
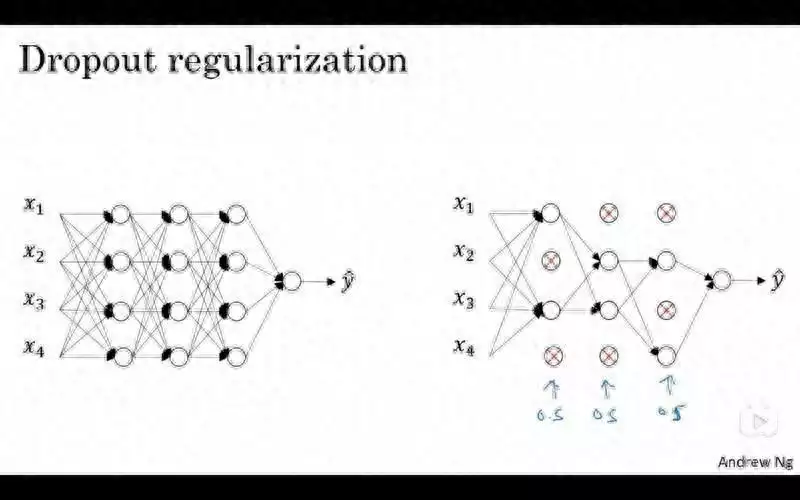
Dropout正则化是一种用于防止神经网络过拟合的技术,它的基本思想是在训练过程中随机丢弃一些神经元,从而减少神经元之间的依赖和共适应,增强神经网络的泛化能力。Dropout正则化可以看作是一种随机集成的方法,它相当于训练了多个不同的子网络,并在测试时对它们进行平均。Dropout正则化可以有效地缓解模型的过拟合问题,提高模型的性能和稳定性。
Dropout正则化的具体做法是,在每次训练迭代中,对每一层的神经元设置一个保留概率p,然后根据p生成一个伯努利分布的随机向量d,将d与该层的激活值a相乘,得到dropout后的激活值a’。这样,该层的一些神经元就被随机地置为0,相当于从网络中移除。为了保持网络输出的期望不变,还需要对a’进行缩放,即除以p。在测试时,不使用dropout,而是直接使用原始的激活值a。
Dropout正则化的数学原理是,通过随机丢弃一些神经元,可以减少神经元之间的协方差,并增加每个神经元的方差。这样可以使得每个神经元更加独立地提取特征,而不是依赖于其他神经元。同时,Dropout正则化也可以看作是对网络权重进行了约束,相当于在损失函数中加入了一个正则项,从而防止权重过大或过小。

