量参数形式存储信息。这种学习方式和人类认识世界的方式 (死记硬背的部分)类似:阅读、观看、模仿……然而,LLM 完全依靠记忆和模仿,而人类不单是记忆,还要理解,因此,人脑不但效率更高,而且能节省大量“内存”。LLM 使用训练后的模型可根据输入进行预测并生成文本,可以参与对话、回应查询,甚至编写代码。较为领先的LLM包括GPT、LLaMa、LaMDA、PaLM 2、BERT 和 ERNIE等。
LLM 在大量数据上进行训练,学习语言的模式、结构和细微差别。然后,机器学习帮助模型根据句子前面的单词预测句子中的下一个单词。在训练中,这个过程会重复无数次,从而提升模型生成连贯且与上下文相关的文本的能力。例如,(包括了 attention 的) Transformer 架构允许模型查看并权衡句子中不同单词的重要性,类似于人类阅读句子并寻找上下文线索来理解其含义。
虽然LLM 可以生成原创内容,但其质量、相关性和创新性不可靠,需要进行人工干预。原创性还受到提示的结构、模型的训练数据以及相关LLM 的特定功能的影响。值得注意的是,LLM 和符号计算系统 (像骨灰级的 Wolfram Alpha, Maplesoft, Mathematica) 或其他深度学习模型 (如Alpha Go,Alpha Zero,AlphaFold3 等) 存在差异 (这些属于专家,而LLM 是杂家)。LLM 表现出令人惊叹的直觉 (intuition),但其智能 (intelligence) 水平有限。它可以回答几乎所有可以通过单次直觉回答的问题。LLM 也会出现“目标漂移”现象,随着步骤的增多和上下文内容的增加,整个系统会开始出错。即使存在之前的对话历史记录,LLM 也在什么是关注点及真实目标上犯糊涂,attention 经常不够精确。
LLM 常用的功能包括以下内容:自动代码生成,即根据自然语言描述生成代码片段、函数甚至整个模块,节省时间和精力 (代码可能难懂、效率低、无法核对和修改);文本生成,即根据提示生成连贯的文本,包括文章、故事、产品描述等 (可能古怪、不合逻辑或强调某种“政治正确”);内容摘要 (领导秘书的法宝);语言翻译 (对与西方语言之间的互译较为友好);代码错误检测和纠正(码农福音);释义和重写,即重新措辞或重写文本,同时保持原始含义 (对于剽窃有一定作用,但其质量往往不高);虚拟指导/聊天机器人 (可能会对孩子的认知发展产生不良影响,但可用于安慰孤独人群,智力障碍、阿尔茨海默病人群);情感分析 (应用于品牌声誉管理和客户反馈分析);内容过滤和审核 (识别和过滤在线内容)。
LLM 也有局限性:语言模型的技术限制,即技术限制会影响其准确性和上下文理解 (虽一直在改进,但不可能达到完美);领域不匹配,即因缺乏某些领域的详细数据而难以处理特定或小众主题,导致在处理专业知识时不准确或过于笼统 (普遍现象);单词预测问题,即不太常见的单词或短语会影响其完全理解或准确生成涉及这些术语的文本的能力 (生成劣质产品);实时翻译效率问题,即搜索内存记忆中的东西速度很慢,尤其是对于具有复杂语法结构或在训练数据中代表性较低的语言而言 (不会用另一种语言思考,如同背单词的后遗症);幻觉和偏见,即LLM 在技术原创性方面存在问题,以至于容易出现胡编滥造的情况,也可能传播和放大其训练数据中存在的偏见,导致输出可能带有歧视性或冒犯性 (可以把谣言和政治不正确赖在LLM 身上);可扩展性和环境影响,即训练、维护和使用太耗电, 并且能力越强, 该问题越严重 (非常不环保!)。
LLM 暂时还无法完成以下内容:不能体验情感,LLM 缺乏自我意识以及感受快乐、悲伤或任何其他情感的能力 (只能模仿);不能理解训练数据之外的背景 (无创新能力,只能胡编滥造);不能进行自主决策 (有所有人共同认可的是非观吗?政治正确依编程者而定);不能访问实时信息 (训练数据都是历史);不能执行物理任务 (需要机器人);不能创造真正的艺术 (只会模仿);不能了解深层个人背景 (只能基于模式或标签);不能展现真正的创造力;不能超越模式识别(只会套路,不能原创);不能保证隐私和安全(你提的问题会被保存;“小度”是不是信息员?);不能理解抽象概念,即LLM 难以理解没有明确定义或高度主观的抽象概念(较为浅薄);不能参与身体感觉与世界的互动,仅限于文本输入和输出;缺乏人类所依赖的感官体验的深度 (哪个新兵能用语言真实描述看到一个战友被炮弹击中时的感觉?)。
* 本文根据吴喜之教授在“人工智能(AI) 对社会科学的影响及在社会科学领域的应用”学术研讨会上的主旨发言整理而来,由吴喜之教授审定。
*为阅读和排版的便利,本文删去参考文献,敬请有需要的读者阅读原文。《社会研究方法评论》第6卷纸刊已上线各大购物平台,电子版将后续在中国知网上传。

