
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在官网-聚客AI学院大模型应用开发微调项目实践课程学习平台
一、Transformer革命性架构全景解析
1.1 整体架构设计
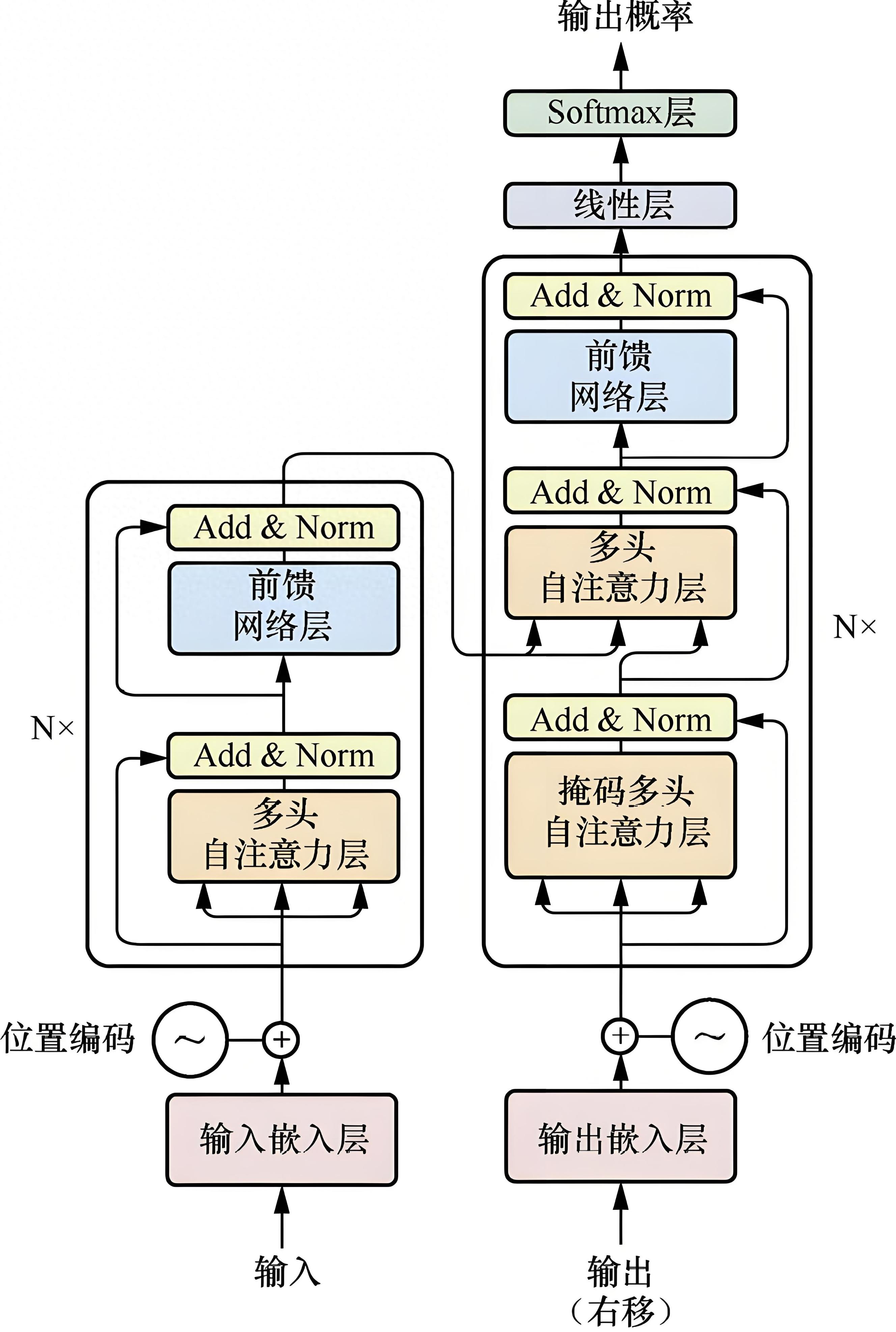
数学表达:
输出=Decoder(Encoder(X),Y)
代码实现框架:
class Transformer(nn.Module): def __init__(self, num_layers=6, d_model=512): super().__init__() self.encoder = Encoder(num_layers, d_model) self.decoder = Decoder(num_layers, d_model) def forward(self, src, tgt): memory = self.encoder(src) output = self.decoder(tgt, memory) return output二、编码器核心组件深度剖析
2.1 自注意力机制数学本质
计算过程:

多头注意力实现:
class MultiHeadAttention(nn.Module): def __init__(self, d_model=512, num_heads=8): super().__init__() self.d_k = d_model // num_heads self.W_q = nn.Linear(d_model, d_model) self.W_k = nn.Linear(d_model, d_model) self.W_v = nn.Linear(d_model, d_model) self.W_o = nn.Linear(d_model, d_model) def forward(self, q, k, v, mask=None): # 拆分为多头 q = self.W_q(q).view(batch, -1, self.num_heads, self.d_k) k = self.W_k(k).view(batch, -1, self.num_heads, self.d_k) v = self.W_v(v).view(batch, -1, self.num_heads, self.d_k) # 计算注意力 scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k) if mask is not None: scores = scores.masked_fill(mask == 0, -1e9) weights = F.softmax(scores, dim=-1) # 合并多头 output = torch.matmul(weights, v).transpose(1,2).contiguous() return self.W_o(output.view(batch, -1, d_model))2.2 前馈神经网络设计
结构特征:
FFN(x)=ReLU(xW1+b1)W2+b2
代码实现:
class PositionwiseFFN(nn.Module): def __init__(self, d_model=512, d_ff=2048): super().__init__() self.linear1 = nn.Linear(d_model, d_ff) self.linear2 = nn.Linear(d_ff, d_model) def forward(self, x): return self.linear2(F.relu(self.linear1(x)))2.3 编码器层完整实现
class EncoderLayer(nn.Module): def __init__(self, d_model=512, num_heads=8, d_ff=2048): super().__init__() self.self_attn = MultiHeadAttention(d_model, num_heads) self.ffn = PositionwiseFFN(d_model, d_ff) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) def forward(self, x, mask=None): # 残差连接+层归一化 x = self.norm1(x + self.self_attn(x, x, x, mask)) x = self.norm2(x + self.ffn(x)) return x三、解码器架构关键技术解密
3.1 掩码自注意力机制
掩码原理:
数学表达:
代码实现:
def generate_causal_mask(sz): mask = torch.triu(torch.ones(sz, sz) == 1 return mask.float().masked_fill(mask == 0, float(-inf))3.2 编码器-解码器注意力
跨模态注意力机制:
class DecoderLayer(nn.Module): def __init__(self, d_model=512, num_heads=8, d_ff=2048): super().__init__() self.self_attn = MultiHeadAttention(d_model, num_heads) self.cross_attn = MultiHeadAttention(d_model, num_heads) self.ffn = PositionwiseFFN(d_model, d_ff) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) def forward(self, x, memory, src_mask=None, tgt_mask=None): # 自注意力(带掩码) x = self.norm1(x + self.self_attn(x, x, x, tgt_mask)) # 跨注意力 x = self.norm2(x + self.cross_attn(x, memory, memory, src_mask)) x = self.norm3(x + self.ffn(x)) return x3.3 解码器工作流程
推理阶段步骤:
初始化输入为<sos>
自回归生成每个token
直到生成<eos>或达到最大长度
代码示例:
def decode(self, memory, max_len=50): batch = memory.size(0) outputs = torch.zeros(batch, max_len).long() next_token = torch.full((batch,1), SOS_IDX) for t in range(max_len): dec_out = self.decoder(next_token, memory) logits = self.generator(dec_out[:, -1]) next_word = logits.argmax(-1) outputs[:, t] = next_word next_token = torch.cat([next_token, next_word.unsqueeze(1)], dim=1) return outputs四、关键组件创新解析
4.1 位置编码技术演进
原始正弦编码:
相对位置编码实现:
class RotaryPositionEmbedding(nn.Module): def __init__(self, dim): super().__init__() inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim)) self.register_buffer("inv_freq", inv_freq) def forward(self, seq_len): t = torch.arange(seq_len, device=self.inv_freq.device) freqs = torch.einsum(i,j->ij, t, self.inv_freq) return torch.cat([freqs, freqs], dim=-1)4.2 残差连接与层归一化
数学表达式:
梯度流动分析:
# 梯度检查 x = torch.randn(3, 512, requires_grad=True) y = x + F.relu(x) # 梯度可直通五、工业级优化实践
5.1 内存优化技巧
分块注意力实现:
def block_attention(q, k, v, block_size=64): batch, seq_len, _ = q.size() num_blocks = seq_len // block_size outputs = [] for i in range(num_blocks): q_block = q[:, i*block_size:(i+1)*block_size] k_block = k[:, i*block_size:(i+1)*block_size] attn = torch.softmax(q_block @ k_block.transpose(-2,-1), dim=-1) outputs.append(attn @ v[:, i*block_size:(i+1)*block_size]) return torch.cat(outputs, dim=1)5.2 混合精度训练
from torch.cuda.amp import autocast with autocast(): output = model(src, tgt) loss = criterion(output, target)5.3 分布式训练配置
# 使用Deepspeed零冗余优化器 engine, optimizer, _, _ = deepspeed.initialize( model=model, model_parameters=model.parameters(), config=deepspeed_config )注:文中代码经过简化处理,实际生产环境需添加异常处理与日志模块。如果本次分享对你有所帮助,记得告诉身边有需要的朋友,"我们正在经历的不仅是技术迭代,而是认知革命。当人类智慧与机器智能形成共生关系,文明的火种将在新的维度延续。"在这场波澜壮阔的文明跃迁中,主动拥抱AI时代,就是掌握打开新纪元之门的密钥,让每个人都能在智能化的星辰大海中,找到属于自己的航向。
