公众号关注 “ML_NLP”设为 “星标”,重磅干货,第一时间送达!

转载自|PaperWeekly
©PaperWeekly 原创 · 作者|王东伟
单位|致趣百川
研究方向|深度学习
本文介绍正则化(regularization)。
神经网络模型通过最小化误差得到最优参数,其误差函数具有如下形式: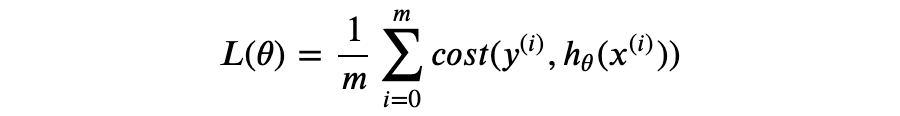
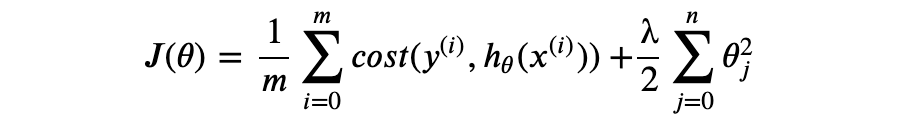
以下通过一个简单的实验说明正则化的作用。
对直线 y=x 进行等间距采样,并且加入随机噪声,得到 10 个数据样本如下: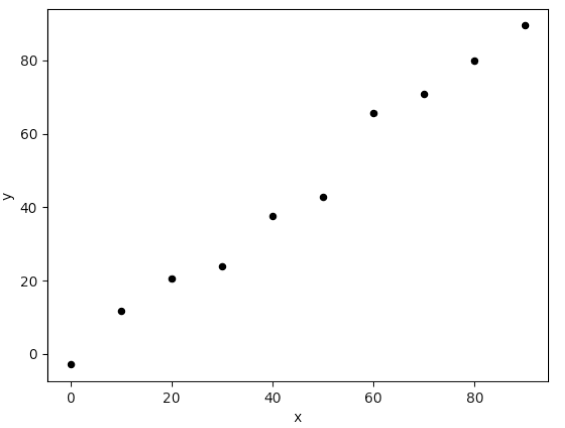
▲ 图1
采用以 Sigmoid 为激活函数的 2 层神级网络模型拟合训练数据,图 2.1、2.2 分别为 λ=0、λ=0.5 的模型拟合结果: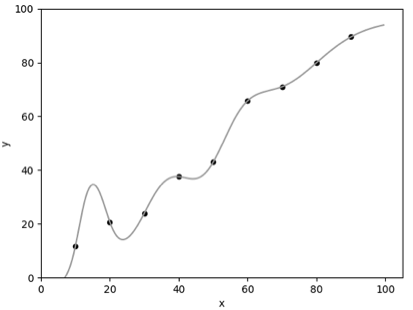
▲ 图2.1 λ=0
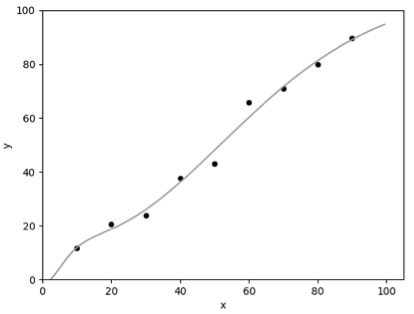
▲ 图2.1 λ=0.5
可以看到,通过正则化(即 λ>0),我们得到了更符合预期的模型。假如没有正则化(即 λ=0),模型唯一的目标是尽可能降低误差,因此在训练数据较少的情况下,模型将有可能完美拟合带噪声的训练数据(即误差为零),这就是过拟合。正则化可以在一定程度上抑制过拟合,让模型获得抗噪声的能力,这将提升模型对未知样本的预测性能。 贝叶斯线性回归与正则化考虑线性回归问题,我们定义 为真实值, 为测量值。假如真实值满足 ,由于测量仪器、环境等因素的影响,往往我们得到的数据会引入噪声,于是我们可以假设:
贝叶斯线性回归与正则化考虑线性回归问题,我们定义 为真实值, 为测量值。假如真实值满足 ,由于测量仪器、环境等因素的影响,往往我们得到的数据会引入噪声,于是我们可以假设:
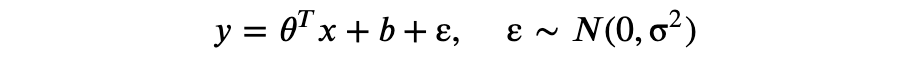
以上即为贝叶斯线性回归模型,其中 ε 服从正态分布(中心极限定理告诉我们这是一个合理的假设,你可以自行了解)。
上述假设可以理解为:给定 ,σ。也就是: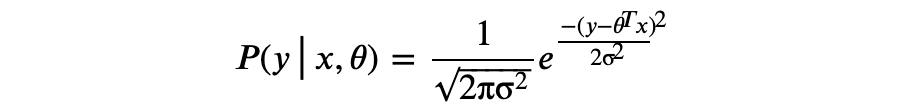
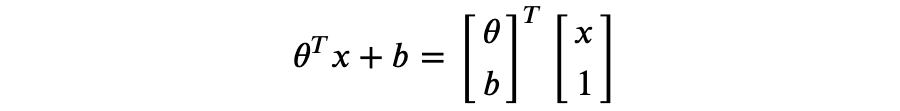
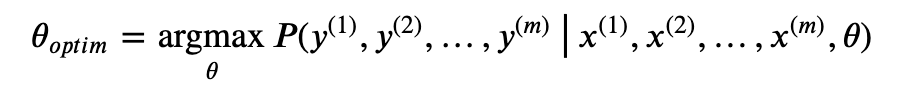
以上称为极大似然估计(Maximum Likelihood Estimate,MLE)。
进一步,我们假设各个数据样本测量统计独立,则有:
可以看到,MLE 的优化目标与神经网络模型的最小平方误差具有相同形式。
接下来,我们从另一个角度考虑上述线性回归的优化问题。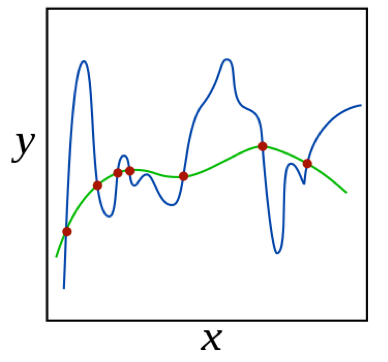
▲ 图3 source: wikipedia
图 3 所示,蓝色和绿色曲线都可以拟合数据点,我们可以把拟合数据点的曲线视为函数集合或者函数空间,问题是应该选择哪条曲线?
既然拟合数据的曲线是不确定的,我们可以将曲线的参数 视为随机变量,并且进一步地假定 θ 符合特定的先验概率分布。其中一个合理的假定是高斯分布 τ, 为单位矩阵,即: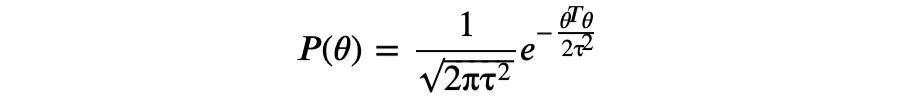
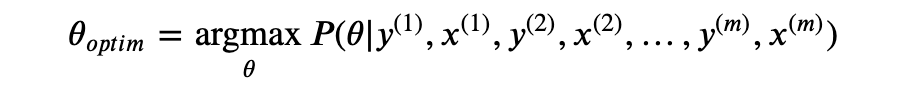
以上为最大后验估计(Maximum A Posteriori Estimate, MAP)。
由贝叶斯定理得到: 其中,λστ。
其中,λστ。
可以看到 MAP 的优化目标与开篇引入正则化的目标函数有相同的形式。
从贝叶斯线性回归的角度,正则化通过给出参数的先验概率分布假设,并由最大化后验概率求得最优参数。直观地讲,正则化自动选择了先验假设下最“合理”的参数。使用高斯分布作为先验和 MAP 优化的贝叶斯线性回归相当于“岭回归”(ridge regression),λ 对应 L2 正则化( 表示 p- 范数)。我们还可以使用拉普拉斯分布(Laplace distribution)作为先验,此时将得到 λ,对应 L1 正则化。L1 正则化的主要特性是可以得到稀疏解(即部分 为零),也就是说, L1 有特征选择的效果。如果特征维数很大(比如 1 亿维),L1 正则化将可以提升模型推理阶段的内存开销,参阅 [Regularization for Sparsity: L₁ Regularization]。
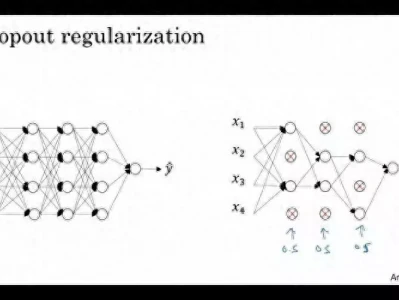
Dropout
除了 L2 和 L1 正则化,Dropout 也可以防止模型过拟合。 ▲ 图4 source: Dropout 2014年论文
▲ 图4 source: Dropout 2014年论文
图 3 展示了 Dropout 的算法原理。在模型训练阶段,每一个隐藏层神经元以概率 1-p 不被激活(也就是神经元输出置零)。在测试阶段,神经元不作 Dropout 处理,但是输出值乘以 p,这是为了保持测试阶段与训练阶段的隐藏层输出期望值不变。实验显示 p=0.5 在很多类型的神经网络模型和任务中为最优值。
论文中还指出 Dropout 具有“模型组合”(model combination)的作用,理由是,每一层 n 个神经元的网络经过 Dropout 都会产生 个可能的子网络,所以加入 Dropout 操作的神经网络模型训练,实际上同时训练了多个不同的共享大部分参数的模型,而在测试阶段,则相当于使用了多个模型的预测结果。以 Python 为例,加入 Dropout 的训练阶段前向传播有如下形式(@ 为 numpy 类型的矩阵乘积运算):
h1 = x @ w1 + b1
h1 = np.maximum(h1, 0) # ReLU作为激活函数drop = np.random.rand(*h1.shape) < p # p为神经元激活的概率h1 = h1 * drop
h2 = h1 @ w2 + b2
h2 = np.maximum(h2, 0)
drop = np.random.rand(*h2.shape) < p
h2 = h2 * drop
out = h2 @ w3 + b3
在测试阶段:h1 = np.maximum(x @ w1 + b1, 0) * p
h2 = np.maximum(h1 @ w2 + b2, 0) * p
out= h2 @ w3 + b3
由于测试阶段的乘数 p 仅仅是为了达到输出期望的一致性,因此我们可以通过在训练阶段作缩放操作达到同样的目的,调整上述代码得到:
h1 = x @ w1 + b1
h1 = np.maximum(h1, 0)
drop = (np.random.rand(*h1.shape) < p) / p # 缩放操作h1 = h1 * drop
h2 = h1 @ w2 + b2
h2 = np.maximum(h2, 0)
drop = (np.random.rand(*h2.shape) < p) / p
h2 = h2 * drop
out = h2 @ w3 + b3
测试阶段的代码调整为:h1 = np.maximum(x @ w1 + b1, 0)
h2 = np.maximum(h1 @ w2 + b2, 0)
out= h2 @ w3 + b3
现在,测试阶段保留了原有的模型结构,超参数 p 仅作用于训练阶段。通常我们更倾向于后一种实现方式,称为 inverted dropout。
Dropout 最早的论文发表于 2012 年 [Improving neural networks by preventing co-adaptation of feature detectors. G. E. Hinton. University of Toronto. 2012.],随后 2013 年的另一篇论文探讨了 Dropout 与 L2 正则化的联系 [Dropout Training as Adaptive Regularization. Stefan Wager. Stanford University. 2013.],还有 2014 年 Dropout 论文 [Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Nitish Srivastava. University of Toronto. 2014.]。
本文关于 MLE 和 MAP 的推导部分参考了康奈尔大学的 CS 课程 [Linear Regression. Cornell University. 2018.] 。
参考文献
[1] Improving neural networks by preventing co-adaptation of feature detectors. G. E. Hinton. University of Toronto. 2012. [2] Dropout Training as Adaptive Regularization. Stefan Wager. Stanford University. 2013. [3] Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Nitish Srivastava. University of Toronto. 2014. [4] Linear Regression. Cornell University. 2018. [5] 贝叶斯线性回归. 百度百科. [6] Neural Networks Part 2: Setting up the Data and the Loss. Stanford University. 2020. [7] Regularization for Sparsity: L₁ Regularization. 2020.
下载1:四件套
在机器学习算法与自然语言处理公众号后台回复“四件套”,
即可获取学习TensorFlow,Pytorch,机器学习,深度学习四件套!

下载2:仓库地址共享
在机器学习算法与自然语言处理公众号后台回复“代码”,
即可获取195篇NAACL+295篇ACL2019有代码开源的论文。开源地址如下:https://github.com/yizhen20133868/NLP-Conferences-Code
重磅!机器学习算法与自然语言处理交流群已正式成立!
群内有大量资源,欢迎大家进群学习!
额外赠送福利资源!深度学习与神经网络,pytorch官方中文教程,利用Python进行数据分析,机器学习学习笔记,pandas官方文档中文版,effective java(中文版)等20项福利资源

获取方式:进入群后点开群公告即可领取下载链接
注意:请大家添加时修改备注为 [学校/公司 + 姓名 + 方向]
例如 —— 哈工大+张三+对话系统。
号主,微商请自觉绕道。谢谢!

 fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
推荐阅读:
Tensorflow 的 NCE-Loss 的实现和 word2vec
awesome-adversarial-machine-learning资源列表